Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
Discriminative Pattern Mining
By
Mohammad Hossain
Based on the paper
Mining Low-Support Discriminative Patterns
from Dense and High-Dimensional Data
by
1. Gang Fang
2. Gaurav Pandey
3. Wen Wang
4. Manish Gupta
4.Michael Steinbach
5.Vipin Kumar
What is Discriminative Pattern
• A pattern is said to be Discriminative when its
occurrence in two data sets (or in two different
classes of a single data set) is significantly
different.
• One way to measure such discriminative power
of a pattern is to find the difference between the
supports of the pattern in two data sets.
• When this support-difference (DiffSup) is greater
then a threshold the the pattern is called
discriminative.
An example
D
D
Transaction-id
Items
Transaction-id
Items
10
A, C
10
A, B
20
B, C
20
A, C
30
A, B, C
30
A, B, E
40
A, B, C, D
40
A, C, D
Pattern Support in D+ Support in D-
DiffSup
A
3
4
1
B
3
2
1
C
4
2
2
AB
2
2
0
AC
3
2
1
ABC
2
0
2
If we consider the
DiffSup =2 then
the pattern C and
ABC become
interesting
patterns.
Importance
• Discriminative patterns have been shown to be useful
for improving the classification performance for data
sets where combinations of features have better
discriminative power than the individual features
• For example, for biomarker discovery from case-control
data (e.g. disease vs. normal samples), it is important
to identify groups of biological entities, such as genes
and single-nucleotide polymorphisms (SNPs), that are
collectively associated with a certain disease or other
phenotypes
P1 = {i1, i2, i3}
P2 = {i5, i6, i7}
P3 = {i9, i10}
P4 = {i12, i13, i14}.
P
P1
P2
P3
P4
i1
i2
i3
i5
i6
i7
i9
i10 i12 i13 i14
0
1
2
1
0
0
0
1
6
7
6
C1 C2 DifSup
P1 6
0
6
P2 6
6
0
P3 3
3
0
P4 9
2
7
DiffSup is NOT
Anti-monotonic
As a result, it will
not work in Apriori
like framework.
Apriori: A Candidate Generation-and-Test Approach
• Apriori pruning principle: If there is any itemset which is
infrequent, its superset should not be generated/tested!
• Method:
– Initially, scan DB once to get frequent 1-itemset
– Generate length (k+1) candidate itemsets from length k
frequent itemsets
– Test the candidates against DB
– Terminate when no frequent or candidate set can be
generated
7
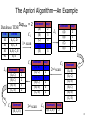
The Apriori Algorithm—An Example
Database TDB
Tid
Items
10
A, C, D
20
B, C, E
30
A, B, C, E
40
B, E
Supmin = 2
Itemset
{A, C}
{B, C}
{B, E}
{C, E}
sup
{A}
2
{B}
3
{C}
3
{D}
1
{E}
3
C1
1st scan
C2
L2
Itemset
sup
2
2
3
2
Itemset
{A, B}
{A, C}
{A, E}
{B, C}
{B, E}
{C, E}
sup
1
2
1
2
3
2
Itemset
sup
{A}
2
{B}
3
{C}
3
{E}
3
L1
C2
2nd scan
Itemset
{A, B}
{A, C}
{A, E}
{B, C}
{B, E}
{C, E}
C3
Itemset
{B, C, E}
3rd scan
L3
Itemset
sup
{B, C, E}
2
8
Pattern Support in D+
Support in D-
DiffSup
A
3
4
1
B
3
2
1
C
4
2
2
AB
2
2
0
AC
3
2
1
ABC
2
0
2
• But here we see, though the patterns AB and
AC both have DiffSup < threshold (2) their
super set ABC has DiffSup = 2 which is equal
to threshold and thus becomes interesting. So
AB, AC cannot be pruned.
BASIC TERMINOLOGY AND PROBLEM
DEFINITION
• Let D be a dataset with a set of m items, I = {i1, i2, ..., im},
two class labels S1 and S2. The instances of class S1 and S2
are denoted by D1 and D2. We have |D| = |D1| + |D2|.
• For a pattern (itemset) α = {α1,α2,...,αl} the set of instances
in D1 and D2 that contain α are denoted by Dα1 and Dα2.
• The relative supports of α in classes S1 and S2 are
RelSup1(α) = |Dα1 |/|D1| and RelSup2(α) = |Dα2 |/}D2|
• The absolute difference of the relative supports of α in D1
and D2 is denoted as
DiffSup(α) = |RelSup1(α) − RelSup2(α)|
New function
• Some new functions are proposed that has
anti-monotonic property and can be used in a
apriori like frame work for pruning purpose.
• One of them is BiggerSup defined as:
BiggerSup(α) = max(RelSup1(α), RelSup2(α)).
• BiggerSup is anti-monotonic and the upper
bound of DiffSup. So we may use it for pruning
in the apriori like frame work.
• BiggerSup is a weak upper bound of DiffSup.
• For instance, in the previous example if we want
to use it to find discriminative patterns with
thresold 4,
– P3 can be pruned, because it has a BiggerSup of 3.
– P2 can not be pruned (BiggerSup(P2) = 6), even
though it is not discriminative (DiffSup(P2) = 0).
• More generally, BiggerSup-based pruning can
only prune infrequent non-discriminative
patterns with relatively low support, but not
frequent non- discriminative patterns.
A new measure: SupMaxK
• The SupMaxK of an itemset α in D1 and D2 is
defined as
SupMaxK(α) = RelSup1(α) − maxβ⊆α(RelSup2(β)),
where |β| = K
• If K=1 then it is called SupMax1 and defined as
SupMax1(α) = RelSup1(α) − maxa∈α(RelSup2({a})).
• Similarly with K=2 we can define SupMax2 which is
also called SupMaxPair.
Properties of the SupMaxK Family
Relationship between DiffSup, BiggerSup and the
SupMaxK Family
SupMaxPair: A Special Member Suitable for
High-Dimensional Data
• In SupMaxK, as K increases we get more
complete set of discriminative patterns.
• But as K increased the complexity of
calculation of SupMaxK also increases.
• In fact the complexity of calculation of
SupMaxK is O(mK).
• So for high dimensional data (where m is
large) high value of K (K>2)makes it infeasible.
• In that case SupMaxPair can be used.