Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
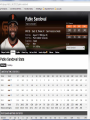
Chapter 16 Random Variables Copyright © 2009 Pearson Education, Inc. NOTE on slides / What we can and cannot do The following notice accompanies these slides, which have been downloaded from the publisher’s Web site: “This work is protected by United States copyright laws and is provided solely for the use of instructors in teaching their courses and assessing student learning. Dissemination or sale of any part of this work (including on the World Wide Web) will destroy the integrity of the work and is not permitted. The work and materials from this site should never be made available to students except by instructors using the accompanying text in their classes. All recipients of this work are expected to abide by these restrictions and to honor the intended pedagogical purposes and the needs of other instructors who rely on these materials.” We can use these slides because we are using the text for this course. Please help us stay legal. Do not distribute these slides any further. The original slides are done in orange / brown and black. My additions are in red and blue. Topics in green are optional. Copyright © 2009 Pearson Education, Inc. Slide 1- 3 Topics in this chapter Random Variables Probability Models Expected value Standard Deviation Working with means and variances The “Pythagorean Theorem of Statistics” Copyright © 2009 Pearson Education, Inc. Slide 1- 4 Division of Mathematics, HCC Course Objectives for Chapter 16 After studying this chapter, the student will be able to: Define random variable. Find the probability model for a discrete random variable. Find the mean (expected value) and the standard deviation of a random variable, and Interpret the meaning of the expected value and standard deviation of a random variable in the proper context. Copyright © 2009 Pearson Education, Inc. A little more probability Source: “Understandable Statistics’ (9th Edition), Brase & Brase, Houghton-Mifflin, Ex. 5.1.9 Movie stars and presidents have fished Pyramid Lake, Nevada. It is one of the best places in the lower 48 to catch trophy trout. Let’s fish Pyramid Lake for six hours. Copyright © 2009 Pearson Education, Inc. Slide 1- 6 Pyramid Lake, Nevada Source: Wikipedia •NW Nevada •20km east of CA line •60km north of Reno Copyright © 2009 Pearson Education, Inc. Slide 1- 7 Fishing at Pyramid Lake We can catch any number of fish up to the limit of four. The chance of catching a given number of fish is given at the right: Copyright © 2009 Pearson Education, Inc. Number of fish Chance of catching 0 44% 1 36% 2 15% 3 4% 4 1% Slide 1- 8 Fishing at Pyramid Lake What is the probability that an arbitrary fisherman will catch at least two fish? Convert to probabilities. Are these assignments plausible? P(2) + P(3) + P(4) = 0.15 + 0.04 + 0.01 = 0.20 Copyright © 2009 Pearson Education, Inc. Number of fish Probability 0 0.44 1 0.36 2 0.15 3 0.04 4 0.01 Slide 1- 9 Fishing at Pyramid Lake How many fish can a fisherman expect to catch on the average? We need some more terminology to answer this question. The number of fish caught in a six-hour period can vary randomly from 0 to 4. Each number has a probability associated with it. Copyright © 2009 Pearson Education, Inc. Slide 1- 10 Expected Value: Center A random variable assumes a value based on the outcome of a random event. We use a capital letter, like X, to denote a random variable. A particular value of a random variable will be denoted with a lower case letter, in this case x. Copyright © 2009 Pearson Education, Inc. Slide 1- 11 Expected Value: Center (cont.) There are two types of random variables: Discrete random variables can take one of a finite number of distinct outcomes. Example: Number of credit hours Continuous random variables can take any numeric value within a range of values. Example: Cost of books this term (?) This is actually discrete since it takes on a finite number of values (perhaps a lot - $0 to maybe $1000 or more.) Example: Throw a dart at a board. Where the dart hits in relation to the bulls eye is continuous. Copyright © 2009 Pearson Education, Inc. Slide 1- 12 Expected Value: Center (cont.) A probability model for a random variable consists of: The collection of all possible values of a random variable, and the probabilities that the values occur. Of particular interest is the value we expect a random variable to take on, notated μ (for population mean) or E(X) for expected value. Copyright © 2009 Pearson Education, Inc. Slide 1- 13 Expected Value: Center (cont.) The expected value of a (discrete) random variable can be found by summing the products of each possible value and the probability that it occurs: E X x P x Note: Be sure that every possible outcome is included in the sum and verify that you have a valid probability model to start with. Copyright © 2009 Pearson Education, Inc. Slide 1- 14 Fishing at Pyramid Lake We have a random variable. We have a probability model. Adding the column on the right, µ = 0.82. An arbitrary fisherman can expect 0.82 fish per trip over the long haul. Copyright © 2009 Pearson Education, Inc. Number of fish X Probability P(x) X*P(x) 0 0.44 0 1 0.36 0.36 2 0.15 0.30 3 0.04 0.12 4 0.01 0.04 Slide 1- 15 Some clarification and another question We all know that the fisherman is not going to come home with 82/100’s of a fish! Over the long haul (say if he goes to Pyramid Lake every weekend), he can expect to get 0.82 fish. How does that estimate vary? We need a measure of variability. Copyright © 2009 Pearson Education, Inc. Slide 1- 16 First Center, Now Spread… For data, we calculated the standard deviation by first computing the deviation from the mean and squaring it. We do that with discrete random variables as well. The variance for a random variable is: Var X x P x 2 2 The standard deviation for a random variable is: SD X Var X Copyright © 2009 Pearson Education, Inc. Slide 1- 17 Fishing at Pyramid Lake Number of Probability fish P(x) X 0 0.44 1 0.36 2 0.15 3 0.04 4 0.01 Copyright © 2009 Pearson Education, Inc. (x - µ) (x - µ)2 (x - µ) 2 P(x) Slide 1- 18 Fishing at Pyramid Lake Number of Probability fish P(x) X (x - µ) 0 0.44 -0.82 1 0.36 0.18 2 0.15 1.18 3 0.04 2.18 4 0.01 3.18 Copyright © 2009 Pearson Education, Inc. (x - µ)2 (x - µ) 2 P(x) Slide 1- 19 Fishing at Pyramid Lake Number of Probability fish P(x) X (x - µ) (x - µ)2 0 0.44 -0.82 0.6724 1 0.36 0.18 0.0324 2 0.15 1.18 1.3924 3 0.04 2.18 4.7524 4 0.01 3.18 10.1124 Copyright © 2009 Pearson Education, Inc. (x - µ) 2 P(x) Slide 1- 20 Fishing at Pyramid Lake Number of Probability fish P(x) X (x - µ) (x - µ)2 (x - µ) 2 P(x) 0 0.44 -0.82 0.6724 0.29586 1 0.36 0.18 0.0324 0.011664 2 0.15 1.18 1.3924 0.20886 3 0.04 2.18 4.7524 0.190096 4 0.01 3.18 10.1124 0.101124 Copyright © 2009 Pearson Education, Inc. Slide 1- 21 Fishing at Pyramid Lake Add up the rightmost column 0.29586 + 0.01166 + 0.20886 + 0.1901 + 0.10112 Answer is the variance. σ2 = 0.8076. We need to take the square root to get the standard deviation. Therefore σ = 0.8987. Explanation in context: The fisherman can expect to catch 0.82 fish with a standard deviation of about 0.9 fish. Copyright © 2009 Pearson Education, Inc. Slide 1- 22 Fishing at Pyramid Lake with the TI (Long Way) First compute the mean Then “1-var Stats L3” Then add to get 0.8076 Take the square root . Answer: 0.89867. Copyright © 2009 Pearson Education, Inc. Slide 1- 23 Fishing at Pyramid Lake with the TI (Short Way) We’ve got it! Copyright © 2009 Pearson Education, Inc. Slide 1- 24 Fishing at Pyramid Lake with the TI Summary First, put x in L1 and P(x) in L2. (It will not work the other way around). Long way: L1 * L2 [STO] L3 Do 1-Var Stats L3 and get 0.82. (L1 – 0.82)2 * L2 [STO] L4 Do 1-Var Stats L4 and read Σx = 0.8076 Take the square root. Short way: “1-Var-Stats L1,L2” You have both! Nothing else! Copyright © 2009 Pearson Education, Inc. Slide 1- 25 Notice ∑x and “x-bar.” They are the same. Also, n = 1. This is always the case when using a probability model. If there is a discrepancy with either of these, you probably do not have a valid model. Exception: Possible small discrepancies due to rounding: Example from last chapter: 5.69114597 * 10-9 Do 1-VarStats L2 to check. Copyright © 2009 Pearson Education, Inc. Slide 1- 26 Note: If you have System 2.55 on your TI-84 1-varStats L1,L2 will not work with StatWizard on. You may input the data in the manner shown, however. Copyright © 2009 Pearson Education, Inc. Slide 1- 27 StatCrunch – Expected Values Put the number in var 1 and the probability in L2. Now do Stat →Calculators→Custom Put “Fish” in Values, P(Fish) in Weights Click OK. Same answer as the TI. Copyright © 2009 Pearson Education, Inc. Slide 1- 28 Copyright © 2009 Pearson Education, Inc. Slide 1- 29 Copyright © 2009 Pearson Education, Inc. Slide 1- 30 Copyright © 2009 Pearson Education, Inc. Slide 1- 31 Copyright © 2009 Pearson Education, Inc. Slide 1- 32 A more complex example We all know how insurance works. We pay a premium to insure our cars. If nothing happens, we lose (the insurance company wins) If our car is wrecked, we win (the insurance company loses). Questions: How much can the insurance company expect to lose over the long haul? How much of a premium should they charge? Copyright © 2009 Pearson Education, Inc. Slide 1- 33 Insurance example Consider an AD&D company. Past experience has shown that the company should expect the following to happen per thousand policyholders: Outcome Death Payout $10,000 Probability 1 in 1000 Disability Uninjured $5,000 0 2 in 1000 997 in 1000 Questions: How much can the insurance company expect to lose over the long haul (per thousand policyholders)? How much of a premium should they charge his year based on their loss experience (and need to make a profit)? Copyright © 2009 Pearson Education, Inc. Slide 1- 34 Insurance example Let’s compute what the company expects to pay in each category: Outcome Death Disability Uninjured Payout (L1) $10,000 $5,000 0 Probability (L2) 0.001 0.002 0.997 Should we do it the long way? Let’s not and say we did !! Use the TI. Copyright © 2009 Pearson Education, Inc. Slide 1- 35 Insurance example The company can expect to pay out $20 per policyholder with an expected standard deviation of about $387.00. This is reasonable considering that we are dealing with relatively large payouts and low probabilities. The company needs to charge more than $20. Copyright © 2009 Pearson Education, Inc. Slide 1- 36 Insurance Example by hand We know that the company’s expected payout is $20. What is the standard deviation? First compute the variance. Var(X) = (10000 – 20)2 + (5000 – 20)2*2 + (0-20) 2*997 1000 1000 1000 or 149,600 (“dollars squared”) (??) The standard deviation is the square root, or $386.78 (about $387) Or use the TI! $386.78159 = $386.78. Copyright © 2009 Pearson Education, Inc. Slide 1- 37 Insurance Example Question: If the company charges $50 per policy, what profit can it expect to make? Profit = Premium – Expected Payout. Intuitively, since the expected payout is $20, the expected profit is $30. We can generalize this to an Addition Rule for Expected Values. Copyright © 2009 Pearson Education, Inc. Slide 1- 38 More About Means and Variances Adding or subtracting a constant from data shifts the mean but doesn’t change the variance or standard deviation: E(X ± c) = E(X) ± c Var(X ± c) = Var(X) Example: Consider everyone in a company receiving a $5000 increase in salary. Copyright © 2009 Pearson Education, Inc. Slide 1- 39 More About Means and Variances (cont.) In general, multiplying each value of a random variable by a constant multiplies the mean by that constant and the variance by the square of the constant: E(aX) = aE(X) Var(aX) = a2Var(X) Therefore, SD(aX) = aSD(X) Example: Consider everyone in a company receiving a 10% increase in salary. Note: Dividing by a constant c is the same as multiplying by (1 / c). Copyright © 2009 Pearson Education, Inc. Slide 1- 40 Insurance Example Suppose the company doubles the payout, i.e. $20000 for death, $10000 for disability. Probabilities remain the same. We can go through the math again, but let’s not! Let’s use our formulas. The constant is 2. E(2X) = 2E(X) = $40. SD(2X) = 2*SD(X) = $773.56 If we want, we could also compute Var(2X) = 4 * Var(X) = 598,400 dollars squared! Copyright © 2009 Pearson Education, Inc. Slide 1- 41 Insurance Example Now suppose two people from the same family buy policies. This is not the same situation as doubling the premium or payout. Both people are unlikely to die or become disabled in the same year. We could work with a chart with nine rows (since there are nine possible outcomes). Let’s do something easier! Copyright © 2009 Pearson Education, Inc. Slide 1- 42 Insurance example Outcome Husband Death Death Death Disabled Disabled Disabled OK OK OK Wife Death Disabled OK. Death Disabled OK. Death Disabled OK Statistics Payout $20,000 $15,000 $10,000 $15,000 $10,000 $5,000 $10,000 $5,000 0 Probability 0.000001 0.000002 0.000997 0.000002 0.000004 0.001994 0.000997 0.001994 0.994009 Standard deviation comes out $546.99. Should we make our columns (or put it in the TI?) I didn’t think so. There’s an easier way. Copyright © 2009 Pearson Education, Inc. Slide 1- 43 More About Means and Variances (cont.) In general, with respect to addition and subtraction of random variables, The mean of the sum of two random variables is the sum of the means. The mean of the difference of two random variables is the difference of the means. E(X ± Y) = E(X) ± E(Y) If the random variables are independent, the variance of their sum or difference is always the sum of the variances. Var(X ± Y) = Var(X) + Var(Y) Copyright © 2009 Pearson Education, Inc. Slide 1- 44 Insurance Example So, all we need do is compute Var (H + W) = Var (H) + Var (W) = 149,600 + 149,600 = 299,200 So that SD (H + W) = $546.99 (say $547.) Copyright © 2009 Pearson Education, Inc. Slide 1- 45 Notice something else The variance formula is Var(X ± Y) = Var(X) + Var(Y) So we can write the standard deviation of the sum (or difference) of two random variables as \ This is the Pythagorean Theorem of Statistics This theorem will be very important as we apply it in Chapters 18 – 25. Put an asterisk on it! Copyright © 2009 Pearson Education, Inc. Slide 1- 46 A Diversion! (High school student’s answer on a math test) Copyright © 2009 Pearson Education, Inc. Slide 1- 47 Combining Random Variables (The Bad News) It would be nice if we could go directly from models of each random variable to a model for their sum. But, the probability model for the sum of two random variables is not necessarily the same as the model we started with even when the variables are independent. Thus, even though expected values may add, the probability model itself is different. Copyright © 2009 Pearson Education, Inc. Slide 1- 48 Continuous Random Variables Random variables that can take on any value in a range of values are called continuous random variables. Continuous random variables have means (expected values) and variances. We won’t worry about how to calculate these means and variances in this course, but we can still work with models for continuous random variables when we’re given these parameters. Copyright © 2009 Pearson Education, Inc. Slide 1- 49 Combining Random Variables (The Good News) Nearly everything we’ve said about how discrete random variables behave is true of continuous random variables, as well. When two independent continuous random variables have Normal models, so does their sum or difference. This fact will let us apply our knowledge of Normal probabilities to questions about the sum or difference of independent random variables. Copyright © 2009 Pearson Education, Inc. Slide 1- 50 Another example – Baseball In 2008, Pablo Sandoval. of the San Francisco Giants had a batting average of .345. He had 145 “At-bats” and 50 hits. Out of the 50 hits, 36 were singles, 10 were doubles, 1 was a triple and 3 were home runs. Can we give Pablo “extra credit” for his doubles, triple and homers? Copyright © 2009 Pearson Education, Inc. Another example – Pablo Sandoval Let’s compute the Bases gained expected value of the number of bases gained in 0 an “at bat.” We’ll compute the 1 standard deviation as well and see if it is useful. 2 • Source: http://espn.go.com/mlb/player/st ats/_/id/29212/pablo-sandoval Copyright © 2009 Pearson Education, Inc. How many? 95 36 10 3 1 4 3 Pablo Sandoval – slugging ratio The Expected Value is 0.489655, or 0.490. This is the “slugging ratio.” It is a recognized statistic that is tabulated in pro baseball. It is the expected number of bases that Pablo is expected to gain over the long run. He cannot gain 0.49 bases in an “at bat” – it is an average. We can look at the standard deviation as well. σ = 0.823. Copyright © 2009 Pearson Education, Inc. Copyright © 2009 Pearson Education, Inc. Slide 1- 54 Pablo Sandoval– slugging ratio Over the long run, based on 2008 data, Pablo is expected to hit with Expected number of bases earned: 0.49 Standard deviation: 0.823 Batting average was 0.345 Copyright © 2009 Pearson Education, Inc. MegaMillions Lottery Players may pick six numbers from two separate pools of numbers - five different numbers from 1 to 56 and one number from 1 to 46 - or select Easy Pick. You win the jackpot by matching all six winning numbers in a drawing. There are lesser prizes for other matches. Source: http://www.megamillions.com/ Copyright © 2009 Pearson Education, Inc. Possible prizes Copyright © 2009 Pearson Education, Inc. Expected value of winnings This week, the web site http://www.megamillions.com/ carried the banner “Estimated Jackpot $41 Million.” This is after the March 8 drawing. Knowing this, we can compute the expected return on your dollar. In the TI put the prize value in L1 and 1 divided by the chances of winning in L2 (one small hangup – see next slide) Then do 1-varStats L1,L2 Copyright © 2009 Pearson Education, Inc. You must include a win of 0. The overall chances of winning a prize are approximately 1 in 40. Therefore, the probability of not winning anything is approximately 39/40. This is not exact. Enter the prizes (except for 0) in L1 and 1 divided by the odds in L2. Then do 1-varStats L2 to get ∑x=0.0250179206. Then add 0 as a prize and the probability of winning 0 as 1 - 0.0250179206 = 0.9749820794. Copyright © 2009 Pearson Education, Inc. Slide 1- 59 Computing expected value - TI Mean = $0.415 StDev = $3095.64 (with rounding) Copyright © 2009 Pearson Education, Inc. Slide 1- 60 Expected value of winnings The TI gives Σx = 0.415 σx = 3095.64 Big standard deviation – remember the big numbers and low probabilities (like the insurance example.) Each ticket costs $1.00. Over the long run, for this drawing, you can expect a payout (on the average) of $0.42 per ticket with a standard deviation of $3095.64! Since the player pays $1 for the ticket, the expected gain is $1.00 - $.42, or a loss of $.58. Play responsibly! Copyright © 2009 Pearson Education, Inc. Biggest ever - $656M in March 2012 We need only put 656000000 into our calculator. We get (for a $1.00 ticket) an expected prize (rounded to two places) of $3.92 and a standard deviation of $49488.11 How can the lottery afford to give away an expected prize of $3.92 for a $1.00 ticket? Answer: They had not given away the top prize in months. Copyright © 2009 Pearson Education, Inc. Slide 1- 62 See also “THE LOTTERY: A DREAM COME TRUE OR A TAX ON PEOPLE WHO ARE BAD AT MATH?” George Ashline and Joanna Ellis-Monaghan Department of Mathematics, St. Michael’s College; Colchester, Vermont http://academics.smcvt.edu/.../PRIMUS%20v%20 XIV,%20n%204%20The%20Lottery.doc - Copyright © 2009 Pearson Education, Inc. *Correlation and Covariance If X is a random variable with expected value E(X)=µ and Y is a random variable with expected value E(Y)=ν, then the covariance of X and Y is defined as Cov( X ,Y ) E(( X )(Y )) The covariance measures how X and Y vary together. Copyright © 2009 Pearson Education, Inc. Slide 1- 64 *Correlation and Covariance (cont.) Covariance, unlike correlation, doesn’t have to be between -1 and 1. If X and Y have large values, the covariance will be large as well. To fix the “problem” we can divide the covariance by each of the standard deviations to get the correlation: Corr ( X , Y ) Copyright © 2009 Pearson Education, Inc. Cov( X , Y ) XY Slide 1- 65 What Can Go Wrong? Probability models are still just models. Models can be useful, but they are not reality. Question probabilities as you would data, and think about the assumptions behind your models. If the model is wrong, so is everything else. Copyright © 2009 Pearson Education, Inc. Slide 1- 66 What Can Go Wrong? (cont.) Don’t assume everything’s Normal. You must Think about whether the Normality Assumption is justified. Watch out for variables that aren’t independent: You can add expected values of any two random variables, but you can only add variances of independent random variables. Copyright © 2009 Pearson Education, Inc. Slide 1- 67 What Can Go Wrong? (cont.) Don’t forget: Variances of independent random variables add. Standard deviations don’t. Don’t forget: Variances of independent random variables add, even when you’re looking at the difference between them. Don’t write independent instances of a random variable with notation that looks like they are the same variables. Copyright © 2009 Pearson Education, Inc. Slide 1- 68 What have we learned? We know how to work with random variables. We can use a probability model for a discrete random variable to find its expected value and standard deviation. The mean of the sum or difference of two random variables, discrete or continuous, is just the sum or difference of their means. And, for independent random variables, the variance of their sum or difference is always the sum of their variances. Copyright © 2009 Pearson Education, Inc. Slide 1- 69 What have we learned? (cont.) Normal models are once again special. Sums or differences of Normally distributed random variables also follow Normal models. Copyright © 2009 Pearson Education, Inc. Slide 1- 70 Topics in this chapter Random Variables Probability Models Expected value Standard Deviation Working with means and variances The “Pythagorean Theorem of Statistics” Copyright © 2009 Pearson Education, Inc. Slide 1- 71 Division of Mathematics, HCC Course Objectives for Chapter 16 After studying this chapter, the student will be able to: Define random variable. Find the probability model for a discrete random variable. Find the mean (expected value) and the standard deviation of a random variable, and Interpret the meaning of the expected value and standard deviation of a random variable in the proper context. Copyright © 2009 Pearson Education, Inc.