Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
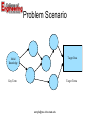
Query Planning for Searching InterDependent Deep-Web Databases Fan Wang1, Gagan Agrawal1, Ruoming Jin2 1 2 Department of Computer Science and Engineering Ohio State University, Columbus, OH 43210 Department of Computer Science Kent State University, Kent, OH 44242 [email protected] Introduction • The emerge of deep web – Deep web is huge – Different from surface web – Challenges for integration • Not accessible through search engines • Inter-dependences among deep web sources [email protected] Motivation Example Given a gene ERCC6, we want to know the amino acid occurring in the corresponding position in orthologous gene of nonhuman mammals ERCC6 Entrez Gene dbSNP AA Positions for Nonsynonymous SNP Encoded Protein Alignment Database Protein Sequence Sequence Database Encoded Orthologous Protein [email protected] Observations • • • • Inter-dependences between sources Time consuming if done manually Intelligent order of querying Implicit sub-goals in user query [email protected] Contributions • Formulate the query planning problem for deep web databases with dependences • Propose a dynamic query planner • Develop cost models and an approximate planning algorithm • Integrate the algorithm with a deep web mining tool [email protected] Roadmap • • • • • • Introduction and Motivation Problem Formulation Planning Algorithm Evaluation Related Work Conclusion [email protected] Formulation • Universal Term Set T {t1 , t2 ,..., tn } • Query Q is composed of two parts – Query Key Term: focus of the query (ERCC6) – Query Target Terms: attributes of interesting (Alignment) • Data sources – Each data source D covers an output set – Each data source D requires an input set • Find a query plan, a ordered list of data sources – Covers the query target terms with maximal benefit – As short as possible – NP-Complete problem [email protected] Problem Scenario Target Data Initial Knowledge Key Term Target Terms [email protected] Production System • • • • Working Memory Target Space Production Rules Recognize-Act Control R2 R1 Working Key Memory Term Intermed Working iate Memory Result Database 1 R3 Working Intermediate Memory Result Database 2 Database 3 [email protected] Working Target Terms Final Result Target Memory Roadmap • • • • • • Introduction and Motivation Problem Formulation Planning Algorithm Evaluation Related Work Conclusion [email protected] Algorithm • Dependency Graph • Planning Algorithm Detail • Benefit Model [email protected] Dependency Graph • Dependency relation – Format: {Di , Di 1 ,..., Di m } – Hypergraph DR DR Dj • Hyperarc: ordered pair (parents, child) • AND node • Neighbors [email protected] Concepts • Database Necessity (DN) – Each term is associated with a DN value – Measures the extraction priority of a term and the importance of a database scheme – For term t, if k database schemes can provide 1 it, the DN value is k [email protected] Concepts • Hidden Nodes – Nodes connecting current working state and the target space • Partially Visualize Hidden Nodes – Multiple layers of hidden nodes bring difficulty [email protected] Visualize Hidden Nodes • Target Space Enlargement Target Space: {t1,t2,t3} {t1,t2,t3,t4,t5} {t1,t2,t3,t4} {t1} 1. Find a target term t with DN=1 D2 D4 D7 2. Visualize the database D which provides t D1 D6 D3 D5 3. Add D’s input set to target space D8 4. Repeat above steps till done [email protected] Planning Algorithm Detail [email protected] Planning Algorithm Detail • The approximation ratio of our greedy algorithm is [email protected] Benefit Model • Select an appropriate rule at each iteration of the planning algorithm • Four metrics – Database Availability – Data Coverage (DC) – User Preference (UP) – Potential Importance (PI) [email protected] Data Coverage • The number of query target terms covered by the current rule, but has not yet been covered by previous selected rules [email protected] User Preference • Domain users have preference for certain database (rule) for a particular term • A collaborating biologist provides the preference values • Term t provided by r databases r 0 UPt 1, UPt i 1 i i 1 • Rule R covers the following unfound target terms – Preference for R is [email protected] Potential Importance • Some database is more important due to its linking to other important databases (e.g.) • A database D is more important – Find the necessary databases which provide unfound target terms – More such necessary databases can be reached from D • The potential importance for a rule [email protected] Roadmap • • • • • • Introduction and Motivation Problem Formulation Planning Algorithm Evaluation Related Work Conclusion [email protected] Experiment Setup • SNPMiner System – Integrates 8 deep web databases – Provides a unified user interface • Experimental Queries [email protected] Planning Algorithm Comparison • Naïve Algorithm (NA) – Select all rules which can be fired at each iteration until all requested terms are covered – No rule selection strategy used • Optimal Algorithm (OA) – Search the entire space • Production Rule Algorithm (PRA) [email protected] PRA vs. NA Query Plan Execution Time Comparison ETRatio(Production/Naive) 1.2 1 Ratio 0.8 0.6 0.4 0.2 0 0 5 10 15 Queries 20 1. All ratio data points smaller than 1 2. PRA generates much faster query plans than NA [email protected] 25 30 PRA vs. OA Query Plan Execution Time Comparison Ratio ETRatio(Production/Optimal) 1.6 1.4 1.2 1 0.8 0.6 0.4 0.2 0 0 5 10 15 Queries 20 25 30 1. All ratio data points distributed around 1 2. In terms of query plan execution time, PRA has performance close to OA 3. In most cases, PRA generates exactly the same plan as OA [email protected] Enlarge Target Space Execution Time Comparison With Enhancement Without Enhancement 500 Time (s) 400 300 200 100 0 1 2 3 4 5 Queries 6 7 1. Query plans generated with enlargement run faster 2. Query plans generated with enlargement are shorter [email protected] 8 Scalability Our system has good scalability [email protected] Roadmap • • • • • • Introduction and Motivation Problem Formulation Planning Algorithm Evaluation Related Work Conclusion [email protected] Related Work • Query Planning – Navigational based query planning – SQL based query planning – Bucket Algorithm • Deep Web Mining – Database selection – E-commerce oriented, no dependency • Keyword Search on Relational Databases • Select-Project-Join Query Optimization [email protected] Conclusion • Formulate and solve the query planning problem for deep web databases with dependencies • Develop a dynamic planning algorithm with an approximation ratio of ½ • Our benefit model is effective • Our algorithm outperforms the naïve algorithm, and obtains optimal results for most cases [email protected] Questions/Comments? [email protected]