Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
STANDARDIZED SCORES
AND
HYPOTHESIS TESTING
Standardized Scores
●
●
How do we compare results coming from
different samples?
e.g.: Two students from 2 classes
compare their exam result:
S1, S2 = 70
but
C1 = 60, std1 = 5
C2 = 60, std2 = 20
The Z-Score
How many standard deviation is the measure from
the (sample) mean?
X 0− X
z=
s
z scores (being a ratio) are not associated with any
unit of measure
z scores provide a “neutral” way to compare raw
scores from different distributions
Properties of Z-Score
Given a complete set of z scores:
●
converting a set of raw scores into z-scores does
not change the shape of the original distribution
●
the mean of z-scores is zero
●
the standard deviation of z-scores is one
●
the comparison of z-scores is reasonable only if the
distributions are similar in shape
Normal Distribution
When we deal with symmetric sample distributions it
is useful to approximate them with the bell-shaped
distribution (aka Gaussian or Normal Distribution).
It is well understood and has practical mathematical
properties.
Mean and standard deviation are the two parameters
defining the position and width of the curve.
We can define a family of distribution which differ
each-other by mean and standard deviation: all
have the same shape!
The Standard Normal Distribution
g=
1
2
⋅e
2
− X−2
2
2
=0,=1
Some Properties
●
●
●
●
●
The area under the curve is 1
there is a strong relationship between area
under the curve and probability
We can calculate e.g. what is the probability of
having a hight within the mean and +1 std,...
we can calculate the likelihood that a sample
will lie within a certain values
but, we can not calculate the probability for a
single value, only ranges!
e.g.: what is the probability of a heigth of 108.98 cm ?
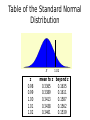
Table of the Standard Normal
Distribution
X
z
0.98
0.99
1.00
1.01
1.02
1.02
mean to z beyond z
0.3365
0.1635
0.3389
0.1611
0.3413
0.1587
0.3438
0.1562
0.3461
0.1539
an example: finding a raw score
corresponding to a given area
To join the rugby team you need a weigth in the top 16%
of the population (first year male alumni).
If the weigths are normaly distribuited, mean 85, sd 21,
what weigth is required?
w
w0
some notes on probability
●
●
Probability ranges from 0 (event does not occur)
to 1 (event certainly occur) (or 0% to 100%)
–
Tossing of a single coin: P(H) = ?, P(T) =?
–
One roll of a dice P(1) = ?,...
Independent events
–
●
Tossing of two coins P (H and T) = P(H)*P(T)
Mutually exclusive events
–
Rolling one dice P(1 or 6) = P(1)+P(6) = ?
some notes on probability
If one tenth of the people in the world are
Chinese,one twentieth are Indian, and half are
male, what is P (Chines or Male)? P(Chinese and
Male)?
●
Not Mutually exclusive events
–
P(A or B) = P(A)+P(B) – P (A and B)
–
P(A and B) = P(A)* P(B|A) p. B given A
Sampling with replacement vs without replacement
Sampling Distribution of the Mean
●
●
●
●
Tipically experiments are designed considering
groups of subjects, rather than single subjects
We wish that the sample rapresents the
underlyong population
but, how do I evaluate groups (aka samples)?
answer: comparing the sample mean with a
distribution: the sampling distribution of the
mean!
Sampling Distribution of the Mean
●
●
could be found by taking many samples
from a population an gather the sample
means into a distribution
We may use a sample of 10 subjects and
repeat the experimetn 100 times, with
different 10 subjects each time
... its properties
if population distribution normal,
if samples are independent and random
if samples have the same size
then it is a normal distribution centered in μ and
deviation (aka the standard error of the mean)
equal to:
X =
N
What happens when N increases?
... increasing N
the sampling distribution of the mean
approaches a normal distribution as N
gets big!
The Central Limit Theorem
For ANY population that has mean μ and
standard deviation σ, the distribution of
sample
means
(each
based
on
N
independent observations – aka sample
size) will approach a normal distribution
with mean μ and standard deviation of
σ/sqrt(N)
Introduction to Hypothesis Testing
Basic Hypothesis Testing
Basic Idea: we do an experiment and obtain a result,
x. What is the probability that this arose by
chance?
Fictitious example: Mathematical aptitude is
measured in the USA using SAT scores, mean 500,
and standard deviation of 100.
A person (psychic) declares that can predict
mathematical aptitude based on reading auras.
He selects 25 people who he claims will have higher
average math aptitude. The average aptitude in
this group is 530.
●
Is he psychic? Is this result statistically significant?
The Skeptic:
the Null Hypothesis
Dr Null is always the first to examine your results
and always claims that you obtained your result
by chance.
His hypothesis:It is highly unlikely that any
sample of 25 will have a mean SAT of exactly
500. About half the time it will be higher, and
half the time it will be lower!
How do we decide?
How much risk do we take in rejecting Dr Null’s
case?
peculiarities of the expetiment
●
●
●
representative random sample
samples are independent (choosing P1
does not affect the choice of P2)
mean and standard deviation of the
population are known (500, 100)
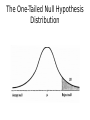
The Null Hypothesis Distribution
●
●
What are Dr.Null's chances of doing
better?
Let's start calculating our z score and the
associated probability (beyond)!
−
X
z=
x
POPULATION mean = 500, standard deviation = 100
our result with 25 subjects= 530
x =?
the p-level
The probability of Dr.Null beating us is ...
about 7 % (0.0668)
... and now?
The alpha-level
●
●
●
●
●
The alpha-level corresponds to the ammount of
risk we are prepared to take
it is defined before!
Rule of Thumb: reviewers will take you seriously
if Dr. Null chances are less than 1:20!
alpha = 0.05! (5%)
if p > alpha, the Null Hypothesis can not be
rejected! Our result is not statistically relevant!
The One-Tailed Null Hypothesis
Distribution
The z-Score as Test Statistic
●
●
is based on one or more sample statistics (e.g.
the sample mean)
follows a well defined distribution (e.g. gaussian
curve)
●
large z-scores -> lower p-level
●
in practical applications
–
p values are not exactly reported (e.g. p <
{0.05, 0.001})
–
large z-score are higly desiderable
–
but large z are easier to get with large
samples!
The Real Risk: Type I and Type II Errors
●
What if Dr. Null was right and we rejected its
hypothesis?
–
●
We may have got luky, leading to a p < 0.05
What if Dr. Null was wrong and we accepted its
hypothesis?
TYPE I aka false positive
or false alarm
TYPE II aka false negative
or miss
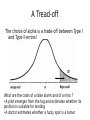
A Tread-off
The choice of alpha is a trade-off between Type I
and Type II errors!
What are the costs of a false alarm and of a miss ?
•A pilot emerges from the fog and estimates whether its
position is suitable for landing
•A doctor estimates whether a fuzzy spot is a tumor
One- and Two-Tailed Tests
What about a psychic for math inaptitude?
What about people with “normal” math skills?
We must be open to scores either larger or smaller!
The p-level for a two tailed test is
twice the p-level for a one-tiled test!
When?
●
●
No universal rule, but...
one-tailed tests are used only in the light
of strong previous research, theoretical or
logical considerations
–
●
What if we place alpha in the wrong tail?
Two-tailed tests make a bit harder to
reach statistical significance (half alpha in
the lower tail, and half in the higher tail),
thus preferred.
Simple Hypothesis Testing
●
State the Hypothesis
–
Define the Null
–
and alternative
●
Select test of significance
●
Get DATA
●
Find region of rejection
●
Calculate test statistic (z) and compare
●
Interpret the results!
An example
●
●
●
Problem: Does depression in children
affect growth functions?
Hypothesis: LLD (life-long depressives)
woman are shorter than average
Null Hypothesis: LLD woman are not
shorter than average (hopefully wrong)
H 0 : =0
H A : ≠0
two-tails test
H A : 0
one-tails test
...
●
●
●
statistical test: compare the mean of a
single sample to population mean
(standard deviation is known) -> onesample z-test
significance level: alpha = 0.05 (or 0.01,
...)
data:
–
the more the better!!!!(type II error goes
down, type I is defined by alpha).
...
●
the rejection region
–
we test the null hypothesis:
mean = 0 and sigma = 1!
alpha = 0.05!
●
the test statistic
–
calculate the mean of the sample and verify:
∣z∣=
∣ X −0 ∣
x
z c
to beat the null hypothesis
INTERPRET YOUR RESULTS!
(e.g. we can not rule out that a third factor
infuences height and depression!)
One-Sample z-Test:
Assumptions
●
●
●
The sample is drawn randomly
the variable measured is normally
distributed in the population
the standard deviation of the sample is
the same as the standard deviation of the
population