Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
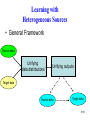
Predictive Modeling with Heterogeneous Sources Xiaoxiao Shi1 Qi Liu2 Wei Fan3 Qiang Yang4 Philip S. Yu1 1 University of Illinois at Chicago 2 Tongji University, China 3 IBM T. J. Watson Research Center 4 Hong Kong University of Science and Technology Why learning with heterogeneous sources? Standard Supervised Learning Training (labeled) Test (unlabeled) Classifier New York Times 85.5% New York Times 1/18 Why heterogeneous sources? In Reality… Training (labeled) Labeled data are New York Times insufficient! How to improve the performance? Test (unlabeled) 47.3% New York Times 2/18 Why heterogeneous sources? Labeled data from other sources Target domain test (unlabeled) 82.6% 47.3% New York Times Reuters 1. Different distributions 2. Different outputs 3. Different feature spaces 3/18 Real world examples • Social Network: – Can various bookmarking systems help predict social tags for a new system given that their outputs (social tags) and data (documents) are different? Wikipedia ODP Backflip Blink …… ? 4/18 Real world examples • Applied Sociology: – Can the suburban housing price census data help predict the downtown housing prices? ? #rooms #bathrooms #windows price #rooms #bathrooms #windows price 5 2 12 XXX 2 1 4 XXXXX 6 3 11 XXX 4 2 5 XXXXX 5/18 Other examples • Bioinformatics – Previous years’ flu data new swine flu – Drug efficacy data against breast cancer drug data against lung cancer – …… • Intrusion detection – Existing types of intrusions unknown types of intrusions • Sentiment analysis – Review from SDM Review from KDD 6/18 Learning with Heterogeneous Sources • The paper mainly attacks two subproblems: – Heterogeneous data distributions • Clustering based KL divergence and a corresponding sampling technique – Heterogeneous outputs (to regression problem) • Unifying outputs via preserving similarity. 7/18 Learning with Heterogeneous Sources • General Framework Source data Unifying data distributions Unifying outputs Target data Source data Target data 8/18 Unifying Data Distributions • Basic idea: – Combine the source and target data and perform clustering. – Select the clusters in which the target and source data are similarly distributed, evaluated by KL divergence. 9/18 An Example D T Adaptive Clustering Combined Data 10/18 Unifying Outputs • Basic idea: – Generate initial outputs according to the regression model – For the instances similar in the original output space, make their new outputs closer. 11/18 Initial Outputs Initial Outputs 37 31.75 26.5 21.25 16 12/18 Experiment • Bioinformatics data set: 13/18 Experiment 14/18 Experiment • Applied sociology data set: 15/18 Experiment 16/18 Conclusions • Problem: Learning with Heterogeneous Sources: • Heterogeneous data distributions • Heterogeneous outputs • Solution: • Clustering based KL divergence help perform sampling • Similarity preserving output generation help unify outputs 17/18 Thanks! 18/18