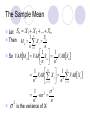Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
SUMS OF RANDOM VARIABLES
Changfei Chen
Sums of Random Variables
Let X 1 , X 2 ,..., X n be a sequence of random
variables, and let S n be their sum:
Sn X 1 X 2 ... X n
Mean and Variance of Sums of Random
Variables
The expected value of a sum of n random
variables is equal to the sum of the expected
values:
Note: regardless of the statistical dependence of
the r.v.
EX 1 X 2 ... X n
EX 1 EX 2 ... EX n
Mean and Variance of Sums of Random
Variables
Variance of sum of r.v.
VAR( X 1 X 2 ... X n )
E{[( X 1 X 2 ... X n ) E ( X 1 X 2 ... X n )]2 }
E{([ X 1 E ( X 1 )] [ X 2 E ( X 2 )] ... [ X n E ( X n )]) 2 }
n
n
n
E{ [ X i E ( X i )] [ X j E ( X j )][ X k E ( X k )]}
2
i 1
n
j 1 k 1
n
n
VAR( X i ) COV ( X j , X k )
i 1
note : j k
j 1 k 1
Mean and Variance of Sums of Random
Variables
Since that the covariance is not necessarily equal to zero
in general, the variance of sum is not necessarily equal
to the sum of variances of each r.v..
In case that all the r.v. are independent, the covariance
will be zeros. Then
VAR( X 1 X 2 ... X n )
VAR( X 1 ) VAR( X 2 ) ... VAR( X n )
pdf of Sums of Independent R.V.
Here X 1 , X 2 ,..., X n are n independent r.v.
First look at the sum of two independent r.v.
Z=X+Y
The characteristic function of Z:
z E e jZ
E[e j ( X Y ) ]
E[e jX e jY ]
E[e jX ] E[e jY ]
X Y
(1)
pdf of Sums of Independent R.V.
The cdf of Z:
Fz z
zx
f X ,Y x, y dydx
Then the pdf of Z:
d
f z z Fz z f X ,Y x, z x dx
dz
f X x f y z x dx
f X x fY y
p.s. Go through ‘Leibniz Rule’ in Calculus
pdf of Sums of Independent R.V.
z can be viewed as the Fourier transform of the pdf
of Z, so:
Z F f Z z
F f X x fY y
X Y
by equation (1)
The Fourier transform of a convolution of two functions is
equal to the product of the individual Fourier transforms.
pdf of Sums of Independent R.V.
Now considering the sum of more r.v.
Sn X 1 X 2 ... X n
Let
jS n
j X 1 X 2 ... X n
Ee
... Ee
E e E e
S n E e
jX 1
jX n
jX 2
X1 X 2 ... X n
Thus the pdf of the sum of r.v. can be found by finding
the inverse Fourier transform of the product of the
individual characteristic functions.
f Sn X F
1
...
X1
X2
Xn
The Sample Mean
X be a random variable for which the mean,
EX , is unknown.
X 1 , X 2 ,..., X n denote n independent, repeated
measurements of X, i.e. the X i are independent,
identically distributed r.v. (each has the same probability
distribution as the others and all are mutually independent) with the
same pdf as X.
Then the sample mean, M n , of the sequence is used to
estimate E[X]:
1 n
Mn Xi
n i 1
The Sample Mean
The expected value of the sample mean:
1 n
1 n
EM n E X i EX i
n i 1 n i 1
(where
E X i E X )
So the mean of the sample mean is equal to
EX
So we say that the sample mean is an
Unbiased Estimator for EX
The Sample Mean
Then the mean square error of the sample mean
about is equal to the variance of the sample
mean.
E M n E M n EM n
2
VAR( M n )
2
The Sample Mean
Let S n X 1 X 2 ... X n
n
1
Then M n X i S n
n i 1
n
1 1
So VARM n VAR S n 2 VARS n
n n
1
n
1
2 VAR X i 2
n
i 1 n
1
2
2 n
n
n
is the variance of Xi
2
2
n
VARX
i 1
i
The Sample Mean
So as n, the number of samples, increases,
the variance of the sample mean
approaches zero, which means that the
probability that the sample mean is close
to the true mean approaches one as n
becomes very large.
The Sample Mean
Use the Chebyshev inequality to formalize the probability:
P M n E M n
VARM n
2
2
P M n 2
n
So,
2
P M n 1 2
n
Thus for any choice of error and probability 1 , we
can select the number of samples,n, to have the sample
mean M n be within of the true mean with probability 1
The Sample Mean
Example:
A Voltage of constant, but unknown, value is to be
measured. Each measurement Xi is actually the sum of
the desired voltage v and a noise voltage Ni of zero
mean and standard deviation of 1 microvolt:
X i v Ni
Assume that the noise are independent variables. How
many measurements are required so that the probability
that M n is within 1 microvolt of the true mean is at
least .99?
The Sample Mean
Example (Continue):
From the problem, we know that each measurement Xi
has mean v and variance 1.
Moreover, we know
1
2
So
1
1
n
2
1
n
.99
We can solve the above equation and get n=100.
Thus if repeat the measurement 100 times, we can have
the sample mean of the measurement results, on
average, be of 99% probability within 1 microvolt.
Weak Law of Large Numbers
If we let the number of sample,n, approach
infinity,
2
lim P M n lim 1 2 1
n
n
n
The above is the expression of the weak law of
large numbers, which states that for a large
enough fixed value of n, the sample mean using
n samples will be close to the true mean with
high probability.
Strong Law of Large Numbers
Let X 1 , X 2 ,..., X n be a sequence of iid r.v. with finite
finite variance
EXand
mean
P[lim M n ] 1
n
which states that with probability 1, every
sequence of sample mean calculations will
eventually approach and stay close to EX
The strong law of large numbers demonstrates
the consistency between the theory and the
observed physical behavior.
Strong Law of Large Numbers
Example: Relative Frequency
Consider a sequence of independent repetitions of
some random experiment and let the r.v. I i be the
indicator function for the occurrence of event A in the ith
trial. The total number of occurrences of A in the first n
trials is then
N n I1 I 2 ... I n
The relative frequency of event A in the first n repetitions
of the experiment is then n
1
f A n I i
n
i 1
Thus the relative frequency f A n is simply the sample
mean of the random variables I i
Strong Law of Large Numbers
Example (Continue):
So, apply the weak law of large numbers to the
relative frequency:
lim P[ f A n P[ A] ] 1
n
apply the strong law of large numbers to the
relative frequency:
P[lim f A n P A] 1
n
The Central Limit Theorem
Let S n be the sum of n iid random variables with finite mean EX
and finite variance 2, and let Z n be the zero-mean, unit variance
r.v. defined by (normalize the S n )
S n
Zn
n
n
As we know the pdf of Gaussian r.v. is
f X x
2
1
e x m
2
2 2
Where m is the mean and is the variance of Gaussian r.v.
Then
2
1
x m 2
lim P[ Z n z ]
e
n
2
z
2 2
1
dx
2
z
e
x2 / 2
dx
Which states that as n becomes large, the cdf of S n approaches
the cdf of a Gaussian r.v.
The Central Limit Theorem
In central limit theorem X i can be any
distributions as they have a finite mean and
finite variance, which gives it the wide
applicability.
The central limit theorem explains why the
Gaussian r.v. appears in so many applications.
The Central Limit Theorem
Example:
Suppose that the orders at a restaurant are iid r.v. with mean $8
and standard deviation $2 . Estimate the probability that the first
100 customers spend a total of (1) more than $840. (2) between
$780 and $820.
Let X i denote the expenditure of the ith customer, then the total
spent of the first 100 customers will be
S100 X 1 X 2 ... X 100
The mean and variance of S100 are
n 800
Normalize the S100
n 2 400
S100 n S100 800
Z100
20
n
The Central Limit Theorem
Example (Continue):
Thus,
(1) PS100 840 P Z100 840 800
20
Q2 2.28 10 2
(2) P780 S 820 P 780 800 Z 820 800
100
n
20
20
P 1 Z n 1
PZ n 1 PZ n 1
Q 1 Q1
1 2Q1 1 2 0.159 0.682
Questions?
Thank you!
More: Q-function
The values of the Q(x) in the previous example come from the table
of Q-function.
The Q-function is defined by
1 t 2 2
Q x 1 x
e dt
x
2
Where x is the cdf of a Gaussian r.v. with zero mean and unit
variance.
1 x x m 2 2 2
PX x FX x
e
dx
2
1 x t 2 2
x
e dt
1 x m t 2 2
2
e dt
2
xm
Properties of Q-function:
Q 0
1
2
Q x 1 Qx
More: Proof of the central limit theorem
S n
1
Zn n
n
n
n
X
k 1
K
The characteristic function of Z n is given by
j n
j Z n
Z n E e
E exp
X
k
n
k 1
n j X k n n
j X K n
E e
E e j X K
E e
k 1
k 1
Expanding the exponential in the expression, we get
2
j
j
2
j X n
X
X R
Ee
E 1
2
2
!
n
n
n
n
j E X 2 ER 1 ER
j
1
E X
2!n 2
2n
n
The term ER can be neglected relative to 2 2n as n becomes large.
2
Thus,
2
Z n 1
2n
e
2
2
n
n