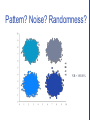
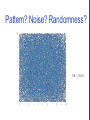
Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
Data Mining & Machine Learning Applications David TJ Huang Learning Outcomes Understand what is pattern and what is noise Recognize the influence of input data and preprocessing to the mining results Connect data mining and machine learning algorithms to real world problems Know how pattern & noise are defined differently in different problems PART II Data Input Getting to Know Your Data Now that I know what patterns I am looking for, I will dive right into the mining. Because, well…after all, this is data mining. Right?? • It is tempting to jump straight into mining and try to discover all the wonderful information inside the data • But first…we need to get the data ready! • Understanding data input is very important • Knowledge gained from understanding the data will further along your preprocessing stage • Helps with getting a preliminary idea of what the results might be like Effects of Preprocessing Consider the binary classification scenario… • 2 classes – positive class and negative class • Negative class is only 1% of the overall data • If you trained & tested on a simple classifier like Naïve Bayes • You will probably get an accuracy of around 99% • Great! Your results have such a wonderful accuracy! • Should you stop here? Effects of Preprocessing Consider the binary classification scenario… • 2 classes – positive class and negative class • Negative class is only 1% of the overall data • If you trained & tested on a simple classifier like Naïve Bayes • You will probably get an accuracy of around 99% • Great! Your results have such a wonderful accuracy! • Should you stop here? • Well…Naïve Bayes generally uses the MAP (maximum a posteriori) decision rule Effects of Preprocessing Consider the binary classification scenario… • 2 classes – positive class and negative class • Negative class is only 1% of the overall data • Naïve Bayes: • Posteriori = prior * likelihood • Prior = probability of class p(y ) • Likelihood = probability of class given attribute x – p(x | y ) • So…if your positive class occurs 99% of the time, most of the time NB is going to classify all your negative class data as positive based on MAP rule Effects of Preprocessing To improve your real detection rate of your negative class • Sampling to balance classes • Oversample negative classes • Undersample positive classes Effects of Preprocessing To improve your real detection rate of your negative class • Sampling to balance classes • Oversample negative classes • Undersample positive classes Are you forcing a pattern or overfitting your data by preprocessing and sampling?? Data Quality Today’s real-world data are highly susceptible to noisy, missing, and inconsistent data • Large amounts of data – data streams • Source of data – multiple / heterogeneous • Low quality data will lead to low quality mining results • Main goals of preprocessing: • To process the data in a way that will help improve the quality of the data and , consequently, the results • To process the data in a way that will improve the efficiency and ease of the mining process Data Quality Imagine… • You’re a manager at AllElectronics. You have been charged with analyzing the company’s data with respect to sales • You go through the data identifying and selecting the attributes (e.g. item, price, and units_sold) • Then…all hell breaks loose… • • • You notice attributes have no recorded value You find that some information regarding sales are not recorded Furthermore, users have reported errors, unusual values, and inconsistencies in the data • Welcome to the real world!! Data Quality Essentially your data is… • Inaccurate or noisy – • containing errors, or values that deviate from expected • Disguised missing data (e.g. January 1 as birthday) • Incomplete – • lacking attributes of interest, or containing only partial data • Inconsistent – • containing discrepancies • Three elements of data quality: accuracy, completeness, and consistency • The quality of the data may be different for different people (god…not this again!) Data Preprocessing Why preprocess? • Accuracy • Completeness • Consistency • Timeliness • Believability • Interpretability Data Preprocessing Preprocessing techniques – • Data cleaning • Remove noise and correct inconsistencies • Data integration • Merge data from multiple sources • Data reduction • Reduce size of data (e.g. remove duplicate attributes) • Data transformation • Transform data (e.g. normalize attributes) • These techniques are not mutually exclusive Cleaning Integration Reduction Transformation Data Cleaning Yes…we want clean data • Filling in missing values • Smoothing noisy data • Identifying or removing outliers • Resolving inconsistencies Dealing with Missing Values In real world data – missing values are often quite common • Ignore the entire row • Fill in the missing value manually • Use a global constant • Use a measure of central tendency • Use the attribute mean or median for all samples belonging to the same class • Use the most probable value Dealing with Noisy Data Oh…it is you again… • Noise is random error or variance in a measured variable • Binning • Regression • Outlier analysis Dealing with Noisy Data Binning Example: Sorted data for price (in dollars): 4, 8, 15, 21, 21, 24, 25, 28, 34 Partition into (equal-frequency) bins: Bin 1: 4, 8, 15 Bin 2: 21, 21, 24 Bin 3: 25, 28, 34 Smoothing by bin means: Bin 1: 9, 9, 9 Bin 2: 22, 22, 22 Bin 3: 29, 29, 29 Smoothing by bin boundaries: Bin 1: 4, 4, 15 Bin 2: 21, 21, 24 Bin 3: 25, 25, 34 Dealing with Noisy Data Regression • Conforms data values to a function • Linear regression – use best line of fit between two attributes so one can be used to predict another • Multiple linear regression – extension of linear regression where more than two attributes are involved and data is fit to a multidimensional surface Dealing with Noisy Data Outlier analysis • Values that fall outside of the set of clusters may be considered as outliers and removed Pattern? Noise? Randomness? NB = 100.00% Pattern? Noise? Randomness? NB = 100.00% Pattern? Noise? Randomness? NB = 75.14% Pattern? Noise? Randomness? NB = 25.06% Cleaning Integration Reduction Transformation Data Integration Merging data from multiple sources • Goal: • Reduce and avoid redundancies and inconsistencies • Improve the accuracy and speed of the subsequent mining process • Multiple sources • Similar schema vs. Different schema • Similar to relational databases – data in separate tables or not?? Data Integration Merging data from multiple sources • Data warehouse • AllElectronics have 100 stores nation-wide each with their own collected data & database. How to integrate them all data into one?? Entity identification problem • Schema integration • Different stores may have different schema for storing their data • Object matching • Can you be certain that cid in store A matches customer_id in store B? • Some attributes can be falsely matched if not careful Data Integration Redundancy and correlation analysis • Some attributes may be redundant if they can be derived from other attributes • Some attributes from different sources may be inconsistently named causing direct redundancies Correlation analysis can be used to detect redundancies • Chi-squared test – nominal data • Correlation coefficient / covariance – numerical data Data Integration Data value conflict • The same real world entity, attribute values from different sources may differ • Differences can arise from representation, scaling or encoding • Measurement unit • Celsius vs. Fahrenheit • Metric vs. Imperial • Hidden differences • Price of rooms for a hotel chain may be in different currencies and involve different services (incl. breakfast or not incl. breakfast, etc.) Data Integration How to solve this?? • Look at meta data • Understand what the values in the attributes really mean • Again, you have to make your own judgement & justify the judgement Cleaning Integration Reduction Transformation Data Reduction When your dataset is HUGE and hard to analyze… • Even using data stream mining techniques that can deal with large amounts of data, you may still want to perform some data reduction on your original data • Goal of data reduction: • Obtain a reduced representation of the dataset – sampling • You want it to be of lesser volume but still resemble the original data Data Reduction Reduction techniques • Dimensionality reduction • Transform or project the original data onto a smaller space • Numerosity reduction • Replace the original data volume by alternative smaller forms of data representation • Data compression • Reduce data form to be reconstructed back later Also Works for Mining Models.. Output detection code • Method proposed by Dietterich and Bakiri (1995) • The idea is to handle multiple class classification problems by simplifying it with binary classifiers • The idea is the same – you’re reducing the dimensionality or transforming your more complicated problem space into multiple simpler ones Also Works for Mining Models.. Output detection code Class 1 Class 2 Class 3 Classifier 1 0 0 1 Classifier 2 0 1 1 Classifier 3 1 0 0 Classifier 4 1 1 0 Classifier 5 1 0 1 Classifier 6 0 1 0 Also Works for Mining Models.. Output detection code • Output detection code serves as an error-correcting method which allows for incorrect votes of classes by the classifiers in the bagging method to be corrected • This method increases the diversity of the classifiers and reduces correlations between the classifiers • All because you’re transforming the problem space of each different classifier from the original one to a set of various simpler ones Cleaning Integration Reduction Transformation Data Transformation Goal of transformation • Transform or consolidate data to make patterns easier to understand Transformation techniques • Smoothing • Attribute construction • Aggregation • Normalization • Discretization • Concept hierarchy generation for nominal data Yes there are a lot of overlaps between preprocessing tasks! Data Transformation Normalization • Numbers are not just numbers! • Numbers with different ranges and different measurements and units can carry a different weight – sometimes we do not want this! • Common ranges of normalization [0, 1] or [-1, 1] Data Transformation Normalization Methods • Min-Max normalization • Z-score normalization • Decimal scaling Data Transformation Discretization • Binning • Equal bins – Age 10-19, 20-29, 30-39, etc. • Histogram Analysis • Partition data based on values like frequency • Cluster Are You Forcing a Pattern? By preprocessing you are hoping to clean your data, to help your mining task, and to get a better set of patterns from the data • But… • Are you certain that you are not forcing a pattern to be found by creating a pattern when you preprocess? Are You Forcing a Pattern? By preprocessing you are hoping to clean your data, to help your mining task, and to get a better set of patterns from the data • But… • Are you certain that you are not forcing a pattern to be found by creating a pattern when you preprocess? Every decision you make when you do data mining & machine learning requires thorough thought and justification!! References • Data Mining 3rd Edition – Jiawei Han, Micheline Kamber, Jian Pei • Solving multiclass learning problems via error-correcting output codes – Thomas G. Dietterich and Ghulum Bakiri.