Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
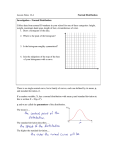
STAT 1060 - Chapter 6 Notes Standard Deviation and Normal Model September 26, 2011 () Exploring and Understanding Data September 26, 2011 1/1 Distribution of final grades of those completing final exam 0.000 0.015 0.030 relative frequency histogram of grades mean= 68.3 standard deviation = 13.9 and best fitting normal curve N( 68.3 , 13.9 ) 30 40 50 60 70 80 90 grade Figure: 1. Probability histogram, and overlaid best normal model. () Exploring and Understanding Data September 26, 2011 2/1 The histogram in figure 1 is a type of relative frequency histogram in which the total area of the bars sums to 1. similarly, the total area under the overlaid “bell shaped curve” equals 1. The proportion of students with grades of 70 or less is the sum of the areas of the bars to the left of 70. This can be fairly closely approximated by the area under the curve to the left of 70. () Exploring and Understanding Data September 26, 2011 3/1 The standard deviation as a ruler How good was a grade of 77 in this class? Depending on how others scored, a 77 might have been quite good, or it might have been quite average. It is better to replace the 77 by a standardized value or z-score Where y denotes a grade, ȳ the average grade in the class, and s the standard deviation of the grades, the standardized value of y is y − ȳ s A grade of 77 corresponds to a z-score of z = (77 − 68.3)/13.9 = .625. z-scores have no units, so the interpretation of a z-score is the same regardless of what is being measured. In this case, a grade of 77 is .625 standard deviations above the mean. In the process of standardizing, we first shift, and then we re-scale. z= () Exploring and Understanding Data September 26, 2011 4/1 Normal probability models If the distribution (in this case, of grades) is approximately symmetric and unimodal, then we can have a better interpretation of what a standardized score of .625 means. A distribution which is approximately symmetric and unimodal is well represented by a theoretical distribution known as a normal model, a normal distribution, or more colloquially, a bell-shaped curve. A normal model is specified by two characteristics - its mean µ and its standard deviation σ. µ is a real number, and σ > 0 is a positive real number. These are called parameters of the normal model. Parameters have nothing to do with data. They are properties of the model. On the other hand, the sample mean ȳ , and sample standard deviation s are known as statistics, which are numbers calculated from the data. The normal model with mean µ and standard deviation σ is denoted by N(µ, σ). () Exploring and Understanding Data September 26, 2011 5/1 Aside - a general outline of statistical inference Generally we have data in the form of a sample which is drawn randomly from a population. A primary goal of statistical inference is to make estimates of the unknown parameters. We use properties of a sample to infer properties of the population. It is often convenient to describe the population using a probability model, also known as a probability distribution. For example, we might assume that the population of incomes of Canadians follows a symmetric, unimodal distribution. We might then want to estimate the point of symmetry, which would correspond to the mean income in the population. It is often reasonable to assume a symmetric, unimodal distribution. More generally, there is a mathematical argument which suggests that many distributions can be accurately approximated by a normal probability model. Later in the course you will see this stated as the central limit theorem. Normal probability models are symmetric and unimodal () Exploring and Understanding Data September 26, 2011 6/1 0.8 Examples of some normal probability models 0.0 0.2 0.4 0.6 µ=0 σ=1 µ=0 σ=3 µ=−3 σ=3 µ=0 σ=.5 −10 −5 0 5 10 normal models N(µ µ,σ σ) Figure: 2. () Exploring and Understanding Data September 26, 2011 7/1 Standard normal model normal models can be standardized in the same way as data if y follows a normal model N(µ, σ), then the standardized version of y is y −µ σ in which case z has mean 0 and standard deviation 1. That is, z has the standard normal model N(0, 1), which is the black curve on the previous page. z= The N(µ, σ) curve is symmetric about µ. The N(0, 1) curve is symmetric about 0. () Exploring and Understanding Data September 26, 2011 8/1 the mean, median and mode (highest point) of this distribution is at µ the standard deviation is σ, and is also the distance from µ to the points where the curve changes from concave-down to concave-up why is this distribution so important? I good descriptions for some distributions of real data I good approximations to results of many chance outcomes F F F I scores on tests, biological characteristics such as lengths, yields, etc. number of heads in 40 tosses of a coin see Central Limit Theorem (CLT) many statistical inference procedures developed for the normal work well for other approximately symmetric distributions many variables do not have normal distributions I I I time until first goal in a hockey game incomes of Canadians (both of these have distributions which are skewed to the right) Areas under the normal curve to the left of c, or between c and d are known as probabilities. They cannot be calculated by hand. () Exploring and Understanding Data September 26, 2011 9/1 Evaluating areas under the normal curve using normal tables. extensive tables have been prepared for the standard normal which has µ = 0 and σ = 1 these are in Appendix D, Table Z (pg. A-60-61) of the text the side margin gives the first decimal place, and the top margin gives the second Useful fact: Under standard normal curve, area to the right of c equals area to the left of −c. Examples: For a standard normal model, what is the area (probability) in each of the following intervals? 1 z < .33 (.6293) 2 z > .33 (1-.6293) 3 z > −1.63 (.0516) 4 −1.3 < z < .9 (.8159-.0968) 5 |z| < 2 (.9772-(1-.9772)) () Exploring and Understanding Data September 26, 2011 10 / 1 other normal areas (probabilities) can be obtained from this table after standardizing I subtract mean, divide by standard deviation Z = I I X −µ σ sometimes called the Z score gives the number of standard deviations X is from its mean Useful fact: The area under the N(µ, σ) curve to the left (right) of c is equal to the area under the N(0, 1) curve to the left (right) of (c − µ)/σ. () Exploring and Understanding Data September 26, 2011 11 / 1 Questions - area under the normal curve Find the area under the standard normal curve to the left of 1.28. (.90) Find the area under the standard normal curve to the right of 1.28. (.10) Find the area under the standard normal curve to the right of -1.28. (.90) Find the area under the standard normal curve to the right of -2.05. (.98) Find the area under the standard normal curve between -2.05 and 1.28. (.88) Find the area under N(1, 3) to the left of 4.84. (.9) Find the area under N(1, 3) between -5.15 and 4.84. (.88) Find the area under N(−1, 5) between -11.25 and 5.4 (.88) () Exploring and Understanding Data September 26, 2011 12 / 1 Evaluating standard normal areas using minitab. The area to the left of c under a probability model is referred to as the cumulative distribution or cumulative distribution function evaluated at c. In minitab, the area to the left of c under the standard normal distribution is evaluated as “cdf c”, where c is a real number. Find the area to the left of .33 and to the left of -1.63 under the standard normal curve. MTB > cdf .33 Cumulative Distribution Function Normal with mean = 0 and standard deviation = 1 x P( X <= x ) 0.33 0.629300 MTB > cdf -1.63 x P( X <= x ) -1.63 0.0515507 () Exploring and Understanding Data September 26, 2011 13 / 1 Some other minitab cdf examples Find the areas to the left of 1.28, -1.28, -2.05 under N(0,1) MTB > set c1 DATA> 1.28 -1.28 -2.05 DATA> end MTB > cdf c1 Cumulative Distribution Function Normal with mean = 0 and standard deviation = 1 x P( X <= x ) 1.28 0.899727 -1.28 0.100273 -2.05 0.020182 () Exploring and Understanding Data September 26, 2011 14 / 1 Minitab - area under other normal curves To get probabilities under the normal curve with mean µ and standard deviation σ, use the subcommand normal, followed by the mean, the standard deviation, and a ".". For example, the following gives probabilities to the left of 4.84 and -5.15 under the normal model with mean 1 and standard deviation 3. MTB > set c2 DATA> 4.84 -5.15 DATA> end MTB > cdf c2; SUBC> normal 1 3. Cumulative Distribution Function Normal with mean = 1 and standard deviation = 3 x 4.84 -5.15 P( X <= x ) 0.899727 0.020182 () Exploring and Understanding Data September 26, 2011 15 / 1 Percentiles of the standard normal distribution Sometimes we are given a probability and need to find the corresponding percentile of the distribution the 100 p’th percentile of the standard normal curve is that number which cuts off an area p to its left. For a standard normal, we find the probability in the table and then the corresponding Z score from the margins. For other normal distributions, we first get the Z score and then ‘untransform’ it using X = µ + σZ Example: For a standard normal random variable, find 1 the 80th percentile. I the answer satisfies P(Z ≤ z) = .8 I I from the table we find the closest probability .7995 from the margins of the table we get the corresponding z = .84 () Exploring and Understanding Data September 26, 2011 16 / 1 Find the values under N(0,1) containing the middle 50% of the area we want z such that P(−z < Z < z) = .50 there must be .25 probability in the left tail below −z, or P(Z < −z) = .25 we find the closest probability in the table .2514, and then the corresponding value -.67 from the margins we have found −z = −.67 so z = .67 and conclude that the interval containing the middle 50% goes from -.67 to .67 () Exploring and Understanding Data September 26, 2011 17 / 1 Some examples - percentiles of normal models Find the 2.5’th percentile of the standard normal curve. (-1.96) Find the 97.5th percentile of the standard normal curve. (1.96) Find the 50’th percentile of the N(0,1) distribution. (0) Find the 35’th percentile of the standard normal. (-.38) Find the 97.5’th percentile of the N(1, 3) distribution. I I I The area under N(1, 3) to the left of c is the same as the area under N(0, 1) to the left of (c − 1)/3. The 97.5th precentile of N(0, 1) is 1.96. Let 1.96 = (c − 1)/3 which means c = 1 + 3(1.96) = 6.88. Find the 50’th percentile of the N(1, 3) distribution. (1) Find the 35’th percentile of the N(−2, 7) distribution. Using the fact that the 35th percentile of N(0, 1) is -.38, we get −2 + (−.38)7 = −4.7 Useful fact: 100p’th percentile of N(µ, σ) is µ + σ(100 p’th percentile of N(0,1)) () Exploring and Understanding Data September 26, 2011 18 / 1 Normal model percentiles in minitab using invcdf The invcdf command in minitab finds the inverse cumulative distribution function. For example “invcdf .8” finds the 80’th percentile of N(0,1). To get percentiles of other normal models, you need to specify the mean and standard deviation. Find, the 80’th, 25’th, 75’th, 2.5’th, 97.5’th, 50’th, 35’th percentiles of the standard normal, and then the 35’th percentile of N(-2,7), MTB > invcdf .8 P( X <= x ) x 0.8 0.841621 MTB > set c3 DATA> .25 .75 DATA> end MTB > invcdf c3 P( X <= x ) x 0.25 -0.674490 0.75 0.674490 () Exploring and Understanding Data September 26, 2011 19 / 1 some other minitab percentile examples MTB > set c4 DATA> .025 .975 .5 .35 DATA> end MTB > invcdf c4; SUBC> end Inverse Cumulative Distribution Function Normal with mean = 0 and standard deviation = 1 P( X <= x ) x 0.025 -1.95996 0.975 1.95996 0.500 0.00000 0.350 -0.38532 () Exploring and Understanding Data September 26, 2011 20 / 1 more minitab percentiles MTB > invcdf .35; SUBC> normal -2 7. Inverse Cumulative Distribution Function Normal with mean = -2 and standard deviation = 7 P( X <= x ) x 0.35 -4.69724 Next lines transform the 35’th percentile of N(0,1) to the 35’th percentile of N(-2,7). MTB > let k1=-.38532 MTB > let k2=k1*7-2 MTB > print k2 Data Display K2 -4.69724 () Exploring and Understanding Data September 26, 2011 21 / 1 Example: Scores on the SAT verbal test, X , follow approximately the N(505, 110) distribution. How high must a student score to place in the top 10% of all students taking the test? I I we want x for which P(X > x) = .10 standardizing, we want P(Z > x − 505 ) = .10 110 or x − 505 ) = .90 110 from the tables, we find the zscore 1.28 gives P(Z < z) ≈ .9 solving x − 505 z= = 1.28 110 gives x = 505 + 110(1.28) = 645.8 P(Z < I I () Exploring and Understanding Data September 26, 2011 22 / 1 using Minitab MTB > invcdf .9; SUBC> normal 505 110. Inverse Cumulative Distribution Function Normal with mean = 505 and standard deviation = 110 P(Xă<=x) x 0.9 645.971 () Exploring and Understanding Data September 26, 2011 23 / 1 Below what mark are the lowest 20% of the students? I I the z score corresponding to probability .2 (the 20’th percentile of the standard normal model) is -.85 transforming gives the 20’th percentile of N(505,110) as X = µ + zσ = 505 + (−.85)110 = 411.5 I a common mistake is to ignore the sign of z and produce an answer greater than the mean, when the answer should be less than the mean for probabilities less than .5 () Exploring and Understanding Data September 26, 2011 24 / 1 The 68-95-99.7 rule In a normal model I I I I I I about 68% of the observations fall within 1 standard deviation of the mean about 95% of the observations fall within 2 standard deviation of the mean about 99.7% of the observations fall within 3 standard deviation of the mean If an observation is within 1 standard deviation of the mean, then the associated standardized score is in (-1,1) If an observation is within 2 standard deviations of the mean, then the associated standardized score is in (-2,2) If an observation is within 3 standard deviations of the mean, then the associated standardized score is in (-3,3) It is reasonable to assume a normal model for a data set is the shape of the data’s distribution is approximately unimodal and symmetric. This can be checked by making a histogram or a normal probability plot. () Exploring and Understanding Data September 26, 2011 25 / 1 68-95-99.7 Rule .15 2.35 13.5 68 | mu 13.5 2.35 .15 mu + sigma 95 99.7 x Figure: 3. 68-95-99.7 rule () Exploring and Understanding Data September 26, 2011 26 / 1 Example: The length of white pine needles is approximately normally distributed with mean 8 cm and standard deviation 2.5 cm. What is the probability that a needle is less than 5cm? with X the length as before P(X < 5) = P(Z < 5−8 ) = P(Z < −1.2) 2.5 from the tables of the standard normal (Table Z) P(Z < −1.2) = .1151 this is approximately what we would get from the 68-95-99.7 rule we can also get the probability using Minitab () Exploring and Understanding Data September 26, 2011 27 / 1 MTB > cdf 5; SUBC> normal 8 2.5. Cumulative Distribution Function Normal with mean = 8 and standard deviation = 2.5 a 5 P(X<=a) 0.115070 () Exploring and Understanding Data September 26, 2011 28 / 1 Example: The distribution of cholesterol in 14 year old boys is approximately normal with µ = 170 mg/dl and σ = 30 mg/dl. What proportion of boys have a cholesterol value of more than 240 mg/dl? I the level X ∼ N(170, 30), so 240 − 170 ) 30 = P(Z > 2.33) P(X > 240) = P(Z > I use symmetry to get the value from the table P(Z > 2.33) () = P(Z < −2.33) = .0099 Exploring and Understanding Data September 26, 2011 29 / 1 What is the probability that a 14 year old boy will have a cholesterol level between 160 and 230 mg/dl? I using Minitab MTB > cdf 230 k1; SUBC> normal 170 30. MTB > cdf 160 k2; SUBC> normal 170 30. MTB > print k1 k2 Data Display K1 0.977250 K2 0.369441 MTB > let k3 = k1-k2 MTB > print k3 Data Display K3 0.607809 () Exploring and Understanding Data September 26, 2011 30 / 1 Assessing Normality of a Sample a normal probability plot can be used to assess whether the data could have come from a normal distribution these plots are also called normal QQ, normal scores plots, or normal quantile plot the sorted values are plotted against the values we would expect to get if the sample came from a normal distribution a straight line in this plot indicates that the data are normally distributed outliers show up as values distant from the overall pattern curvature indicates departure from normality e.g. skewness the NSCORES command in MINITAB produces the values to be plotted against the data () Exploring and Understanding Data September 26, 2011 31 / 1 Example: Pine needles were collected by DISP students in Point Pleasant Park. The histogram and normal scores plot shows they are approximately normally distributed. 15 50 • •• • 10 5 20 length 30 10 40 •• ••• •• • • • • • • • • • •• ••• • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • •• • • • • • • • • • • • • •• • •• •• • 0 • •• 0 5 10 length () 15 -3 -2 -1 0 1 2 3 Quantiles of Standard Normal Exploring and Understanding Data September 26, 2011 32 / 1 15 5 0 10 15 20 −3 Sample Quantiles 40 30 20 1 5.6 5.7 5.8 5.9 2 3 6.0 −3 −2 −1 0 1 x Theoretical Quantiles 2 3 Histogram of x Normal Q−Q Plot 2 3 5.5 6.0 Sample Quantiles 15 10 5 5.0 0 Frequency 20 6.5 25 7.0 5.5 0 Theoretical Quantiles 10 5.4 −1 Normal Q−Q Plot 0 5.3 −2 x Histogram of x 5.3 5.4 5.5 5.6 5.7 5.8 5.9 6.0 5 50 0 Frequency 10 Sample Quantiles 30 20 0 10 Frequency 40 50 20 Example: Shown below are histograms and QQ plots for data sets which are skewed right, skewed left and with a flat peak. 5.0 5.5 6.0 6.5 7.0 −3 −2 x −1 0 1 Theoretical Quantiles Figure: 5. () Exploring and Understanding Data September 26, 2011 33 / 1 for the pine needle data MTB > nscor c1 c2 MTB > plot c1 c2 MTB > nscor c1 c2 MTB > plot c1 c2 C1 15.0+ 10.0+ 5.0+ - () * * * ** *3*2* 53625 469257 +85 66+46 8693 8375 4342 222 **2 * 2 * --------+---------+---------+---------+---------+--------C2 -2.0 -1.0 0.0 1.0 2.0 Exploring and Understanding Data September 26, 2011 34 / 1 apart from the top right, the line is pretty straight, confirming that the values could have come from a normal distribution the curvature in the normal scores plot can reveal the shape of distribution if the distribution is skewed to the right, the nscores plot curves up at both the left and the right () Exploring and Understanding Data September 26, 2011 35 / 1 MTB > hist c12 Histogram of C12 Midpoint Count 0 45 1 67 2 38 3 16 4 18 5 7 6 4 7 2 8 1 9 0 10 1 11 0 12 0 13 0 14 1 () N = 200 *********************** ********************************** ******************* ******** ********* **** ** * * * * Exploring and Understanding Data September 26, 2011 36 / 1 MTB > nscor c12 c13 MTB > plot c12 c13 15.0+ * C12 10.0+ * * ** *2* 5.0+ *32* 54432 565 88777* 677788888 0.0+ * * ****22233344556 --------+---------+---------+---------+---------+--------C13 -2.0 -1.0 0.0 1.0 2.0 () Exploring and Understanding Data September 26, 2011 37 / 1 if the distribution is skewed to the left, the nscores plot curves down at each end MTB > hist c14 Histogram of C14 N = 300 Each * represents 5 obs. Midpoint 4 6 8 10 12 14 16 18 20 Count 1 1 2 11 13 36 60 117 59 () * * * *** *** ******** ************ ************************ ************ Exploring and Understanding Data September 26, 2011 38 / 1 MTB > nscor c14 c15 MTB > plot c14 c15 C14 20.0+ 15.0+ 10.0+ 5.0+ - 3544322**** 7+++9873 3++++6 +++ 4++ +7 * *89 266 33 24* *22* * * * * --------+---------+---------+---------+---------+--------C15 -2.4 -1.2 0.0 1.2 2.4 () Exploring and Understanding Data September 26, 2011 39 / 1 if the distribution has a flatter peak than the normal, the normal scores plot curves up at the left and down at the right MTB > hist c16 Histogram of C16 Midpoint Count 0.0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1.0 15 18 21 17 18 23 24 24 16 18 6 () N = 200 *************** ****************** ********************* ***************** ****************** *********************** ************************ ************************ **************** ****************** ****** Exploring and Understanding Data September 26, 2011 40 / 1 MTB > nscor c16 c17 MTB > plot c16 c17 1.05+ C16 0.70+ 0.35+ 0.00+ **** * * *33222 3442 252 2764 375 385 785 8* 68 57* 3662 3452 2333* * * ****22 --------+---------+---------+---------+---------+--------C17 -2.0 -1.0 0.0 1.0 2.0 () Exploring and Understanding Data September 26, 2011 41 / 1 Using the pull down menus in minitab In minitab, use the following sequence of pulldown menus graph -> probability plot -> single then select the column name with the data, and click OK If almost all of the data points are within the outside blue lines, the assumption of a normal model is appropriate. In this case the right hand tail is a bit short as compared to a normal distribution (because there is an upper limit of 100 for the grades) but the fit isn’t too bad. () Exploring and Understanding Data September 26, 2011 42 / 1