Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
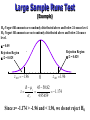
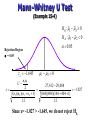
Introduction to Nonparametric Statistics Nonparametric Tests • Nonparametric tests are sometimes called distribution-free tests because they are based on fewer assumptions (e.g., they do not assume that the outcome is approximately normally distributed). • Parametric tests involve specific probability distributions (e.g., the normal distribution) and the tests involve estimation of the key parameters of that distribution (e.g., the mean or difference in means) from the sample data. • Non-parametric tests are typically focused on the median (rather than on the mean) and involve fairly straight-forward procedures like ordering and counting. • The cost of fewer assumptions is that nonparametric tests are generally less powerful than their parametric counterparts (i.e., when the alternative is true, they may be less likely to reject H0). • There are situations, particularly in psychological or in market research studies, where in the basic assumptions underlying the parametric tests are not valid or one does not have the knowledge of the distribution of the population parameter being tested. • The most practical approach to assessing normality involves investigating the distributional form of the outcome in the sample using a histogram. • There are some situations when it is clear that the outcome does not follow a normal distribution. These include situations: – when the outcome is an ordinal variable or a rank, – when there are definite outliers or – when the outcome has clear limits of detection. • The following are some of the typical situations for using nonparametric tests: i) In a consumer behaviour survey for new package design, the response are not likely to be normally distributed but clustering around two extreme positions, with a very few respondents giving a neutral response to the package design. ii) Sometimes, the responses to a question are given in terms of names (nominal data), which cannot be treated as numbers. For example, if we ask young graduates “in which part of the country would you like to take up a job and live”, the replies could be north, north-west, west or south, etc. Nominal data can be analysed only by nonparametric methods. iii) In mailed questionnaire method of survey, more often partially filled missions data and make necessary adjustments to extract maximum information form the available data. iv) Nonparametric tests can be used to provide reasonably good results even for very small samples. Measurements or oberrvations for use of non-parametric Statistics • Using an Ordinal Scale Consider a field demonstration where study participants are asked to rate the effectiveness of training on the assigned topic of interest. Training rating might be measured on a 5 point ordinal scale with response options: much worse, slightly worse, no change, slightly effective, or much effective. • When the Outcome is a Rank In some studies, the outcome is a rank. For example, in organoleptic studies score is often used to assess the quality of the product. These scores generally do not follow a normal distribution. • When There Are Outliers In some studies, the outcome is continuous but subject to outliers or extreme values. • Limits of Detection In some studies, the outcome is a continuous variable that is measured with some imprecision (e.g., with clear limits of detection). For example, some instruments or assays cannot measure presence of specific quantities above or below certain limits. In social sciences some measurement never go below or above certain values. Ex. Scientific equipments, Age of farmer, etc. Test Parametric Non Parametric One Quantitative Response Variable One Sample ttest Sign Test One Quantitative Response Variable – Two Values from Paired Samples Paired Sample t- Wilcoxon Signed test Rank Test One Quantitative Response Variable – One Qualitative Independent Variable with two groups Two Independent Sample t-test Wilcoxon Rank Sum or Mann Whitney Test One Quantitative Response Variable – One Qualitative Independent Variable with three or more groups ANOVA Kruskall Wallis Runs Test for Detecting Non-randomness • The runs test suggested by Bradley(1968) can be used to decide if a data set is from a random process. • A run is defined as a series of increasing values or a series of decreasing values. The number of increasing, or decreasing, values is the length of the run. • In a random data set, the probability that the (I+1)th value is larger or smaller than the Ith value follows a binomial distribution, which forms the basis of the runs test. • The first step in the runs test is to count the number of runs in the data sequence. For example, a series of 20 coin tosses might produce the following sequence of heads (H) and tails (T). HHTTHTHHHHTHHTTTTTHH The number of runs for this series is nine. There are 11 heads and 9 tails in the sequence. Runs Test • We will code values above the median as positive and values below the median as negative. A run is defined as a series of consecutive positive (or negative) values. • Hypothesis for runs test is defined as: H0: the sequence was produced in a random manner H1: the sequence was not produced in a random manner • R r Test Statistic:The test statistic is Z where 2n1n2 r 1 n1 n2 r (2n1n2 )( 2n1n2 n1 n2 ) r (n1 n2 ) 2 (n1 n2 1) R is the observed number of runs n1 = Number of occurrences of first type(Positive) n2 = Number of occurrences of second type(Negative) The runs test rejects the null hypothesis If |Z| > Z1-α/2 Runs Test • For a large-sample runs test (where n1 > 10 andn2 > 10), the test statistic is compared to a standard normal table. That is, at the 5 % significance level, a test statistic with an absolute value greater than 1.96 indicates non-randomness. • For a small-sample runs test, there are tables to determine critical values that depend on values of n1 and n2 The Runs Test (Small Sample Example) Sequence 1 2 3 4 5 6 7 8 9 10 Number 0.34561 0.42789 0.36925 0.89563 0.25679 0.92001 0.58345 0.23114 0.12672 0.88569 Code + + + + Sequence Number 11 0.67201 12 0.23790 13 0.24509 14 0.01467 15 0.78345 16 0.69112 17 0.46023 18 0.38633 19 0.60914 20 0.95234 Code + + + + + The Runs Test (Small Sample Example) H0: Computer-generated numbers are random between 0.0 and 1.0. HA: Computer-generated numbers are not random . --- + - ++ -- ++ --- ++ -- ++ Runs: 1 2 3 4 5 6 7 8 9 10 There are r = 10 runs From runs table (Appendix K) with n1 = 9 and n2 = 11, the critical value of r is 6 The Runs Test (Small Sample Example) Test Statistic: R= 10 runs Critical Values from Runs Table: Possible Runs: 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 Reject H0 Do not reject H0 Reject H0 Decision: Since R = 10, we do not reject the null hypothesis. Large Sample Runs Test MEAN AND STANDARD DEVIATION FOR r 2n1n2 r 1 n1 n2 (2n1n2 )( 2n1n2 n1 n2 ) r 2 (n1 n2 ) (n1 n2 1) where: n1 = Number of occurrences of first type n2 = Number of occurrences of second type Large Sample Runs Test TEST STATISTIC FOR LARGE SAMPLE RUNS TEST z R r r Large Sample Runs Test (Example ) OOOUOOUOUUOOUUOOOOUUOUUOOO UUUOOOOUUOOUUUOUUOOUUUUU OOOUOUUOOOUOOOOUUUOUUOOOU OOUUOUOOUUUOUUOOOOUUUOOO n1 = 53 “O’s” n2 = 47 “U’s” r = 45 runs Large Sample Runs Test (Example) H0: Yogurt fill amounts are randomly distributed above and below 24-ounce level. H1: Yogurt fill amounts are not randomly distributed above and below 24-ounce level. = 0.05 Rejection Region /2 = 0.025 Rejection Region /2 = 0.025 z.025 1.96 z R r r 0 z.025 1.96 45 50.82 1.174 4.95659 Since z= -1.174 > -1.96 and < 1.96, we do not reject H0, Mann-Whitney U Test The Mann Whitney U test can be used to compare two samples from two populations if the following assumptions are satisfied: • The two samples are independent and random. • The value measured is a continuous variable. • The measurement scale used is at least ordinal. • If they differ, the distributions of the two populations will differ only with respect to the central location. Mann-Whitney U Test U-STATISTICS n1 (n1 1) U1 n1n2 R1 2 n2 (n2 1) U 2 n1n2 R2 2 where: n1 and n2 are the two sample sizes R1 and R2 = Sum of ranks for samples 1 and 2 Mann-Whitney U Test - Large Samples MEAN AND STANDARD DEVIATION FOR THE USTATISTIC n1n2 2 (n1 )( n2 )( n1 n2 1) 12 where: n1 and n2 = Sample sizes from populations 1 and 2 Mann-Whitney U Test - Large Samples - MANN-WHITNEY U-TEST STATISTIC z n1n2 U 2 (n1 )( n2 )( n1 n2 1) 12 Mann-Whitney U Test (Example 15-4) H 0 : ~1 ~2 0 H A : ~1 ~2 0 0.05 Rejection Region = 0.05 z 1.645 z n1n2 U 2 (n1 )( n2 )( n1 n2 1) 12 ~1 ~2 0 27,412 29,088 1.027 (144)( 404)(144 404 1) 12 Since z= -1.027 > -1.645, we do not reject H0, Wilcoxon Matched-Pairs Test The Wilcoxon matched pairs signed rank test can be used in those cases where the following assumptions are satisfied: • The differences are measured on a continuous variable. • The measurement scale used is at least interval. • The distribution of the population differences is symmetric about their median. Wilcoxon Matched-Pairs Test WILCOXON MEAN AND STANDARD DEVIATION n(n 1) 4 n(n 1)( 2n 1) 24 where: n = Number of paired values Wilcoxon Matched-Pairs Test WILCOXON TEST STATISTIC z n(n 1) T 4 n(n 1)( 2n 1) 24 Kruskal-Wallis One-Way Analysis of Variance Kruskal-Wallis one-way analysis of variance can be used in one-way analysis of variance if the variables satisfy the following: • They have a continuous distribution. • The data are at least ordinal. • The samples are independent. • The samples come from populations whose only possible difference is that at least one may have a different central location than the others. Kruskal-Wallis One-Way Analysis of Variance H-STATISTIC k 2 i R 12 H 3( N 1), with df k 1 N ( N 1) i 1 ni where: N = Sum of sample sizes in all samples k = Number of samples Ri = Sum of ranks in the ith sample ni = Size of the ith sample Kruskal-Wallis One-Way Analysis of Variance CORRECTION FOR TIED RANKINGS g 1 (t i 1 3 i ti ) N N 3 where: g = Number of different groups of ties ti = Number of tied observations in the ith tied group of scores N = Total number of observations Kruskal-Wallis One-Way Analysis of Variance H-STATISTIC CORRECTED FOR TIED RANKINGS 2 i k H R 12 3( N 1) N ( N 1) i 1 ni g 1 (t i 1 3 i ti ) N N 3 Key Terms • Kruskal-Wallis One-Way Analysis of Variance • Mann-Whitney U Test • Nonparametric Statistical Procedure • Run • Runs Test • Wilcoxon Test