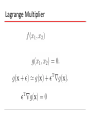Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
CS 59000 Statistical Machine learning Lecture 17 Yuan (Alan) Qi Purdue CS Oct. 28 2008 Example: Density Estimation Outline • Review of GP for classification • Support Vector Machines Gaussian Processes for Classification Likelihood: GP Prior: Covariance function: Predictive Distribution No analytical solution. Approximate this integration: Laplace’s method Variational Bayes Expectation propagation Laplace’s method for GP Classification (1) Laplace’s method for GP Classification (2) Taylor expansion: Laplace’s method for GP Classification (3) Newton-Raphson update: Laplace’s method for GP Classification (4) Question: How to get the mean and the variance above? Predictive Distribution Support Vector Machines Support Vector Machines: motivated by statistical learning theory. Maximum margin classifiers Margin: the smallest distance between the decision boundary and any of the samples Distance of Data Point to Hyperplace Consider data points that are correctly classified. The distance of a data point to the hyperplace: Maximizing Margin Since scaling w and b together will not change the above ratio, we set In the case of data points for which the equality holds, the constraints are said to be active, whereas for the remainder they are said to be inactive. Optimization Problem Quadratic programming: Subject to Lagrange Multiplier Geometrical Illustration of Lagrange Multiplier Simple Example (another perspective) Lagrange Multiplier with Inequality Constraints Karush-Kuhn-Tucker (KKT) condition Lagrange Function for SVM Quadratic programming: Subject to Lagrange function: Dual Variables Setting derivatives over L to zero: Dual Problem Prediction KKT Condition and Support Vectors In the later case, we call the corresponding data points support vectors. Solving Bias Term Computational Complexity Quadratic programming: When Dimension < Number of data points, Solving the Dual problem is more costly. Dual representation allows the use of kernels Example: SVM Classification