Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
Stats 1: Confidence Intervals, p-values, Screening, NNT, and NNH:
USMLE Step 1 Review Material
Objectives:
1. Know the meanings and utility of confidence intervals
2. Be able to explain and calculate sensitivity, specificity, PVP, and PVN.
3. Be able to explain and calculate number needed to treat (NNT) and harm (NNH)
4. Know the biases involved with screening tests
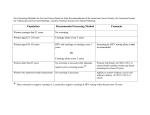
Population Screening
What is screening?
o The presumptive identification of an unrecognized disease or defect by the application of
tests, examinations, or other procedures which can be applied rapidly.
o Sort out apparently well persons who probably have a disease from those who probably do
not.
o Must be referred to physician for actual diagnosis and treatment.
o A screening test is performed to detect potential health disorders or diseases in persons
who do not have any symptoms of disease. The goal is early detection and lifestyle changes
or surveillance, to reduce the risk of disease, or to detect it early enough to treat it most
effectively. Screening tests are not considered diagnostic, but are utilized to identify a
subset of the population who should have additional testing to determine the presence or
absence of disease.
Screening Objectives
o To classify asymptomatic people as being likely or unlikely of having the disease at an
earlier stage than if they had waited for symptoms to arise.
o To reduce mortality and morbidity related with the disease.
o Assumes that earlier diagnosis will provide better treatment, reduce risk of adverse disease
effects, and improve and prolong survival.
o How would screening reduce the morbidity and mortality related with a disease?
Well, if the disease in question meets requirements of good mass screening
programs. For example, there is an acceptable form of treatment for the disease and
the screening test can detect disease at the latent or early symptomatic stage. In
other words, the screening can pick up disease early and provide enough time for
proper care and treatment to be provided. This may reduce morbidity and
mortality from the disease. Thus, screening is a form of secondary prevention, as it
identifies asymptomatic people between the time of pathological onset and the
occurrence of clinical symptoms, with the goal of improving survival.
o Are we screening if we test people with symptoms? No, not really.
What are we doing? Some screening may be considered tertiary prevention since
you may be testing people AFTER clinical symptoms are present. However, a
clinical diagnosis must be made BEFORE tertiary prevention can take place.
Natural History of Disease & Lead Time Bias
o Lead time bias – Unless the clinical course of the disease is altered, detection through
screening appears to increase survival time when in actuality the disease was just detected
earlier.
o Lead time is the time between when a disease can be picked up by screening and when it
would have been picked up by clinical symptoms. In other words, the amount of time that a
disease diagnosis is advanced by screening. This amount of time is unmeasurable for an
individual because we don’t know exactly when he/she would have been clinically detected
for disease. Recall that screening is performed on asymptomatic people. Thus, if a disease
is detected through screening, it will be before the onset of clinical symptoms. If the person
gets diagnosed soon after the screening test, like he/she should if this is a quality screening
test, then the disease diagnosis will have occurred sooner than expected. This is because
he/she did not have symptoms present that would hopefully have led to a visit to the
doctor for a clinical exam and testing.
o We will see an increase in the length of survival for people who have disease detected by
screening but why? What is it about early disease detection that increases survival time?
Simply stated, if the disease is diagnosed earlier, then the time between this diagnosis and
death will be longer. For example, if I am screened for prostate cancer at age 50 and screen
positive, and then I get clinically diagnosed with prostate cancer. I then die at age 80. My
survival time with prostate cancer would be 30 years. However, let’s say I did not get
screened and I don’t develop symptoms till age 70. I go to the doctor about my symptoms
and get clinically diagnosed at age 70. I still die at age 80. Now, my survival time is only 10
years. Thus, prostate cancer screening improved my survival time with the disease by 20
years.
o Length-time bias
Occurs because the proportion of slow-growing lesions diagnosed during screening
is greater than the proportion of those diagnosed during usual medical care.
Makes it seem that screening and early treatment are more effective than usual care.
Screening works best when a disease develops slowly.
Screening tests are likely to find mostly slow-growing tumors because they are
present for a long time before symptoms develop.
Fast-growing tumors are more likely to cause symptoms leading to diagnosis in the
interval between screening examinations.
Thus, screening often finds diseased people with a better prognosis (typical for
cancer screening tests – hence the term, ‘tumors’).
May make screening look like it reduces mortality rates when in fact it just identifies
people who are more likely to survive anyways.
o Compliance Bias
Compliance: A result of the extent to which patients follow medical advice.
Compliant patients tend to have better prognoses regardless of screening
For example, if a study compared disease outcomes among volunteers for a
screening program with outcomes in people who did not volunteer, better results
for the volunteers may not be due to screening but rather factors related to
compliance.
o How to avoid These Biases
Lead time: Use mortality rates instead of survival rates
Length-time and Compliance: Compare outcomes in randomized trial (1 control
group vs. 1 screened group) and count ALL outcomes regardless of method of
detection (lead-time) or compliance.
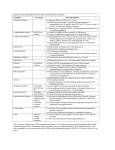
Sensitivity, Specificity, Predictive Value Positive, and Predictive Value Negative
o True Positives (TP): These people had a positive screening test result and did have the
disease.
o False Positives (FP): These people had a positive screening test result but did NOT have
the disease.
o True Negatives (TN): These people had a negative screening test result and did not have
the disease.
o False Negatives (FN): These people had a negative screening test result but DID HAVE the
disease.
o Sensitivity (Se)
The sensitivity (Se) of a screening test is the probability of testing positive, given
you have the disease.
It is the probability (proportion) of correct classification of CASES.
Use the COLUMNS of the 2x2 table to calculate.
o Specificity (Sp)
The specificity (Sp) of a screening test is the probability of testing negative, given
you do NOT have the disease.
It is the probability (proportion) of correct classification of NON-case.
Use the COLUMNS of the 2x2 table to calculate.
True Negatives / (False Positives + True Negatives) = specificity
o Predictive Value Positive (PVP)
The predictive value positive (PVP) of a screening test is the probability of having
the disease, given you tested positive. given you have the disease.
Essentially, how well does your screening test correctly predict who has disease.
Use the ROWS of the 2x2 table to calculate.
True Positives / (True Positives + False Positives) = predictive value positive
o Predictive Value Negative (PVN)
The Predictive Value Negative (PVN) of a screening test is the probability of NOT
having the disease, given you tested negative.
Use the ROWS of the 2x2 table to calculate.
True Negatives / (False Negatives + True Negatives) = Predictive Value Negative
o How to create a 2x2 Table for a Screening Test
True Positives (TP): These people had a positive screening test result and did have
the disease.
False Positives (FP): These people had a positive screening test result but did NOT
have the disease.
True Negatives (TN): These people had a negative screening test result and did not
have the disease.
False Negatives (FN): These people had a negative screening test result but DID
HAVE the disease.
Ideally, we would like to have as few false positives and false negatives as possible.
The sensitivity (Se or Sn) of a screening test is the probability of testing positive,
given you have the disease. It is the probability (proportion) of correct classification
of detectable, pre-clinical disease. Essentially, how well does your screening test
identify people who have the disease you are looking for. It can be calculated by:
o True Positives / (True Positives + False Negatives) = sensitivity of a
screening test.
o Can also be worded as Cases of disease identified by screening test / All cases
of disease = Sensitivity
o If you are familiar with probability jargon, you can think of sensitivity like
this as well:
p ( T+ | D+). The ‘p’ indicates ‘probability of’, ‘T+’ indicates a positive
test, ‘|’ indicates given, and ‘D+’ indicates you have the disease.
The specificity (Sp) of a screening test is the probability of testing negative, given
you do NOT have the disease. It is the probability (proportion) of correct
classification of NON-cases. It can be calculated by:
o True Negatives / (False Positives + True Negatives) = specificity of a
screening test.
o Can also be worded as Non-cases identified by screening test / All Non-cases
= Specificity
o If you are familiar with probability jargon, you can think of specificity like
this as well:
p ( T- | D-). The ‘p’ indicates ‘probability of’, ‘T-’ indicates negative
test, ‘|’ indicates given, and ‘D-’ indicates you do NOT have the disease.
Example: Mammography and Breast Cancer
o Sensitivity (Se or Sn)
Sensitivity = True Positives / (True Positives + False Negatives) = 50 /
(50 + 15) = 0.77 or 77%. The probability of a positive mammogram,
given a woman has breast cancer, is 77%.
o Specificity (Sp)
Specificity = True Negatives / (False Positives + True Negatives) = 70
/ (10 + 70) = 0.88 or 88%. The probability of a negative mammogram,
given a woman does NOT have breast cancer, is 88%. a woman has
breast cancer, is 77%.
o Predictive Value Positive (PVP)
Predictive Value Positive = True Positives / (True Positives + False
Positives) = 50 / (50 + 10) = 0.83 or 82%. The probability of breast
cancer, given a woman has a positive mammogram, is 83%.
o Predictive Value Negative (PVN)
Predictive Value Negative = True Negatives / (True Negatives + False
Negatives) = 70 / (70 + 15) = 0.82 or 82%. The probability of NOT
having breast cancer, given a woman has a negative mammogram, is
82%.
o Summary of Screening Calculations
Sensitivity = TP / (TP+FN)
Specificity = TN / (TN+FP)
Positive predictive value = TP / (TP+FP)
Negative predictive value = TN / (TN+FN)
These are all proportions that can be calculated from the 2 x 2 table
Range is 0 to 1
Can be multiplied by 100 to express as a percentage
o Knowing the Definitions
It is extremely important to know how to define and describe these measures of
association, rather than simply memorizing letters of cells.
When explaining these concepts to someone who is not familiar with epidemiology,
simple letters and formulas will not suffice. They need to know what the concept
means.
How would you explain sensitivity, specificity, or the predictive values to someone you
do not know?
Number Needed to Treat (NNT) and Number Needed to Harm (NNH)
o The Number Needed to Treat (NNT) is the number of patients you need to treat to prevent one
additional bad outcome (death, stroke, etc.).
o For example, if a drug has an NNT of 5, it means you have to treat 5 people with the drug to
prevent one additional bad outcome.
o To calculate the NNT, you need to know the Absolute Risk Reduction (ARR); the NNT is the
inverse of the ARR:
NNT = 1/ARR
Where ARR = CER (Control Event Rate) - EER (Experimental Event Rate). NNTs are
always rounded up to the nearest whole number.
o Take absolute value of CER – EER
o The ARR is therefore the amount by which your therapy reduces the risk of the bad outcome.
For example, if your drug reduces the risk of a bad outcome from 50% to 30%, the ARR is:
ARR = CER - EER = 0.5 - 0.3 = 0.2
NNT = 1/ARR = 1/0.2 = 5
o NNT Websites
http://www.ebem.org/nntcalculator.html
http://www.calctool.org/CALC/prof/medical/NNT
o Example
The results of the Diabetes Control and Complications Trial into the effect of intensive
diabetes therapy on the development and progression of neuropathy indicated that
neuropathy occurred in:
9.6% of patients randomized to usual care and
2.8% of patients randomized to intensive therapy
The number of patients we need to treat with the intensive diabetes therapy to prevent
one additional occurrence of neuropathy can be determined by calculating the absolute
risk reduction as follows:
o ARR = |CER - EER| = |9.6% - 2.8%| = 6.8%
o NNT = 1/ARR = 1/6.8% = 14.7 or 15
o We therefore need to treat 15 diabetic patients with intensive therapy to
prevent one from developing neuropathy.
o Number Needed to Harm (NNH)
Looks at the number of people you would expect to treat to get a bad result in one
person
The number needed to harm is the inverse of the attributable risk
The number needed to harm (NNH) indicates how many patients need to be exposed
to a risk factor over a specific period to cause harm in one patient that would not
otherwise have been harmed
The NNH is the inverse of the absolute difference in adverse event rates between the
experimental and control arms.
Confidence Intervals, p-values, and Statistical Tests, and More
o Types of Variables
o Objectives
1. Know the definitions of each type of variable and types of correlations
2. Identify the types of distributions and differentiate between negative skew and positive
skew
3. Know what t-tests, chi-square, and ANOVA are used for
4. Know the basics behind power and sample size
Continuous variables are numeric variables; variables that would make sense for you to
add, subtract, multiply or divide. You can count, order and measure continuous
data. Some examples of continuous variables are:
o age
o height
o weight
o temperature
o the amount of sugar in an orange
Ordinal variables order (or rank) data in terms of degree. They do not establish the
numeric difference between data points. They indicate only that one data point is
ranked higher or lower than another
o Economic status: low, medium, and high
o Education: elementary school graduate, high school graduate, some college,
college graduate
o Likert Scale: Strongly Agree, Agree, Neutral, Disagree, Strongly Disagree
o the time required to run a mile
Nominal variables: A set of data is said to be nominal if the values / observations
belonging to it can be assigned a code in the form of a number where the numbers are
simply labels. You can count but not order or measure nominal data.
Gender
Marital Status
Race
Ethnicity
For example, in a data set, males could be coded as 0, females as 1; marital status of an
individual could be coded as Y if married, N if single.
Correlation (r)
Literally means co-relate and refers to the measurement of a relationship between two or more
variables.
A correlation coefficient (r) ranges between –1.0 and +1.0 and provides two important pieces of
information regarding the relationship: Intensity and Direction.
Intensity refers to the strength of the relationship and is expressed as a number between zero
(meaning no correlation) and one (meaning a perfect correlation).
A correlation is a measure of the strength of linear association between two variables. Correlation
will always between -1.0 and +1.0. If the correlation is positive, we have a positive relationship. If
it is negative, the relationship is negative.
Another way of describing this is that correlation is a measure of the strength of the relationship
between two variables. It is used to predict the value of one variable given the value of the other.
For example, a correlation might relate distance from urban location to gasoline consumption.
Expressed on a scale from -1.0 to +1.0, the strongest correlations are at both extremes (closest
to -1.0 or closest to +1.0) and provide the best predictions.
Direction refers to how one variable moves in relation to the other. A positive correlation means
that two variables move in the same direction, either both moving up or both moving down.
o For example, high school grades and college grades are often positively correlated in that
students who earn high grades in high school tend to also earn high grades in college.
A negative (inverse) correlation means that the two variables move in opposite directions; as
one goes up, the other tends to go down.
o For example, depression and self-esteem tend to be negatively correlated because the more
depressed an individual is, the lower his or her self-esteem.
Confidence Intervals and p-values
Confidence Intervals (CI)
o Method used to quantify random error surrounding a point estimate
o Related to p-value through the α level
p-value is significant when it is less than the α
α is arbitrarily chosen by researcher, usually α = .05
o Point estimate +/- (Constant) * (Standard Error)
Point estimate is a relative risk, odds ratio, mean value, etc.
The value of the constant is related to α (Z score), usually set at 1.96
o The z-score is equal to 1.96 for a 95% confidence interval.
o Usually, α is determined by the researcher. It is usually = .05.
o You are more likely to have random error (variability) in a small study than a large study.
o Here you an see the confidence interval is (1.9, 4.1) around the estimate of 2.8
o What information do the point estimate and 95% CI provide?
The point estimate is the best estimate of the measure of an association, based on
the data from this study
The 95% CI is a measure of the potential variability of the point estimate due to
sampling variability
A range of values around the point estimate.
A wider confidence interval indicates a larger amount of random variability.
A narrower confidence interval indicates a smaller amount of random variability.
The confidence interval is also a reflection of the sample size, given the same
measurement error a narrower confidence intervals reflects a larger sample size
and a wider confidence interval reflects a smaller sample size.
o Interpreting a 95% CI
Assuming no systematic error and if samples were drawn from the same source
population many times, the values between the lower and upper bound of the
confidence intervals would include the true point value 95% of the time.
Does not mean there is a 95% probability that your estimate is correct or accurate
o This is an illustration of doing repeated trials of your study and the point estimates (red
dots) and the confidence intervals you get for each study you do. Notice, the CI and point
estimate are not the same for each study. Naturally, with a different group of people
making up your study population, you will have new data and therefore new results!
o Here is an example. When the population is n = 500, the confidence interval is (1.9, 4.1).
When the population is only n=100, the confidence interval is (1.0, 6.1).
P-values
o A p-value is the probability, assuming that the null hypothesis is true, of observing a value
as extreme or more extreme than the one you obtained by chance
o By tradition, a p-value less than 0.05 is used to reject the null hypothesis that there is no
association between exposure and disease
o Because this cut-point of 0.05 is arbitrary, we can reject the null when we should not or
accept the null when we should reject it. We will discuss this in more detail when we get to
Power and Type I and Type 2 Error.
o P-value does not tell us about the magnitude of the observed effect (RR or OR) or about the
random variability (precision) of the estimate of effect.
o A p-value less than 0.05 does not tell us the magnitude of the observed effect. For instance,
the RR could be 1.1 if it is a really big study, making it easier to get a statistically significant
result. The RR could be 7.5. We do not know this because p-values don’t tell us that. Pvalues also don’t tell us how narrow or wide the confidence interval is. That is what makes
them so dangerous to use them alone for study interpretation.
Summary
o The 95% CI provides the point estimate and the random variability around the estimate
due to sampling variability.
o If the 95% CI excludes 1.0 (for a ratio measure), the p-value will be less than 0.05
o Values closer to the point estimate are more compatible with the data than values further
away from the point estimate.
o We need to keep in mind that lack of statistical significance (p-value greater than .05) does
not mean we are absent of clinical significance. A finding can be very important clinically,
but not be statistically significant. For example, I am just making this up … if the OR for
hypertension and heart attack is 2.5 but the confidence interval is (0.95, 3.90), I might say
the result is not statistically significant. However, look at the confidence interval and notice
that most of it does not include 1.0 and the measure of effect is greater than 1.0. Thus, we
would not want to disregard this result. The bottom line is that we need to look more at
our effect measure (point estimate) and the confidence interval to look at its precision,
rather than just seeing if it includes 1.0 or not.
o The confidence interval is more informative than the p-value.
It is the preferred mode for indicating the extent of potential sampling variability.
May be used to determine if results are statistically significant.
Types of Distributions
The standard deviation is a statistic that tells you how tightly all the various examples are
clustered around the mean in a set of data. When the examples are pretty tightly bunched together
and the bell-shaped curve is steep, the standard deviation is small. When the examples are spread
apart and the bell curve is relatively flat, that tells you you have a relatively large standard
deviation.
One standard deviation away from the mean in either direction on the horizontal axis accounts for
just over 68 percent of the observations in this group. Two standard deviations away from the
mean account for roughly 95 percent of the observations. And three standard deviations account
for about 99 percent of the observations.
What is a z-score?
o A z-score measures the distance between an observation and the mean.
o It is measured in units of standard deviation (SD).
o SD is the square root of the variance; tells you how far the numbers tend to vary from the
mean
o For example, suppose the sample mean = 25 points and the SD = 4 points for a class quiz.
Your quiz score was 30 points.
o The z-score = (x – sample mean) / SD = (30 – 25) / 4 = 1.25. Thus, your score of 30 lies 1.25
standard deviations above the mean.
o Z-scores for % CIs: 90% = 1.645, 95% = 1.96, 98% = 2.236, 99% = 2.576.
o Notice the z-scores get larger as the CI % gets larger. Why is this?
o In order to be more confident that the OR (or RR, IR, etc.) is within the lower and upper
bound, you must have a wider confidence interval.
o Think about it, a wider interval is more likely to contain the OR, RR, or IR you
calculated.
Normal (Gaussian Distribution)
o All normal distributions are symmetric and have bell-shaped density curves with a single
peak.
o Defined by two parameters, location and scale: the mean ("average", μ) and variance
(standard deviation squared, σ2) respectively
o Two quantities have to be specified: the mean (µ), which is where the peak of the density
occurs, and the variance σ2 (square of the standard deviation), which indicates the spread
or girth of the bell curve.
o The mean can be any value between ± infinity and the standard deviation must be positive.
Skewness: Positive and Negative
o Positive: Tail is on the RIGHT, Mean > Median > Mode
o Negative: Tail is on the LEFT, Mean < Median < Mode
o
o Skewness is a measure of the degree of asymmetry of a distribution. If the left tail (tail at
small end of the distribution) is more pronounced that the right tail (tail at the large end of
the distribution), the function is said to have negative skewness. If the reverse is true, it has
positive skewness. If the two are equal, it has zero skewness.
o When the variable is skewed to the left (i.e., negatively skewed), the mean shifts to the left
the most, the median shifts to the left the second most, and the mode the least affected by
the presence of skew in the data.
Therefore, when the data are negatively skewed, this happens:
mean < median < mode.
o When the variable is skewed to the right (i.e., positively skewed), the mean is shifted to the
right the most, the median is shifted to the right the second most, and the mode the least
affected.
Therefore, when the data are positively skewed, this happens:
mean > median > mode.
o If you go to the end of the curve, to where it is pulled out the most, you will see that the
order goes mean, median, and mode as you “walk up the curve” for negatively and
positively skewed curves.
o Negative Skew
Tail is on the LEFT
Mean < Median < Mode
The skewness statistic is sometimes also called the skewedness statistic. Normal
distributions produce a skewness statistic of about zero. (I say "about" because
small variations can occur by chance alone). So a skewness statistic of -0.01819
would be an acceptable skewness value for a normally distributed set of test scores
because it is very close to zero and is probably just a chance fluctuation from zero.
As the skewness statistic departs further from zero, a positive value indicates the
possibility of a positively skewed distribution (that is, with scores bunched up on
the low end of the score scale) or a negative value indicates the possibility of a
negatively skewed distribution (that is, with scores bunched up on the high end of
the scale). Values of 2 standard errors of skewness (ses) or more (regardless of sign)
are probably skewed to a significant degree.
o Two simple Rules
You can use these two rules to provide information about skewness when no graph
is given. All you need is the mean and the median.
If the mean is less than the median, the data are skewed to the left.
If the mean is greater than the median, the data are skewed to the right.
Analysis of Variance (ANOVA)
o ANOVA tests hypotheses about differences between two or more means
o The assumption is that the distribution of the sample means are normally distributed
o Usually comparing 3 or more. T usually just 2
o The ANOVA performs a simple analysis of variance, testing the hypothesis that means from
two or more samples are equal (drawn from populations with the same mean). This
technique expands on the tests for two means, such as the t-test.
o ANOVA is a general technique that can be used to test the hypothesis that the means among
two or more groups are equal, under the assumption that the sampled populations are
normally distributed.
o Example: Research question – is there a statistically significant difference in the starting
salaries of education majors, arts and science majors, and engineering majors?
Null Hypothesis H0: µE = µA&S = µB (i.e., the population means for education
students, arts and sciences students, and business students are all the same)
Alternative Hypothesis H1: Not all equal (i.e., the population means are not all the
same
o What is variance?
The variance tells you (exactly) the average deviation from the mean, in "squared
units."
The variance of a random variable, probability distribution, or sample is one
measure of statistical dispersion, averaging the squared distance of its possible
values from the expected value (mean). Whereas the mean is a way to describe the
location of a distribution, the variance is a way to capture the distribution’s scale
or degree of being spread out.
The unit of variance is the square of the unit of the original variable. The positive
square root of the variance, called the standard deviation, has the same units as the
original variable and can be easier to interpret for this reason
o T-test
One frequently used statistical test is called the t-test for independent samples. We
do this when we want to determine if the difference between two groups is
statistically significant.
The t-test for a single mean allows us to test hypothesis about the population mean
when our sample size is small and/or when we do not know the variance of the
sampled population. In so-called one-sample t-tests, the observed mean (from a
single sample) is compared to an expected (or reference) mean of the population
(e.g., some theoretical mean), and the variation in the population is estimated based
on the variation in the observed sample.
Example: Research question - Is the difference between average starting salary for
males and the average starting salary for females significantly different?
Null Hypothesis H0: µM = µF (i.e., the population mean for males equals the
population mean for females)
Alternative Hypothesis H1: µM ≠ µF (i.e., the population mean for males does
not equal the population mean for females)
o Chi-Square (x2)
Chi-square is a family of distributions commonly used for significance testing. The
most common variants are the Pearson chi-square test and the likelihood ratio chisquare test.
The null hypothesis is that the observed data are sampled from a populations with
the expected frequencies. We need to combine together the discrepancies between
the observed and expected, and then calculate a p-value answering this question: If
the null hypothesis were true, what is the chance of randomly selecting subjects
with this large a discrepancy between observed and expected counts? We can
combine the observed and expected counts into a variable, the chi-square.
There are basically two types of random variables and they yield two types of data:
numerical and categorical. A chi square (X2) statistic is used to investigate whether
distributions of categorical variables differ from one another. Basically categorical
variables yield data in categories and numerical variables yield data in numerical
form. Responses to such questions as "What is your major?" or Do you own a car?"
are categorical because they yield data such as "biology" or "no." In contrast,
responses to such questions as "How tall are you?" or "What is your G.P.A.?" are
numerical. Numerical data can be either discrete or continuous. The table below
may help you see the differences between these two variables.
The chi-square statistic is calculated by finding the difference between each
observed and theoretical frequency for each possible outcome, squaring them,
dividing each by the theoretical frequency, and taking the sum of the results.
Pearson Chi-Square
It tests a null hypothesis that the frequency distribution of certain events
observed in a sample is consistent with a particular theoretical distribution.
The events considered must be mutually exclusive and have total probability
1.
A common case for this is where the events each cover an outcome of a
categorical variable. A simple example is the hypothesis that an ordinary sixsided dice is "fair", i.e., all six outcomes are equally likely to occur.
Power and Sample Size
o How do we know if treatments or screening tests are statistically different? Power.
o Power = Probability of correctly concluding that the treatments differ = Probability
of detecting a difference between the treatments if the treatments do in fact differ
Probability of rejecting H0 when H0 is in fact false; finding a difference when one
exists. Power = 1 – β)
o Statistical power refers to the ability of a study to demonstrate an association if one exists.
In this case, power is a measure of your ability to make the correct conclusion regarding
your treatment. Often, power is used with hypothesis testing. For example, let’s say your
hypothesis of two treatments (Ex. Arthroscopic knee surgery vs. sham surgery) was that
they both provided the same result to the knee. As a result of your trial, you find your
hypothesis is false and the arthroscopic knee surgery provides a better result for the
participant. Since rejecting your hypothesis is the correct decision here, the power of your
test is the probability that your hypothesis is rejected. Put another way, If the hypothesis is
false, so that rejection is the correct decision, the probability that the test hypothesis is
rejected is called the power of the test. For the biostatisticians, you may here power
defined as the probability of rejecting the null hypothesis when you should reject the null
hypothesis.
o Determining sample size depends on three things:
The anticipated difference between the treatment and comparison groups
The background rate of the outcome
The probability of making statistical errors known as alpha (Type 1) and beta (Type
2) errors
o Type 1 Error is when you conclude the treatments are different when in reality, they are
not. In statistics, it is when you reject the null hypothesis when you should not have
rejected it. This is the alpha level and is set by the investigators. A Type I error represents,
o
o
o
o
o
in a sense, a "false positive" for the researcher's theory. From society's standpoint, such
false positives are particularly undesirable. They result in much wasted effort, especially
when the false positive is interesting from a theoretical or political standpoint (or both),
and as a result stimulates a substantial amount of research. Such follow-up research will
usually not replicate the (incorrect) original work, and much confusion and frustration will
result.
Stating there is an effect or difference when none exists (Accept Ha and reject H0)
Type 2 Error is when you conclude the treatments are the same when in reality, the
treatments are different. In statistics, it is when you do not reject the null hypothesis when
you should have rejected it. The probability of a Type 2 Error is related to power by the
equation: Pr (Type 2 Error) = 1 – power. This can also be written as: Power = 1 – Pr (Type
2 Error). A Type 2 error is a tragedy from the researcher's standpoint, because a theory
that is true is, by mistake, not confirmed. So, for example, if a drug designed to improve a
medical condition is found (incorrectly) not to produce an improvement relative to a
control group, a worthwhile therapy will be lost, at least temporarily, and an
experimenter's worthwhile idea will be discounted.
Stating there is no effect or difference when one exists (Fail to reject H0 when H0 is
false)
Pr is defined as ‘probability of’
It is important to note that the null hypothesis of most statistical tests means the two
treatments are the SAME with their effects. Rejecting the null hypothesis implies the two
treatments provide different effects.
Interestingly, 1 – α = Test Specificity. In other words, 1 minus the Type 1 error
equals the specificity (Sp) of a test.
1 – β = your power. It also equals your test’s sensitivity (Se). Recall that sensitivity is
the probability of identifying a subject with a positive screen when in fact he/she has
the disease you are screening for.
o
o Think of power like this. Let’s say the electricity goes out and you are in a dark family room
looking for a tiny paper clip with a flashlight. If you have a weak flashlight, you will have
tremendous difficulty finding it. This would be low power. We might conclude the paper
clip is not in the room when in reality, the paper clip is in the room. In any case, the ability
to make the correct decision that the paper clip is indeed in the room would be severely
reduced (low power). For a tiny object, you need a bright flashlight to more easily find the
paper clip. A brighter flashlight means you have more power to find the paper clip and
make the correct decision that it is in the room.
o Another way that may be more helpful is this: if you are looking for small difference
between two tests, you need a powerful test to make such a distinction. This requires a
larger sample size. In most trials of drug therapies, a large sample size is needed because
the trial is being conducted to determine if the treatment offers a small improvement over
an existing treatment. For preventive trials, a large sample size is needed because the
subjects are healthy at the start and the disease end points usually have a low incidence.
o Sometimes events occur by chance. These statistics give an idea of how much difference
we would see by chance alone.
o Significance of alpha (α): How stringent we want to be that we know we will not observe a
chance event. For instance, if we increase the alpha to equal 0.10 instead of 0.05, we
increase the probability of a Type 1 Error. This means we increase the probability of
concluding the two treatments are different when in reality they are the same. However, if
the treatments are different, we have reduced the Type 2 Error and thus increased our
power to conclude they are different. Recall that 1 – β = power.
o Power and Sample Size – Key Principle # 1
The larger your sample size (N), the higher your power is to detect an association,
difference, effect, etc.
The smaller your sample size (N), the lower your power is to detect an association,
difference, effect, etc.
Note: Maximum power is 100%, so eventually an increase in sample size will not
increase your power
It’s really simple, actually. Let’s say we have two samples with which we will
do the SAME STUDY (one study per sample). The ‘larger’ sample has 1,000
people. With more people in your study, you have MORE data to derive your
results and conclusions with. Thus, you will have MORE confidence, should
your methods be valid, that your results are precise and accurate, thus MORE
likely to be generalizable to other populations.
Let’s say the ‘smaller’ sample has 100 people in it. With LESS people in your
study, you have LESS data to derive your results and conclusions with. Thus,
you will have LESS confidence, should your methods be valid, that your
results are precise and accurate, and LESS likely to be generalizable to other
populations.
This is not to say that a sample of 100 is bad. Many trials and some other
types of studies may have even fewer than this. However, the larger your
sample, the easier it is to see if there really is an association, difference, etc.
(higher power).
Example
Let’s say you want to study the association between levels of fiber intake
(exposure) and serum cholesterol level (outcome). Your sample size is N =
1,000.
A separate research team conducts the same study with a sample size of N =
250.
Which study (the N=1,000 or N=250) will have more power to detect an
association?
o The study with N = 1,000. Why? Because you have MORE people in
your study. The more people you can observe eating a lot of fiber, the
easier it will be to find those having low serum cholesterol levels (a
result of higher power). Thus, you should be more confident that your
findings are due to your exposure of interest (fiber intake) rather than
o
o
o
o
due to chance. This also narrows confidence interval limits (we’ll
study these later).
o If sample size is too low, the experiment will lack the precision to
provide reliable answers to the questions it is investigating. In
general, the larger the sample size N, the smaller sampling error tends
to be. (One can never be sure what will happen in a particular
experiment, of course.) If we are to make accurate decisions about a
parameter like , we need to have an N large enough so that sampling
error will tend to be "reasonably small." If N is too small, there is not
much point in gathering the data, because the results will tend to be
too imprecise to be of much use.
Power and Differences Between Treatments – Key Principle #2
The larger the difference between two treatments, populations, etc., the lower the
amount of power you need to detect the difference Smaller sample size needed!
The smaller the difference between two treatments, populations, etc., the higher
the amount of power you need to detect the difference Larger sample size
needed!
Power and Differences Between Treatments – Key Principle #3
The larger the difference between two treatments, populations, etc. Smaller
sample size needed to have adequate power.
The smaller the difference between two treatments, populations, etc. Larger
sample size needed to have adequate power.
Example
In a randomized trial, you wish to compare two doses of the same treatment (81
mg of aspirin vs. 82 mg of aspirin) on how they may prevent a myocardial infarction
(outcome) over a 1-year period.
Is it going to be easy to see which dose is better?
NO!!! There is only 1 mg difference in the treatments. You would need
extremely high power to detect any difference, if one exists, between these
two treatments.
Example
In a randomized trial, you wish to compare two doses of the same treatment (81
mg of aspirin vs. 243 mg of aspirin) on how they may prevent a myocardial
infarction (outcome) over a 1-year period.
Is it going to be easy to see which dose is better?
Yes! The one dose is 3 times as high (243 mg) as the other dose (81 mg). If
there is an actual difference in the health effects between the two doses,
you need much less power to detect a difference.
Just think about it logically. If two treatments are very different from each other
(for example, comparing 81 mg of aspirin to 243 mg of aspirin), shouldn’t it be
easier to detect a difference in outcome (blood pressure level) than if you had two
treatments that were nearly identical to each other (for example, comparing 81 mg
of aspirin to 82 mg of aspirin on blood pressure level)? The answer is … YES! It is
going to be very easy to see what the effect of 81 mg of aspirin is on hypertension
and the effect of 243 mg of aspirin on hypertension. It should be very easy to see
how these two treatments differ, if they actually do!
However, if it is 81 vs. 82 mg., how can you possibly tell if there is any improved
outcome by one dose vs. the other even if one exists? Bottom line, you probably
cannot tell!