Survey
* Your assessment is very important for improving the workof artificial intelligence, which forms the content of this project
22S6 - Numerical and data analysis
techniques
Mike Peardon
School of Mathematics
Trinity College Dublin
Hilary Term 2012
Mike Peardon (TCD)
22S6 - Data analysis
Hilary Term 2012
1 / 14
Sampling
Mike Peardon (TCD)
22S6 - Data analysis
Hilary Term 2012
2 / 14
Sample mean
Sample mean
For a sequence of n random numbers, {X1 , X2 , X3 , . . . Xn }. The
sample mean is
n
1X
X̄(n) =
Xi
n i=1
X̄(n) is also a random number.
If all entries have the same mean, μX then
E[X̄(n) ] =
n
1X
n i=1
E[Xi ] = μX
If all entries are independent and identically distributed
then
1
σX̄2(n) = σX2
n
Mike Peardon (TCD)
22S6 - Data analysis
Hilary Term 2012
3 / 14
The law of large numbers
Jakob Bernoulli: “Even the stupidest man — by some
instinct of nature per se and by no previous instruction
(this is truly amazing) — knows for sure the the more
observations that are taken, the less the danger will be of
straying from the mark”(Ars Conjectandi - 1713).
But the strong law of large numbers was only proved in
the 20th century (Kolmogorov, Chebyshev, Markov, Borel,
Cantelli, . . . ).
The strong law of large numbers
If X̄(n) is the sample mean of n independent, identically
distributed random numbers with well-defined expected value
μX and variance, then X̄(n) converges almost surely to μX .
P( lim X̄(n) = μX ) = 1
n→∞
Mike Peardon (TCD)
22S6 - Data analysis
Hilary Term 2012
4 / 14
Example: exponential random numbers
X
0.299921
1.539283
1.084130
1.129681
0.001301
1.238275
4.597920
0.679552
0.528081
1.275064
0.873661
1.018920
0.980259
1.115647
1.664513
0.340858
X̄(2)
X̄(4)
X̄(8)
X̄(16)
0.919602
1.013254
1.106906
1.321258
0.619788
1.629262
2.638736
1.147942
0.901572
0.923931
0.946290
0.974625
1.047953
1.025319
1.002685
Mike Peardon (TCD)
22S6 - Data analysis
Hilary Term 2012
5 / 14
The central limit theorem
As the sample size n grows, the sample mean looks more
and more like a normally distributed p
random number with
mean μX and standard deviation σX / n
The central limit theorem (de Moivre, Laplace,
Lyapunov,. . . )
The sample mean of n independent, identically distributed
random numbers, each drawn from a distribution with
expected value μX and standard deviation σX obeys
Za
−aσ
+aσ
1
2
(n)
lim P( p < X̄ − μX < p ) = p
e−x / 2 dx
n→∞
n
n
2π −a
Mike Peardon (TCD)
22S6 - Data analysis
Hilary Term 2012
6 / 14
The central limit theorem (2)
The law of large numbers tells us we can find the
expected value of a random number by repeated
sampling
The central limit theorem tells us how to estimate the
uncertainty in our determination when we use a finite (but
large) sampling.
The uncertainty falls with increasing sample size like
Mike Peardon (TCD)
22S6 - Data analysis
Hilary Term 2012
1
p
n
7 / 14
The central limit theorem
An example: means of bigger sample averages of a
random number X with n = 1, 2, 5, 50
14
14
12
12
n=1
10
8
6
6
4
4
2
2
0
0
0.2 0.4 0.6 0.8
1
14
0
0.2 0.4 0.6 0.8
1
12
n=5
10
8
6
6
4
4
2
2
0
n=50
10
8
Mike Peardon (TCD)
0
14
12
0
n=2
10
8
0.2 0.4 0.6 0.8
1
0
0
0.2 0.4 0.6 0.8
22S6 - Data analysis
1
Hilary Term 2012
8 / 14
Confidence intervals
The central limit theorem tells us that for sufficiently large
sample sizes, all sample means are normally distributed.
We can use this to estimate probabilities that the true
expected value of a random number lies in a range.
One sigma
What is the probability a sample
mean X̄ is more than one
p
standard deviation σX̄ = σX / n from the expected value μX ? If
n is large, we have
1
P(−σX̄ < X̄ − μX < σX̄ ) = p
2π
1
Z
e−x
2/ 2
dx = 68.3%
−1
These ranges define confidence intervals .
Most commonly seen are the 95% and 99% intervals
Mike Peardon (TCD)
22S6 - Data analysis
Hilary Term 2012
9 / 14
Confidence intervals (2)
Most commonly seen are the 95%(2σ) and 99%(3σ)
intervals.
P −σX̄
P −2σX̄
P −3σX̄
P −4σX̄
P −5σX̄
P −10σX̄
< X̄ − μX
< X̄ − μX
< X̄ − μX
< X̄ − μX
< X̄ − μX
< X̄ − μX
< σX̄
< 2σX̄
< 3σX̄
< 4σX̄
< 5σX̄
< 10σX̄
68.2%
95.4%
99.7%
99.994%
99.99994%
99.9999999999999999999985%
The standard deviation is usually measured from the
sample variance.
Beware - the “variance of the variance” is usually large.
Five-sigma events have been known ...
Mike Peardon (TCD)
22S6 - Data analysis
Hilary Term 2012
10 / 14
Sample variance
With data alone, we need a way to estimate the variance
of a distribution. This can be estimated by measuring the
sample variance:
Sample variance
For n > 1 independent, identically distributed samples of a
random number X, with sample mean X̄, the sample
variance is
n
1 X
σ̄X2 =
(Xi − X̄)2
n − 1 i=1
Now we quantify fluctuations without reference to (or
without knowing) the expected value, μX .
Note the n − 1 factor. One “degree of freedom” is
absorbed into “guessing” the expected value of X
Mike Peardon (TCD)
22S6 - Data analysis
Hilary Term 2012
11 / 14
Student’s t-distribution
In 1908, William Gosset, while working for Guinness in
St.James’ Gate published under the pseudonym “Student”
Computes the scaling to define a confidence interval
when the variance and mean of the underlying
distribution are unknown and have been estimated
Student’s t-distribution
fT (t) = p
Γ( 2n )
π(n − 1)Γ( n−1
)
2
t2
1+
−n/ 2
n−1
Used to find the scaling factor c(γ, n) to compute the γ
confidence interval for the sample mean
P(−cσ̄ < μX < cσ̄) = γ
For n > 10, the t-distribution looks very similar to the
normal distribution
Mike Peardon (TCD)
22S6 - Data analysis
Hilary Term 2012
12 / 14
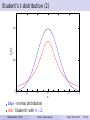
Student’s t-distribution (2)
fX(x)
0.4
0.2
0
-3
-2
-1
0
x
1
2
3
blue - normal distribution
red - Student t with n = 2.
Mike Peardon (TCD)
22S6 - Data analysis
Hilary Term 2012
13 / 14
Student’s t-distribution (3)
For example, with just 2 samples, the sample mean and
variance can be computed but now the confidence levels
are:
P −σ̄X < X̄ − μX < σ̄X
50%
P −2σ̄X < X̄ − μX < 2σ̄X
70.5%
P −3σ̄X < X̄ − μX < 3σ̄X
79.5%
P −4σ̄X < X̄ − μX < 4σ̄X
84.4%
P −5σ̄X < X̄ − μX < 5σ̄X 87.4%
P −10σ̄X < X̄ − μX < 10σ̄X
93.7%
“Confidences” are much lower because variance is very
poorly determined with only two samples.
Mike Peardon (TCD)
22S6 - Data analysis
Hilary Term 2012
14 / 14