Survey
* Your assessment is very important for improving the workof artificial intelligence, which forms the content of this project
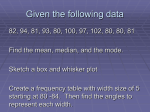
SOC 2105 – ELEMENTS OF SURVEY SAMPLING AND SOCIAL STATISTICS LECTURE NOTES LECTURE FIVE – November 5, 2015 Continuous Random Variables and their probability Distributions A continuous random variable can assume any value over an interval or intervals. Because the number of values contained in any interval is infinite, the possible number of values that a continuous random variable can assume is also infinite. Moreover, we cannot count these values. The normal curve is a concept of great importance in statistics. In combination with the mean and standard deviation, it is used to make precise descriptive statements about empirical distributions. Also, the normal curve is central to the theory that underlies inferential statistics. Thus, this lecture concludes our treatment of Descriptive Statistics and lays important groundwork for Inferential Statistics. Properties of the Normal Curve The normal curve is a theoretical model, a kind of frequency polygon, or line chart, that is unimodal (i.e., has a single mode, or peak), perfectly smooth, and symmetrical (unskewed), so its mean, median, and mode are all exactly the same value. It is bell-shaped, and its tails extend infinitely in both directions. Of course, no empirical distribution matches this ideal model perfectly, but some variables (e.g., test results from large classes, standardized test scores such as the GRE) are close enough to permit the assumption of normality. In turn, this assumption makes possible one of the most important uses of the normal curve—the description of empirical distributions based on our knowledge of the theoretical normal curve. The crucial point about the normal curve is that distances along the horizontal axis, when measured in standard deviations from the mean, always encompass the same proportion of the total area under the curve. In other words, the distance from any point to the mean—when measured in standard deviations—will cut off exactly the same part of the area under the curve. The probability distribution of a continuous random variable possesses the following two characteristics. 1. The probability that x assumes a value in any interval lies in the range 0 to 1. 2. The total probability of all the (mutually exclusive) intervals within which x can assume a value is 1.0. The probability that a continuous random variable x assumes a value within a certain interval is given by the area under the curve between the two limits of the interval, as shown in Figure 6.5. The shaded area under the curve from a to b in this figure gives the probability that x falls in the interval a to b; that is, P(a <x <b) = Area under the curve from a to b Note that the interval a < x < b states that x is greater than or equal to a but less than or equal to b. The probability that a continuous random variable x assumes a single value is always zero. This is so because the area of a line, which represents a single point, is zero. For example, if x is the height of a randomly selected female student from that university, then the probability that this student is exactly 67 inches tall is zero; that is, This probability is shown in Figure 6.7. Similarly, the probability for x to assume any other single value is zero. In general, if a and b are two of the values that x can assume, then P(a) = 0 and P (b)= 0 The mean, µ, and the standard deviation, ð, are the parameters of the normal distribution. Given the values of these two parameters, we can find the area under a normal distribution curve for any interval. Remember, there is not just one normal distribution curve but a family of normal distribution curves. Each different set of values of µ and ð The value of µ determines the center of a normal distribution curve on the horizontal axis, and the value of ð gives the spread of the normal distribution curve. The standard normal distribution is a special case of the normal distribution. For the standard normal distribution, the value of the mean is equal to zero, and the value of the standard deviation is equal to 1. Males s =20 N = 1000 X = 100 Females s = 10 N =1000 X = 100 For example, for the males, an IQ score of 120 is one standard deviation (remember that, for the male group, s _ 20) above the mean and an IQ of 140 is two standard deviations above (to the right of) the mean. Scores to the left of the mean are marked as negative values because they are less than the mean. An IQ of 80 is one standard deviation below the mean, an IQ score of 60 is two standard deviations less than the mean, and so forth. For the female sample, one standard deviation above the mean is an IQ of 110, one standard deviation below the mean is an IQ of 90, and so forth. Recall that, on any normal curve, distances along the horizontal axis, when measured in standard deviations, always encompass exactly the same proportion of the total area under the curve. Specifically, the distance between one standard deviation above the mean and one standard deviation below the mean (or ±1 standard deviation) encompasses exactly 68.26% of the total area under the curve. This means that 68.26% of the total area lies between the score of 80 (-1 standard deviation) and 120 (+1 standard deviation). The standard deviation for females is 10, so the same percentage of the area (68.26%) lies between the scores of 90 and 110. On any normal distribution, 68.26% of the total area will always fall between ±1 standard deviation, regardless of the trait being measured and the number values of the mean and standard deviation. z Values or z Scores The units marked on the horizontal axis of the standard normal curve are denoted by z and are called the z values or z scores. A specific value of z gives the distance between the mean and the point represented by z in terms of the standard deviation. Think of converting the original scores into Z scores as a process of changing value scales— similar to changing from meters to yards, kilometers to miles, or gallons to liters. These units are different but equally valid ways of expressing distance, length, or volume. For example, a mile is equal to 1.61 kilometers, so two towns that are 10 miles apart are also 16.1 kilometers apart and a “5k” race covers about 3.10 miles. Although you may be more familiar with miles than kilometers, either unit works perfectly well as a way of expressing distance. In the same way, the original (or “raw”) scores and Z scores are two equally valid but different ways of measuring distances under the normal curve. The z values on the right side of the mean are positive and those on the left side are negative. The z value for a point on the horizontal axis gives the distance between the mean and that point in terms of the standard deviation. For example, a point with a value of z = 2 is two standard deviations to the right of the mean. Similarly, a point with a value of z = -2 is two standard deviations to the left of the mean. The standard normal distribution table, Table IV of Appendix C, lists the areas under the standard normal curve to the left of z values from to 3.49. To read the standard normal distribution table, we look for the given z value in the table and record the value corresponding to that z value. Find the area under the standard normal curve to the left of Solution We divide the given number 1.95 into two portions: 1.9 (the digit before the decimal and one digit after the decimal) and .05 (the second digit after the decimal). (Note that To find the required area under the standard normal curve, we locate 1.9 in the column for z on the left side of Table IV and .05 in the row for z at the top of Table IV. The entry where the row for 1.9 and the column for .05 intersect gives the area under the standard normal curve to the left of. From the table the entry where the row for 1.9 and the column for .05 cross is .9744. Consequently, the area under the standard normal curve to the left of is .9744. (It is always helpful to sketch the curve and mark the area you are determining.) Find the area under the standard normal curve from to z = -2.17 to z = 0. Solution To find the area from to first we find the areas to the left of and to the left of in the standard normal distribution table. As shown in Table 6.3, these two areas are .5 and .0150, respectively. Next we subtract .0150 from .5 to find the required area. Converting X values to Z scores 1: Subtract the value of the score (Xi) from the value of the mean. 2: Divide the quantity found in step 1 by the value of the standard deviation (s). The result is the Z-score equivalent for this raw score. For you to do: Let x be a continuous random variable that has a normal distribution with a mean of 50 and standard deviation of 8. Find the probability P(30 ≤ x ≤ 39). Let x be a continuous random variable that has a normal distribution with a mean of 80 and a standard deviation of 12. Find the area under the normal distribution curve (a) from x =70 to x =135 (b) to the left of 27 Application question Suppose the life span of a calculator manufactured by Texas Instruments has a normal distribution with a mean of 54 months and a standard deviation of 8 months. The company guarantees that any calculator that starts malfunctioning within 36 months of the purchase will be replaced by a new one. About what percentage of calculators made by this company are expected to be replaced? According to the 2007 American Time Use Survey by the Bureau of Labor Statistics, employed adults living in households with no children younger than 18 years engaged in leisure activities for 4.4 hours a day on average (Source: http://www.bls.gov/news.release/atus.nr0.htm). Assume that currently such times are (approximately) normally distributed with a mean of 4.4 hours per day and a standard deviation of 1.08 hours per day. Find the probability that the amount of time spent on leisure activities per day for a randomly chosen individual from the population of interest (employed adults living in households with no children younger than 18 years) is a. between 3.0 and 5.0 hours per day b. less than 2.0 hours per day