Survey
* Your assessment is very important for improving the workof artificial intelligence, which forms the content of this project
The Bootstrap
Econometrics III Lecture Notes
Ke-Li Xu
Indiana University
September 13, 2019
Ke-Li Xu (Indiana University)
Bootstrap
September 13, 2019
1 / 47
Contents
Bootstrap bias correction
Bootstrap standard error
Bootstrap coe¢ cient-based test (and CI)
Bootstrap t-test (and percentile-t CI)
Example: linear regression model
I
I
I
I
Pairwise bootstrap and residual-based bootstrap
Restricted bootstrap
Bootstrapping F test
Parametric bootstrap
Permutation test
Bootstrap: Improve oneself by one’s own e¤orts
Ke-Li Xu (Indiana University)
Bootstrap
September 13, 2019
2 / 47
Bootstrap bias correction
Suppose the parameter of interest is θ.
The bias of an estimator b
θ is
τ = Eb
θ
θ.
E.g. θ can be a linear regression coe¢ cient, when the strict exogeneity
assumption is not satis…ed.
If τ is known, then we can construct an (infeasible) bias-corrected estimator
of θ :
bc ,inf
b
θ
= bθ τ.
bc ,inf
bc ,inf
b
θ
is unbiased: E b
θ
= θ.
We now want to estimate τ. The bootstrap provides a solution.
Ke-Li Xu (Indiana University)
Bootstrap
September 13, 2019
3 / 47
Suppose the (raw) data are fZ1 , ..., Zn g, coming from the unknown
distribution F .
We can rewrite (making the dependence on F explicit)
τ = τ ( F ) = EF b
θ
θ (F ).
E.g. in the linear regression yi = xi0 θ + ui ,
θ = θ (F ) = (EF xi xi0 ) 1 EF xi yi .
The idea of bootstrap is to approximate F by Fb , the empirical CDF of the
data:
n
Fb (z ) = n 1 ∑ I (Zi
z ).
i =1
Intuitively, Fb assigns the probability mass 1/n to each data point Zi .
Thus τ is estimated by τ (Fb ).
Ke-Li Xu (Indiana University)
Bootstrap
September 13, 2019
4 / 47
Denote the moments under Fb as E ( ), Var ( ), etc.
De…ne b
θ to be like b
θ, but in terms of data coming from Fb (instead of the
original data, which come from F ).
What is τ (Fb ) then?
τ (F )
τ (Fb )
= EF bθ
= E bθ
θ (F )
θ (Fb ) = E b
θ
b
θ.
Here we have used θ (Fb ) = b
θ, which is typically true in econometrics when b
θ
is an MM (method of moments) estimator.
E.g. in the linear regression,
θ (Fb )
b
θ
= ( E xi xi 0 )
1
n
E xi yi = ( ∑ xi xi0 ) 1
i =1
n
= ( ∑ xi xi 0 )
i =1
1
∑ xi yi ,
i =1
n
∑ xi yi ,
i =1
where random variables (yi , xi 0 )0 are from Fb .
A resampling approach is needed to obtain E b
θ .
Ke-Li Xu (Indiana University)
n
Bootstrap
September 13, 2019
5 / 47
θ by taking many random draws from the data.
Bootstrap: Approximate E b
I
I
I
Take n random draws (with replacement) from the raw data. These n draws
are called a bootstrap sample: fZ1 , ..., Zn g.
Repeat doing this B times. So we have B bootstrap samples:
fZ1 (b ), ..., Zn (b )g, b = 1, ..., B .
For each bootstrap sample, compute b
θ (b ), where b
θ (b ) is just like b
θ except
that the sample fZ1 (b ), ..., Zn (b )g, instead of the raw data, is used.
B should be large, so that the distribution of fb
θ (b ) : b = 1, ..., B g well
approximates the distribution of b
θ .
Ke-Li Xu (Indiana University)
Bootstrap
September 13, 2019
6 / 47
Then
E b
θ
1 B b
b
θ ,
θ (b )
B b∑
=1
So de…ne the estimator of τ as b
τ:
τ (Fb ) = E b
θ
b
θ
b
θ,b
τ
b
θ
The bias-corrected estimator of b
θ is formed as
bc
b
θ =b
θ
b
τ = 2b
θ
b
θ .
Lastly, on a theoretical note, the approximation of F using Fb is justi…ed by
Glivenko-Cantelli Theorem: if Zi is iid,
sup jFb (z )
z
Ke-Li Xu (Indiana University)
Bootstrap
p
F (z )j ! 0.
September 13, 2019
7 / 47
Bootstrap standard errors
The bootstrap method estimates the …nite-sample variance of b
θ (i.e. Var(b
θ))
by:
Var (b
θ ).
After re-sampling the data B times, Var (b
θ ) is appximated by
Vbθboot =
B
1
B
∑ (bθ
1 b =1
(b )
b
θ )(b
θ (b )
b
θ )0 .
Vbboot is called the bootstrap variance estimator.
θ
Bootstrap standard error (if θ is a scalar)
SEbθboot =
Ke-Li Xu (Indiana University)
h
B
b
B 1 ∑ b =1 ( θ (b )
1
Bootstrap
b
θ )2
i1 /2
.
September 13, 2019
8 / 47
Bootstrap test (coe¢ cient-based)
In the bias correction above, we use the re-sampling to approximate a
moment
b
E (b
θ
θ ).
In fact, the distribution of b
θ
Ke-Li Xu (Indiana University)
b
θ can be also useful.
Bootstrap
September 13, 2019
9 / 47
Consider a generic scalar parameter θ.
In the regression setting, θ can be βj (the j-th slope).
Consider H0 : θ = θ 0 .
For an estimator b
θ, based on the asymptotic normality result
d
0
1
/
2
n (b
θ θ ) ! N (0, v 2 ) (if the null is true), we have
n1 /2 (b
θ
θ0 )
Asy .
where vb is an estimator of v .
N (0, vb2 ),
(1)
The bootstrap provides an alternative way of approximating the
(…nite-sample) distribution of n1 /2 (b
θ θ 0 ), instead of using N (0, vb2 ), as in
(1).
Ke-Li Xu (Indiana University)
Bootstrap
September 13, 2019
10 / 47
θ θ 0 ) is Gn (F ), where F is the true
Denote the true distribution of n1 /2 (b
CDF behind the data. Note that both b
θ and θ 0 (true value, if the null holds)
depend on F .
If we know Gn (F ), then we calculate its lower and upper quantiles, so that a
test can be formed.
But in general, Gn (F ) is unknown
Two methods to approximate Gn (F ):
I
I
the asymptotic method (using G∞ (F ))
the bootstrap method (using Gn (Fb )), where Fb is the empirical CDF of the
data. [This is commonly referred to as the nonparametric bootstrap.]
n 1/2 (b
θ
n
The distribution of n1 /2 (b
θ
Ke-Li Xu (Indiana University)
1/2
(bθ
θ0 )
exact
G n (F )
exact
b
θ)
Gn (Fb )
b
θ ) is obtained by re-sampling.
Bootstrap
September 13, 2019
11 / 47
Algorithm (a bootstrap test for θ = θ 0 )
Suppose the (raw) data are fZ1 , ..., Zn g.
As before, we generate B bootstrap samples: fZ1 (b ), ..., Zn (b )g,
b = 1, ..., B.
For each bootstrap sample, compute b
θ (b ).
N Let q (α) be the α th quantile of {n1 /2 (bθ (b )
b
θ ), b = 1, ..., B g. N
Two-sided test: Reject H0 at level 5% if
n1 /2 (b
θ
θ 0 ) > q (0.975)
or n1 /2 (b
θ
θ 0 ) < q (0.025).
(2)
One-sided test (e.g. H0 : θ = θ 0 vs. HA : θ > θ 0 ): Reject H0 at level 5% if
n1 /2 (b
θ
Ke-Li Xu (Indiana University)
θ 0 ) > q (0.95).
Bootstrap
September 13, 2019
12 / 47
d
We need θ 0 be the true value (under H0 ) for n1 /2 (b
θ θ 0 ) ! N (0, v 2 ) to
hold.
In the bootstrap world, b
θ is the true value. Thus θ 0 has no role in the
bootstrap statistic:
n1 /2 (b
θ (b ) b
θ ).
A common mistake is to use n1 /2 (b
θ
I
I
θ 0 ) as the bootstrap statistic.
If so, the critical value would also change with θ 0 (note that n 1/2 (b
θ θ0 )
changes with θ 0 ), thereby the test may have no power.
[we will revisit this point later when we show the bootstrap test is consistent
(i.e. the power goes to one under the alternative)]
This coe¢ cient-based bootstrap test (and the induced con…dence interval (3)
below) has the advantage of not having to estimate the standard error.
Ke-Li Xu (Indiana University)
Bootstrap
September 13, 2019
13 / 47
The advantage of bootstrap is that we can easily take random draws from Fb
as many as we want. (We can only take one random draw from F , i.e. the
original data in hand).
The asymptotic validity is usually shown like this:
Gn (F )
Goal
&
G∞ (F )
Asym.
Gn (Fb )
Bootstrap
%
Thus, in order to approximate Gn (F ), the asymptotic method and bootstrap
are …rst-order equivalent.
Ke-Li Xu (Indiana University)
Bootstrap
September 13, 2019
14 / 47
Note that for each method, we need another approximation.
I
I
For the asymptotic method, we estimate the asymptotic variance.
For bootstrap, we draw B samples (requiring B to be large).
Fb is referred to as the bootstrap world (F is the world we want to learn
about).
In the bootstrap world, b
θ (b ) b
θ is one draw.
The main advantage of the bootstrap procedure above is that we don’t need
to derive G∞ (F ). In many cases, we don’t need to estimate the asymptotic
variance v 2 .
Ke-Li Xu (Indiana University)
Bootstrap
September 13, 2019
15 / 47
Bootstrap con…dence interval (coe¢ cient-based)
The 95% CI is obtained by inverting the test (2) (collecting all values which
can not be rejected).
θ θ ) q (0.975)g, or
We then have fθ : q (0.025) n1 /2 (b
b
θ
n 1 /2 q (0.975)
θ
b
θ
n 1 /2 q (0.025).
(3)
The CI (3) has correct asymptotic coverage 95%.
Ke-Li Xu (Indiana University)
Bootstrap
September 13, 2019
16 / 47
Percent CI
A commonly-used bootstrap CI is formed by simply using lower and upper
quantiles of fb
θ (b ) : b = 1, ..., B g.
This is called percentile CI.
The percentile CI can be writtten as
θ 2 [b
θ + n 1 /2 q (0.025), b
θ + n 1 /2 q (0.975)].
(4)
It is important to note that the CI (4) is in general di¤erent from (3). They
are the same only if the bootstrap distribution is symmetric around zero (so
that q (0.025) = q (0.975)).
Asymptotic justi…cation of the percentile CI needs G∞ (F ) to be symmetric.
Thus the CI (3) is a preferred choice.
Ke-Li Xu (Indiana University)
Bootstrap
September 13, 2019
17 / 47
We now show that the percent CI has the claimed coverage asymptotically if
symmetry is assumed.
Suppose
n1 /2 (b
θ
n1 /2 (b
θ
d
θ ) ! ξ,
(5)
d
b
θ ) ! ξ.
(6)
Assume that the distribution of ξ is symmetric around zero. (e.g. consider a
regression model, then ξ is normal.)
In our previous notation, ξ is G∞ (F ).
Then
P
θ 2 Percentile CI
b
θ + n 1 /2 q (0.025)
=
P
=
!
P
q (0.975)
P ( qξ (0.975)
=
P (qξ (0.025)
symmetry
Ke-Li Xu (Indiana University)
θ
b
θ + n 1 /2 q (0.975)
n1 /2 (b
θ θ)
q (0.025)
ξ
qξ (0.025))
ξ
Bootstrap
qξ (0.975)) = 0.95.
September 13, 2019
18 / 47
Consistency of the bootstrap test
Under a particular model, showing both (5) and (6) (with the same ξ)
implies the bootstrap validity (asymptotically), i.e. the distribution of
b
n1 /2 (b
θ θ ) can be approximated by the distribution of n1 /2 (b
θ
θ ).
We will showcase this for di¤erent models later in the class (e.g. (7) below).
We can also show that the bootstrap test is consistent.
Suppose H0 : θ = θ 0 is wrong. That means θ true 6= θ 0 .
Note that (5) holds only for θ true (not θ 0 ), thus the test statistic diverges, i.e.
n1 /2 (b
θ
θ0 )
=
!
n1 /2 (b
θ
dξ
θ true ) + n1 /2 (θ true
+ n1 /2 (θ true
On the other hand, by (6), n1 /2 (b
θ
θ0 )
θ 0 ) ! ∞.
b
θ ) remains …xed (irrelavant to θ 0 ).
So the test will always reject, asymptotically.
Ke-Li Xu (Indiana University)
Bootstrap
September 13, 2019
19 / 47
Bootstrap t-test
Consider H0 : θ = θ 0 .
The t-statistic is t (θ 0 ) = vb 1 (b
θ
θ 0 ).
The asymptotic method relies on
d
t (θ 0 ) ! N (0, 1), under H0 .
Let the distribution of t (θ 0 ) be Gn (F ). Then G∞ (F ) = N (0, 1).
The bootstrap approximates Gn (F ) by Gn (Fb ). The bootstrap t-stat:
t = vb
1
(bθ
b
θ ).
Let qt (α) be 100α% quantile of t (where the actual calculation needs B
bootstrap re-sampling).
The hypothesis H0 is rejected if t (θ 0 ) > qt (0.975) or t (θ 0 ) < qt (0.025).
Ke-Li Xu (Indiana University)
Bootstrap
September 13, 2019
20 / 47
Percent-t CI
Percentile-t con…dence interval for θ:
[bθ
vb
θ
qt (0.975), b
vb
qt (0.025)].
It is obtained by inverting the bootstrap t-test:
(bθ θ 0 ) < qt (0.975)
vbqt (0.975) < θ 0 < b
θ vbqt (0.025)
qt (0.025)
b
θ
Ke-Li Xu (Indiana University)
< vb
Bootstrap
1
September 13, 2019
21 / 47
Bootstrapping Linear regression
Pairwise bootstrap
The model
yi = xi0 β + ui ,
where xi is k 1, and ui
(0, σ2 ).
β.
bi = yi xi0 b
The OLS: b
β = (∑ni=1 xi xi0 ) 1 (∑ni=1 xi yi ). OLS residuals u
0
0
Pairwise bootstrap: generate iid sample (yi , xi ) by taking random draws
from (yi , xi0 )0 .
Population regression slope in the bootstrap world is
( E xi xi 0 )
1
E xi yi = ( n 1
n
∑ xi xi0 )
i =1
1
(n
1
n
∑ xi yi ) = bβ
i =1
True residuals: ui = yi
xi 0 b
β, which equals u
bj (for some j)
Orthogonal condition: E xi ui = E xi (yi
xi 0 b
β) = 0.
Ke-Li Xu (Indiana University)
Bootstrap
September 13, 2019
22 / 47
In the original data world,
n 1 /2 ( b
β
d
β) ! N (0, (Exi xi0 ) 1 (Exi xi0 ui2 )(Exi xi0 ) 1 ).
In the bootstrap world,
b
β
n
, ( ∑ xi xi 0 )
1
= ( ∑ xi xi 0 )
1
i =1
n
i =1
We will show that
n 1 /2 ( b
β
Ke-Li Xu (Indiana University)
n
( ∑ xi yi )
i =1
n
n
i =1
i =1
( ∑ xi ( xi 0 b
β + ui )) = b
β + ( ∑ xi xi 0 )
1
n
( ∑ xi u i )
i =1
d
b
β) ! N (0, (Exi xi0 ) 1 (Exi xi0 ui2 )(Exi xi0 ) 1 ).
Bootstrap
September 13, 2019
(7)
23 / 47
To show (7), note that
1 n
1 n
xi xi 0 = E xi xi 0 + op (1) = ∑ xi xi0 + op (1) = Exi xi0 + op (1)
∑
n i =1
n i =1
n 1 /2
n
∑ xi ui
i =1
d
d
! N (0, E xi xi 0 ui 2 ) ! N (0, Exi xi0 ui2 ),
(8)
by CLT for iid sequences, where
E xi xi 0 ui 2
= E xi xi 0 ( yi
= n
1
n
xi 0 b
β )2 = n 1
p
∑ xi xi0 ubi 2 ! Exi xi0 ui2 .
n
∑ xi xi0 (yi
i =1
xi0 b
β )2
(9)
i =1
Thus (7) holds.
Ke-Li Xu (Indiana University)
Bootstrap
September 13, 2019
24 / 47
We now consider the Wald test for H0 : R β = r (q linear restrictions):
W
= (R b
β
d
r )0 R (∑i xi xi0 ) 1 (∑i u
bi2 xi xi0 )(∑i xi xi0 ) 1 R 0
! χ2 (q ).
The Wald statistic in the bootstrap world: W =
b
[R ( b
β
β)]0 R (∑i xi xi 0 ) 1 (∑i u
bi 2 xi xi 0 )(∑i xi xi 0 ) 1 R 0
where u
b =y
x 0b
β .
i
i
We can show that
Ke-Li Xu (Indiana University)
i
1
1
(R b
β
R (b
β
r)
b
β ),
d
W ! χ2 (q ).
Bootstrap
(10)
September 13, 2019
25 / 47
p
bi 2 ! Exi xi0 ui2 .
To show (10), we only need to show n1 ∑ni=1 xi xi 0 u
Note that
1 n
bi 2
xi xi 0 u
n i∑
=1
=
1 n
xi xi 0 ( yi
n i∑
=1
=
1 n
xi xi 0 [ u i
n i∑
=1
=
1 n
xi xi 0 ui 2 + op (1)
n i∑
=1
β )2
xi 0 b
β
xi 0 (b
b
β)]2
p
! Exi xi 0 ui 2
p
! Exi xi0 ui2 ,
where the second line uses the bootstrap model yi = xi 0 b
β + ui , and the
1
/
2
b
b
third line uses β
β = Op ( n
) (by (7)), and the last line is by (9).
Ke-Li Xu (Indiana University)
Bootstrap
September 13, 2019
26 / 47
Residual-based iid bootstrap
The model remains the same:
yi = xi0 β + ui ,
where xi is k
1, ui
(0, σ2 ) and Exi ui = 0.
Bootstrap model:
β + ui ,
yi = xi0 b
n 1 ∑ni=1 u
bi g (centered residuals)
This is referred to as (…xed-design) residual-based iid bootstrap.
where ui is a random draw from fu
bi
Centered residuals are needed so that E ui = 0. (If there is an intercept,
residuals are always centered)
Bootstrap data: fyi , xi g.
The OLS: b
β = (∑ni=1 xi xi0 ) 1 (∑ni=1 xi yi ).
OLS residuals u
bi = yi
xi0 b
β .
Ke-Li Xu (Indiana University)
Bootstrap
September 13, 2019
27 / 47
In the bootstrap world,
n
= ( ∑ xi xi0 )
b
β
1
i =1
n
Note that
n 1 /2
n
∑
i =1
1
1
n
β + ui ))
( ∑ xi (xi0 b
i =1
i =1
i =1
= b
β + ( ∑ xi xi0 )
i =1
n
n
( ∑ xi yi ) = ( ∑ xi xi0 )
n
( ∑ xi ui )
i =1
d
xi ui ! N (0, plim n 1
n
∑ Var
i =1
d
(xi ui )) = N (0, σ2 Exi xi0 ),
by CLT for inid sequences, where
n 1
n
∑ Var
( xi u i ) = n
1
i =1
= n
1
n
∑ xi xi0 E
i =1
n
∑ xi xi0
i =1
So
Ke-Li Xu (Indiana University)
n 1 /2 ( b
β
ui 2
n 1
n
i =1
d
b
β) ! N (0, σ2 (Exi xi0 ) 1 ).
Bootstrap
p
∑ ubi2 ! σ2 Exi xi0 .
September 13, 2019
28 / 47
Thus, the iid residual-based bootstrap is only valid when conditional
homoskedasticity (CH, i.e. E (ui2 jxi ) = σ2 ) holds.
Under CH, in the original data world
n 1 /2 ( b
β
d
β) ! N (0, σ2 (Exi xi0 ) 1 ).
Without conditional homoskedasticity,
n 1 /2 ( b
β
d
β) ! N (0, (Exi xi0 ) 1 (Exi xi0 ui2 )(Exi xi0 ) 1 ).
b
Thus in genernal, without imposing CH, n1 /2 (b
β
β) does not provide a
1
/
2
b
valid approximation of n ( β β), distribution-wise.
Ke-Li Xu (Indiana University)
Bootstrap
September 13, 2019
29 / 47
Wild Bootstrap
Now we consider a di¤erent type of bootstrap
iid
bi ei , where ei
Wild bootstrap: Let ui = u
(0, 1).
Under this scheme, the randomness in the bootstrap world comes from ei
(the original data are considered …xed, as common in the bootstrap analysis).
No need for centered residuals.
Several auxilary variables ei are used in practice:
I
I
Rademacher two-point random variables: P(ep
i = 1)=P(e
i = 1)=1/2.
p
Mammen’s two-point distribution: P(ei = 1 +2 5 )= 5p 1 and
P(ei =
I
1
p
2
Some use ei
5
2 5
p
)= 5p+1 .
2 5
N (0, 1).
Rademacher two-point random variables are recommended for ei .
Ke-Li Xu (Indiana University)
Bootstrap
September 13, 2019
30 / 47
Then
n 1 /2
n
∑ xi ui
= n
d
=
n 1 /2 ( b
β
n
∑ xi ubi ei
i =1
i =1
Thus
1 /2
d
! N (0, plimn
N (0, Exi xi0 ui2 ).
1
n
∑ xi xi0 ubi2 )
i =1
d
b
β) ! N (0, (Exi xi0 ) 1 (Exi xi0 ui2 )(Exi xi0 ) 1 ).
(11)
Now the bootstrap is asymptotically valid.
e.g. con…dence interval for βj can be constructed (using the distribution of
b
n 1 /2 ( b
β
β ) to approximate that of n1 /2 (b
β
β )).
j
j
Ke-Li Xu (Indiana University)
j
Bootstrap
j
September 13, 2019
31 / 47
Recovering the DGP is important, the construction of the statistic is not
Bootstrapping conditional homoskedasticity-based test is still valid under
heteroskedasticiy if wild bootstrap is used.
Consider the case k = 1.
Under original data, the standard t-stat is
(b
β
h
i 1 /2
d
(Ex 2 )
β) σ
! N 0, i
b2 (∑ni=1 xi2 ) 1
1 (Ex 2 u 2 )(Ex 2 )
i i
i
σ2 (Exi2 ) 1
1
.
In bootstrap world (using wild bootstrap),
(b
β
h
i 1 /2
d
(Ex 2 )
b
β) σ
! N 0, i
b 2 (∑ni=1 xi2 ) 1
1 (Ex 2 u 2 )(Ex 2 )
i
i i
σ2 (Exi2 ) 1
1
,
using the result (11), and
b 2=n 1
σ
Ke-Li Xu (Indiana University)
n
∑ ubi 2 = n
i =1
1
n
∑ ubi2 ei2 = n
i =1
Bootstrap
1
n
∑ ubi2 + op
i =1
p
(1) ! σ 2 .
September 13, 2019
32 / 47
Restricted Bootstrap
When performing a test, we can use restricted estimator e
β (under the null
e
hypothesis) in the bootstrap DGP. Thus β is the true value in the bootstrap
universe.
This subsection and the next both highlight the role played by the true value
used in the bootstrap DGP.
We illustrate this idea in the regression model:
yi = xi0 β + ui .
Suppose H0 : β = β0 .
In this case, e
β = β0 .
Generally, we can consider H0 : R β = R 0 . Recall how e
β is obtained in this
case (CLS or EMD).
Ke-Li Xu (Indiana University)
Bootstrap
September 13, 2019
33 / 47
Bootstrap DGP:
where ui = u
ei ei , with u
ei = yi
(wild bootstrap).
yi = xi0 β0 + ui ,
xi0 β0 (restricted residual) and ei
Bootstrap data: fyi , xi : i = 1, ..., n g.
Bootstrap test: use the distribution of n1 /2 (b
β
distribution of n1 /2 (b
β β0 ).
iid
(0, 1)
β0 ) to approximate the
There is evidence that the restricted bootstrap is more precise than the
unrestricted bootstrap (which we covered before).
Ke-Li Xu (Indiana University)
Bootstrap
September 13, 2019
34 / 47
Simple calculations indicate the validity:
n 1 /2 ( b
β
since
b
β
d
β0 ) ! N (0, (Exi xi0 ) 1 (Exi xi0 ui2 )(Exi xi0 ) 1 ),
n
= ( ∑ xi xi0 )
i =1
1
n
n
( ∑ xi yi ) = ( ∑ xi xi0 )
i =1
i =1
n
n
i =1
i =1
1
(12)
n
( ∑ xi (xi0 β0 + ui ))
i =1
β0 + ( ∑ xi xi0 ) 1 ( ∑ xi ui ),
=
where
n 1 /2
n
∑ xi u i
= n
i =1
1 /2
n
∑ xi uei ei
i =1
d
=
d
! N (0, plimn
N (0, Exi xi0 ui2 ),
1
n
∑ xi xi0 uei2 )
i =1
noting that u
ei = ui under H0 : β = β0 .
The consistency of the test follows from the fact that (12) is true regardless
H0 . (On the other hand, H0 needs to be true so that
d
n 1 /2 ( b
β β0 ) ! N (0, (Exi xi0 ) 1 (Exi xi0 ui2 )(Exi xi0 ) 1 ). Otherwise
n 1 /2 ( b
β β0 ) would diverge.)
Ke-Li Xu (Indiana University)
Bootstrap
September 13, 2019
35 / 47
Bootstrapping F Test
This is an example of bootstrapping criterion function-based tests when the
criterion function involves restrictions.
Consider the regression model:
yi = xi0 β + ui ,
where for simplicity, we assume conditional homoskedasticity.
Suppose H0 : R β = R 0 , where R is q
The F-statistic
F =
k.
e2 σ
b2 )/q
(σ
,
2
b / (n k )
σ
e2 is restricted residual-variance estimator.
where σ
Ke-Li Xu (Indiana University)
Bootstrap
September 13, 2019
36 / 47
Bootstrap sample: fyi , xi g. (e.g. iid residual-based)
The bootstrap F-statistic
F =
e 2 σ
b 2 )/q
(σ
,
b 2 / (n k )
σ
e 2 is calculated using fyi , xi g and imposing the restriction R β = R b
where σ
β.
(A common mistake is still imposing the restriction R β = R 0 ).
[Think about how it works if β = ( β1 , β2 )0 and the null is β2 = 0.]
Then, as always, the distribution of F is used to approximate the
distribution of F .
Ke-Li Xu (Indiana University)
Bootstrap
September 13, 2019
37 / 47
An alternative is to consider the restricted bootstrap
Restricted bootstrap sample: fyi , xi g. (e.g. iid residual-based).
The restricted bootstrap F-statistic
F
=
e 2 σ
b 2 )/q
(σ
,
b 2 / (n k )
σ
e 2 is calculated using fyi , xi g and imposing the restriction R β = R 0 .
where σ
The distribution of F
Ke-Li Xu (Indiana University)
is used to approximate the distribution of F .
Bootstrap
September 13, 2019
38 / 47
Final words: Parametric Bootstrap
What we have discussed is called nonparametric bootstrap, since the
empirical CDF Fb is a nonparametric estimator of F .
Nonparametric bootstrap is what most applications in econometrics use.
Parametric bootstrap: utilizes the function form of F .
Suppose yi
F (y j β), where F has a known form but β is unknown.
F (y j b
β), where b
β is the maximum
Parametric bootstrap draws yi
likelihood (ML) estimator of β.
Denote b
β is the MLE using the bootstrap data fy : i = 1, ..., n g.
i
We then use use the distribution of
distribution of n1 /2 (b
β β ).
Ke-Li Xu (Indiana University)
n 1 /2 ( b
β
Bootstrap
b
β) to approximate the
September 13, 2019
39 / 47
The second example: Gaussian linear regression model, yi jxi
b2
MLE: b
β, σ
Parametric bootstrap:
N (xi0 β, σ2 ).
β + ui ,
yi = xi0 b
b 2 ).
where ui
N (0, σ
Think about how this is di¤erent from the wild bootstrap when we use the
auxilary variable ei
N (0, 1).
Ke-Li Xu (Indiana University)
Bootstrap
September 13, 2019
40 / 47
A permutation test
Consider the single-regressor linear regression
yi = β 0 + β 1 xi + u i .
(13)
We test H0 : β1 = 0.
While we can use the asymptotic approach or the bootstrap, a permutation
test can also be used.
The idea is that if β1 = 0, then the order of fxi : i = 1, ..., n g shouldn’t
matter, if the order of fyi : i = 1, ..., n g is kept unchanged.
Let π (1), ..., π (n ) be a permutation of (1, ..., n ).
Suppose all permutations we consider are in the set Π. Then jΠj
n!.
For each permutation π, compute the least squares estimator of β1 using the
π
data fxπ (i ) , yi g, denoted as b
β1 .
π
If β1 = 0, b
β1 and b
β1 (original estimator) should come from the same
distribution.
Ke-Li Xu (Indiana University)
Bootstrap
September 13, 2019
41 / 47
Here the test statistic is b
β1 .
π
We approximate its distribution Gn by GnΠ (the empirical distribution b
β1 over
fπ 2 Πg).
Denote the α-th quantile of GnΠ by q Π (α).
We reject H0 at level 5% if
b
β1 < q Π (0.025).
β1 > q Π (0.975) or b
If the approximation of Gn by GnΠ is valid, then under the null,
P (b
β1 2rejection region) = 0.05.
Ke-Li Xu (Indiana University)
Bootstrap
September 13, 2019
42 / 47
Compare with bootstrap.
The bootstrap resamples the pair fxi , yi g (without re-matching within the
pair).
The permutation test resamples xi (without replacement), while using the
same data (in the same order) yi for each permutation.
In general, if you are interested in H0 : β1 = β01 , rewrite the model as
yi
β01 xi = β0 + ( β1
β01 )xi + ui .
Then the permutation test is implemented the same as above except using
the outcome yi β01 xi .
Ke-Li Xu (Indiana University)
Bootstrap
September 13, 2019
43 / 47
Asymptotics of the permutation test
Although such a test is widely used, it is only asymptotically valid under
conditional homoskedasticity (i.e. E (ui2 jxi ) = E (ui2 ) = σ2 ).
Asymptotic validity here means Gn and GnΠ converge to the same
distribution.
An important implication for CH is: for any π 2 Π, for each i,
E [ui2 (xπ (i )
Ex )2 ] = σ2 Var (x ).
(14)
It is because
=
E [ui2 (xπ (i )
(
E [ui2 (xi
Ex )2 ]
CH
Ex )2 ] = σ2 Var (x ),
Eui2 E (xπ (i )
iid data
Ex )2 =
σ2 Var (x ),
if π (i ) = i;
if π (i ) 6= i.
We can show that under H0 ,
Ke-Li Xu (Indiana University)
π d
n 1 /2 b
β1 ! N (0, σ2 Var (x ) 1 ).
Bootstrap
(15)
September 13, 2019
44 / 47
To prove (15), by the FWL theorem, under H0 ,
π
b
β1
=
h
∑ni=1 (xπ (i )
x )2
h
= ∑ni=1 (xπ (i )
H0
=
∑ni=1 (xi
i 1 n
∑ ( xπ (i )
x )2
x )(yi
i =1
i 1 n
∑ ( xπ (i )
y)
x ) ui
i =1
1
x )2
n
∑ ( xπ (i )
x ) ui .
i =1
We then have
π d
β1 ! N (0, Vπ ),
n 1 /2 b
where
Vπ
= Var (xi )
2
lim n 1
(16)
n
∑ Eui2 (xπ(i )
Exi )2
(17)
i =1
(14 )
2
= Var (xi )
= σ2 Var (x )
Ke-Li Xu (Indiana University)
1
Eui2 (xπ (i )
Exi )2
(18)
.
Bootstrap
September 13, 2019
45 / 47
In (16) above, we have used the CLT for independent but not identically
distributed data.
E.g. Suppose π : (1, 2, 3) ! (3, 2, 1). Then (x3 Ex )u1 and (x2 Ex )u2
are not identically distributed, if there is (higher order) dependece between x2
and u2 . These two are independent (by considering the correlation of any
moments of these two).
Thus (15) holds.
Ke-Li Xu (Indiana University)
Bootstrap
September 13, 2019
46 / 47
If we allow conditional heteroskedasticity, Vπ takes the general form of (17).
(instead of (18))
It is because Eui2 (xπ (i ) Exi )2 may di¤er across i for a particular π.
This happens if π does not move every unit.
I
I
For i such that π (i ) 6= i , Eui2 (xπ (i ) Ex )2 = Eui2 E (xπ (i ) Ex )2 = σ2 Var (x ).
But for i such that π (i ) = i , Eui2 (xπ (i ) Ex )2 6= σ2 Var (x ).
If π moves every unit (like π : (1, 2, 3, 4) ! (2, 3, 4, 1)), then
Vπ = σ2 Var (x ) 1 .
π
Thus Vπ depends on π. We thus don’t expect the distribution b
β1 over Π
would provide a useful approximation.
Ke-Li Xu (Indiana University)
Bootstrap
September 13, 2019
47 / 47






















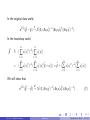


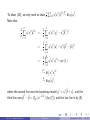




























![arXiv:1501.06623v1 [q-bio.PE] 26 Jan 2015](http://s1.studyres.com/store/data/003660370_1-c3fe9f4f5d3b3a85fe075a428636185e-150x150.png)

