Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
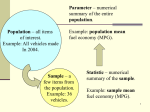
STATGRAPHICS – Rev. 7/3/2009 Calibration Models Summary The Calibration Models procedure is designed to construct a statistical model describing the relationship between 2 variables, X and Y, where the intent of the model-building is to construct an equation that can be used to predict X given Y. In a typical application, X represents the true value of some important quantity, while Y is the measured value. Initially, a set of samples with known X values are used to calibrate the model. Later, when samples with unknown X values are measured, the fitted model is used to make an inverse prediction of X from the measured values Y. Any of 27 linear and nonlinear models may be fit. The output parallels that of the Simple Regression procedure. Sample StatFolio: calibration.sgp Sample Data: The file galactose.sgd contains data on an experiment performed using a new method for measuring the concentration of galactose in blood. The data is similar to that reported by Neter et al (1998). n = 12 samples with known galactose concentrations X ranging between 1.0 and 10.0 were measured. The data are shown below: Known 1 1 1 4 4 4 7 7 7 10 10 10 Measured 0.82 0.95 0.87 4.14 4.04 4.01 7.13 6.92 6.81 9.95 10.15 10.08 An additional sample of unknown concentration was measured, yielding Y = 6.52. An estimate of the actual concentration of the additional sample is desired, with a 95% confidence interval. 2009 by StatPoint Technologies, Inc. Calibration Models - 1 STATGRAPHICS – Rev. 7/3/2009 Data Input The data input dialog box can be used in 2 ways: 1. Given measurements of samples with known values of X, it can be used to fit the calibration model. The coefficients of the model may be saved for later use. 2. If new measurements are made, the stored coefficients can be used to predict the true value of X. Fitting the Calibration Model Y (measured): numeric column containing the n measured values of the quantity to be predicted. X (actual): numeric column containing the n known values of that quantity. Fitted Model Statistics: left blank when fitting a new model. Weights: optional numeric column containing weights to be applied to the residuals if performing a weighted least squares fit. If the variability of Y changes as a function of X, these weights can be used to compensate for the different levels of variability. Select: subset selection. Action: select Fit New Model to estimate a new model from Y and X. 2009 by StatPoint Technologies, Inc. Calibration Models - 2 STATGRAPHICS – Rev. 7/3/2009 Using a Stored Model Y (measured): numeric column (or single number) containing the measured values of the quantity to be predicted. Fitted Model Statistics: column containing the statistics saved from the original model estimation. This would normally have been created using the Save Results option when the model was calibrated. The column consists of the estimated intercept, slope, and other relevant information. Action: select Predict X from Y. 2009 by StatPoint Technologies, Inc. Calibration Models - 3 STATGRAPHICS – Rev. 7/3/2009 Analysis Summary When fitting a new calibration model, the Analysis Summary shows information about the fitted model. Calibration Models - measured vs. known Y (measured): measured X (actual): known Linear model: Y = a + b*X Least Squares Parameter Estimate Intercept -0.0896667 Slope 1.01433 Standard Error 0.0643624 0.00999098 Analysis of Variance Source Sum of Squares Model 138.898 Residual 0.134757 Lack-of-Fit 0.0434233 Pure Error 0.0913333 Total (Corr.) 139.032 Df 1 10 2 8 11 T Statistic -1.39315 101.525 Mean Square 138.898 0.0134757 0.0217117 0.0114167 P-Value 0.1938 0.0000 F-Ratio 10307.30 P-Value 0.0000 1.90 0.2110 Correlation Coefficient = 0.999515 R-Squared = 99.9031 percent R-Squared (adjusted for d.f.) = 99.8934 percent Standard Error of Est. = 0.116085 Mean absolute error = 0.0923889 Durbin-Watson statistic = 1.50024 (P=0.0942) Lag 1 residual autocorrelation = 0.206661 Residual Analysis Estimation n 12 MSE 0.0134757 MAE 0.0923889 MAPE 3.07549 ME -4.81097E-16 MPE -0.982253 Validation Included in the output are: Variables and model: identification of the input variables and the model that was fit. By default, a linear model of the form Y=a+bX (1) is fit, although a different model may be selected using Analysis Options. Coefficients: the estimated coefficients, standard errors, t-statistics, and P values. The estimates of the model coefficients can be used to write the fitted equation, which in the example is measured = -0.0896667 + 1.01433 known (2) The t-statistic tests the null hypothesis that the corresponding model parameter equals 0, versus the alternative hypothesis that it does not equal 0. Small P-Values (less than 0.05 if operating at the 5% significance level) indicate that a model coefficient is significantly 2009 by StatPoint Technologies, Inc. Calibration Models - 4 STATGRAPHICS – Rev. 7/3/2009 different from 0. In the sample data, the slope is significantly different from 0 but the intercept is not. Analysis of Variance: decomposition of the variability of the dependent variable Y into a model sum of squares and a residual or error sum of squares. The residual sum of squares is further partitioned into a lack-of-fit component and a pure error component. Of particular interest are the F-tests and the associated P-values. The F-test on the Model line tests the statistical significance of the fitted model. A small P-Value (less than 0.05 if operating at the 5% significance level) indicates that a significant relationship of the form specified exists between Y and X. In the sample data, the model is highly significant. The F-test on the Lack-of-fit line tests the adequacy of the selected linear model in describing the observed relationship between Y and X. A small P-Value indicates that the selected model does not adequately describe the relationship. In such cases, a nonlinear model could be selected using Analysis Options. For the sample data, the large P-Value indicates that the linear model is adequate. Note: the lack-of-fit test is available only when more than one measurement has been obtained at the same value of X. Statistics: summary statistics for the fitted model, including: Correlation coefficient - measures the strength of the linear relationship between Y and X on a scale ranging from -1 (perfect negative linear correlation) to +1 (perfect positive linear correlation). In the sample data, the correlation is very strong. R-squared - represents the percentage of the variability in Y which has been explained by the fitted regression model, ranging from 0% to 100%. For the sample data, the regression has accounted for about 99.9% of the variability amongst the measurements. Adjusted R-Squared – the R-squared statistic, adjusted for the number of coefficients in the model. This value is often used to compare models with different numbers of coefficients. Standard Error of Est. – the estimated standard deviation of the residuals (the deviations around the model). This value is used to create prediction limits for new observations. Mean Absolute Error – the average absolute value of the residuals. Durbin-Watson Statistic – a measure of serial correlation in the residuals. If the residuals vary randomly, this value should be close to 2. A small P-value indicates a non-random pattern in the residuals. For data recorded over time, a small P-value could indicate that some trend over time has not been accounted for. Lag 1 Residual Autocorrelation – the estimated correlation between consecutive residuals, on a scale of –1 to 1. Values far from 0 indicate that significant structure remains unaccounted for by the model. Residual Analysis – if a subset of the rows in the datasheet have been excluded from the analysis using the Select field on the data input dialog box, the fitted model is used to make predictions of the Y values for those rows. This table shows statistics on the prediction errors, defined by 2009 by StatPoint Technologies, Inc. Calibration Models - 5 ei y i yˆ i STATGRAPHICS – Rev. 7/3/2009 (3) Included are the mean squared error (MSE), the mean absolute error (MAE), the mean absolute percentage error (MAPE), the mean error (ME), and the mean percentage error (MPE). This validation statistics can be compared to the statistics for the fitted model to determine how well that model predicts observations outside of the data used to fit it. Analysis Options Type of Model: the model to be estimated. All of the models displayed can be linearized by transforming either X, Y, or both. When fitting a nonlinear model, STATGRAPHICS first transforms the data, then fits the model, and then inverts the transformation to display the results. Include Constant: whether to include a constant term or intercept in the model. If the constant is removed, the fitted model will pass through the origin at (X,Y) = (0,0). The available models are shown in the following table: 2009 by StatPoint Technologies, Inc. Calibration Models - 6 STATGRAPHICS – Rev. 7/3/2009 Model Linear Square root-Y Equation y 0 1x Transformation on Y none square root Transformation on X none none Exponential y e 0 1x log none Reciprocal-Y y 0 1 x reciprocal none Squared-Y y 0 1 x square none Square root-X y 0 1 x none square root Double square root y 0 1 x y e 0 1 x square root square root log square root reciprocal square root Log-Y square root-X y 0 1x 2 1 2 1 Reciprocal-Y square root-X Squared-Y square rootX Logarithmic-X Square root-Y log-X y 0 1 x square square root y 0 1 ln( x ) none square root log log Multiplicative y 0 x 1 log log Reciprocal-Y log-X y reciprocal log y 0 1 x y 0 1 ln( x) 1 2 0 1 ln( x) Squared-Y log-X y 0 1 ln( x) square log Reciprocal-X y 0 1 / x none reciprocal Square root-Y reciprocal- X S-curve y 0 1 / x square root reciprocal log reciprocal Double reciprocal y 0 / x reciprocal reciprocal Squared-Y reciprocal-X y 0 1 / x square reciprocal Squared-X y 0 1 x 2 none square Square root-Y squaredX Log-Y squared-X y 0 1 x 2 square root square log square 2 y e 0 1 / x 1 2 2 y e 0 1 x Reciprocal-Y squared-X y 0 1 x 2 reciprocal square Double squared y 0 1 x 2 square square y/(1-y) none 1 ( y ) (inv. normal) log Logistic Log probit 1 y e 0 1x 1 e 0 1x y ( 0 1 ln( x )) 2009 by StatPoint Technologies, Inc. Calibration Models - 7 STATGRAPHICS – Rev. 7/3/2009 To determine which model to fit to the data, the output in the Comparison of Alternative Models pane described below can be helpful, since it fits all of the models and lists them in decreasing order of R-squared. Plot of Fitted Model This pane shows the fitted model or models, together with confidence limits and prediction limits if desired. Plot of Fitted Model measured = -0.0896667 + 1.01433*known 12 measured 10 8 6.52 6 4 2 6.51627 (6.25035,6.78317) 0 0 2 4 6 8 10 known The plot includes: The line of best fit or prediction equation: yˆ aˆ bˆx (4) This is the equation that would be used to predict values of the dependent variable Y given values of the independent variable X, or vice versa. Confidence intervals for the mean response at X. These are the inner bounds in the above plot and describe how well the location of the line has been estimated given the available data sample. As the size of the sample n increases, these bounds will become tighter. You should also note that the width of the bounds varies as a function of X, with the line estimated most precisely near the average value x . Prediction limits for new observations. These are the outer bounds in the above plot and describe how precisely one could predict where a single new observation would lie. Regardless of the size of the sample, new observations will vary around the true line with a standard deviation equal to . Prediction of a single value. Using Pane Options, a single prediction can be made and plotted. For example, the above plot predicts the value of X given a sample with measured value Y = 6.52. The predicted value of X equals 6.516, with 95% confidence limits extending from 6.250 to 6.783. 2009 by StatPoint Technologies, Inc. Calibration Models - 8 STATGRAPHICS – Rev. 7/3/2009 Pane Options Include: the limits to include on the plot. Confidence Level: the confidence percentage for the limits. Predict: whether to predict Y or X. Enter the value of the other variable in the At field. Mean Size or Weight: if the measured value is the average of more than one sample, enter the number of samples m used to calculate the average. Predicted Values The model can be used to predict X given Y or Y given X. In the first case, the output is shown below: Predicted Values for X 95.00% Predicted Prediction Y-bar X Lower 6.52 6.51627 6.25035 Limits Upper 6.78317 Included in the table are: Y - the measured value at which the prediction is to be made. Predicted X - the predicted value of X using the fitted model. Prediction limits - prediction limits for X at the selected level of confidence. These are the same values displayed on the plot of the fitted model. 2009 by StatPoint Technologies, Inc. Calibration Models - 9 STATGRAPHICS – Rev. 7/3/2009 Pane Options Predict: whether to predict Y or X. Confidence Level: the confidence percentage for the limits. Mean Size or Weight: if the measured value is the average of more than one sample, enter the number of samples m used to calculate the average. Predict At: up to 10 values at which to make predictions. Confidence Intervals The Confidence Intervals pane shows the potential estimation error associated with each coefficient in the model. 95.0% confidence intervals for coefficient estimates Standard Parameter Estimate Error Lower Limit CONSTANT -0.0896667 0.0643624 -0.233075 SLOPE 1.01433 0.00999098 0.992072 Upper Limit 0.0537421 1.03659 Pane Options 2009 by StatPoint Technologies, Inc. Calibration Models - 10 STATGRAPHICS – Rev. 7/3/2009 Type of Interval: either a two-sided confidence interval or a one-sided confidence bound may be created. Confidence Level: percentage level for the interval or bound. Hypothesis Tests The Hypothesis Tests pane can be used to test hypotheses about the model coefficients. In each case, a t-test is performed. The default tests are shown below: Hypothesis Tests Null hypothesis: intercept = 0.0 Alternative hypothesis: intercept not equal 0.0 Computed t statistic = -1.39315 P-value = 0.193765 Do not reject the null hypothesis for alpha = 0.05. Null hypothesis: slope = 1.0 Alternative hypothesis: slope not equal 1.0 Computed t statistic = 1.43463 P-value = 0.181919 Do not reject the null hypothesis for alpha = 0.05. The first test concerns whether or not the intercept equals 0. If so, the model goes through the origin. A small P-Value (less than 0.05 if operating at the 5% significance level) would indicate that the intercept was not equal to 0. In this case, the result is not significant, so the line may well go through the origin. If the slope of the line equals 1, a non-zero intercept would be related to bias in the measurements. The second test concerns whether or not the slope equals 1. For a linear model, a slope of 1 indicates that when the known value changes, the measured value changes by the same amount. A small P-Value would indicate that the slope was significantly different than 1. In the current case, neither null hypothesis is rejected, indicating that a possible equation for the calibration curve is measured = known. Pane Options Intercept: the value of the intercept specified by the null hypothesis. Slope: the value of the slope specified by the null hypothesis. 2009 by StatPoint Technologies, Inc. Calibration Models - 11 STATGRAPHICS – Rev. 7/3/2009 Alternative: the type of alternative hypothesis. If Not Equal is selected, a two-sided P-value is calculated. Otherwise, a one-sided P-value is calculated. Alpha: the probability of a Type I error (rejecting the null hypothesis when it is true). This does not affect the P-value, only the conclusion stated beneath it. Observed versus Predicted The Observed versus Predicted plot shows the observed values of Y on the vertical axis and the predicted values Yˆ on the horizontal axis. Plot of measured 12 observed 10 8 6 4 2 0 0 2 4 6 8 10 12 predicted If the model fits well, the points should be randomly scattered around the diagonal line. It is sometimes possible to see curvature in this plot, which would indicate the need for a curvilinear model rather than a linear model. Any change in variability from low values of Y to high values of Y might also indicate the need to transform the dependent variable before fitting a model to the data. Residual Plots As with all statistical models, it is good practice to examine the residuals. In a regression, the residuals are defined by ei y i yˆ i (5) i.e., the residuals are the differences between the observed data values and the fitted model. The Calibration Models procedure various type of residual plots, depending on Pane Options. 2009 by StatPoint Technologies, Inc. Calibration Models - 12 STATGRAPHICS – Rev. 7/3/2009 Scatterplot versus X This plot is helpful in visualizing any need for a curvilinear model. Residual Plot Studentized residual 2.8 1.8 0.8 -0.2 -1.2 -2.2 0 2 4 6 8 10 known Normal Probability Plot This plot can be used to determine whether or not the deviations around the line follow a normal distribution, which is the assumption used to form the prediction intervals. Normal Probability Plot for measured percentage 99.9 99 95 80 50 20 5 1 0.1 -2.2 -1.2 -0.2 0.8 1.8 Studentized residual If the deviations follow a normal distribution, they should fall approximately along a straight line. 2009 by StatPoint Technologies, Inc. Calibration Models - 13 STATGRAPHICS – Rev. 7/3/2009 Residual Autocorrelations This plot calculates the autocorrelation between residuals as a function of the number of rows between them in the datasheet. Residual Autocorrelations for measured autocorrelation 1 0.6 0.2 -0.2 -0.6 -1 0 2 4 6 8 lag It is only relevant if the data have been collected sequentially. Any bars extending beyond the probability limits would indicate significant dependence between residuals separated by the indicated “lag”, which would violate the assumption of independence made when fitting the regression model. Pane Options Plot: the type of residuals to plot: 1. Residuals – the residuals from the least squares fit. 2. Studentized residuals – the difference between the observed values yi and the predicted values ŷ i when the model is fit using all observations except the i-th, divided by the estimated standard error. These residuals are sometimes called externally deleted 2009 by StatPoint Technologies, Inc. Calibration Models - 14 STATGRAPHICS – Rev. 7/3/2009 residuals, since they measure how far each value is from the fitted model when that model is fit using all of the data except the point being considered. This is important, since a large outlier might otherwise affect the model so much that it would not appear to be unusually far away from the line. Type: the type of plot to be created. A Scatterplot is used to test for curvature. A Normal Probability Plot is used to determine whether the model residuals come from a normal distribution. An Autocorrelation Function is used to test for dependence between consecutive residuals. Plot Versus: for a Scatterplot, the quantity to plot on the horizontal axis. Number of Lags: for an Autocorrelation Function, the maximum number of lags. For small data sets, the number of lags plotted may be less than this value. Confidence Level: for an Autocorrelation Function, the level used to create the probability limits. Comparison of Alternative Models The Comparison of Alternative Models pane shows the R-squared values obtained when fitting each of the 27 available models: Comparison of Alternative Models Model Correlation Linear 0.9995 Double square root 0.9994 Double squared 0.9993 Double reciprocal 0.9965 Square root-Y logarithmic-X 0.9902 Multiplicative 0.9902 Square root-X 0.9891 Square root-Y 0.9850 Logarithmic-Y square root-X 0.9829 S-curve model 0.9781 Squared-Y 0.9697 Squared-X 0.9697 Logarithmic-X 0.9551 Exponential 0.9441 Squared-Y square root-X 0.9226 Square root-Y squared-X 0.9182 Reciprocal-X 0.8628 Squared-Y logarithmic-X 0.8539 Logarithmic-Y squared-X 0.8431 Squared-Y reciprocal-X 0.7174 Reciprocal-Y squared-X 0.7011 Reciprocal-Y <no fit> Reciprocal-Y square root-X <no fit> Reciprocal-Y logarithmic-X <no fit> Square root-Y reciprocal-X <no fit> Logistic <no fit> Log probit <no fit> R-Squared 99.90% 99.88% 99.87% 99.30% 98.05% 98.05% 97.83% 97.02% 96.60% 95.67% 94.04% 94.03% 91.22% 89.13% 85.12% 84.31% 74.45% 72.92% 71.09% 51.47% 49.15% The models are listed in decreasing order of R-squared. When selecting an alternative model, consideration should be given to those models near the top of the list. However, since the R- 2009 by StatPoint Technologies, Inc. Calibration Models - 15 STATGRAPHICS – Rev. 7/3/2009 Squared statistics are calculated after transforming X and/or Y, the model with the highest Rsquared may not be the best. You should always plot the fitted model to see whether it does a good job for your data. Unusual Residuals Once the model has been fit, it is useful to study the residuals to determine whether any outliers exist that should be removed from the data. The Unusual Residuals pane lists all observations that have Studentized residuals of 2.0 or greater in absolute value. Unusual Residuals Row 9 X 7.0 Y 6.81 Predicted Y 7.01067 Residual -0.200667 Studentized Residual -2.12 Studentized residuals greater than 3 in absolute value correspond to points more than 3 standard deviations from the fitted model, which is an extremely rare event for a normal distribution. Note: Points can be removed from the fit while examining the Plot of the Fitted Model by clicking on a point and then pressing the Exclude/Include button on the analysis toolbar. Excluded points are marked with an X. Influential Points In fitting a regression model, all observations do not have an equal influence on the parameter estimates in the fitted model. In a simple regression, points located at very low or very high values of X have greater influence than those located nearer to the mean of X. The Influential Points pane displays any observations that have high influence on the fitted model: Influential Points Predicted Studentized Row X Y Y Residual Leverage Average leverage of single data point = 0.166667 The table shows every point with leverage equal to 3 or more times that of an average data point, where the leverage of an observation is a measure of its influence on the estimated model coefficients. In general, values with leverage exceeding 5 times that of an average data value should be examined closely, since they have unusually large impact on the fitted model. Save Results The following results may be saved to the datasheet: 1. Model Statistics – a column of numeric values with information about the fitted model. This column can be used later to predict values of X by selecting Predict X from Y on the data input dialog box. 2. Predicted Values – the predicted value of Y corresponding to each of the n observations. 3. Lower Limits for Predictions – the lower prediction limits for each predicted value. 4. Upper Limits for Predictions – the upper prediction limits for each predicted value. 5. Lower Limits for Forecast Means – the lower confidence limits for the mean value of Y at each of the n values of X. 2009 by StatPoint Technologies, Inc. Calibration Models - 16 STATGRAPHICS – Rev. 7/3/2009 6. Upper Limits for Forecast Means– the upper confidence limits for the mean value of Y at each of the n values of X. 7. Residuals – the n residuals. 8. Studentized Residuals – the n Studentized residuals. 9. Leverages – the leverage values corresponding to the n values of X. 10. Coefficients – the estimated model coefficients. Calculations Inverse Predictions xˆ new y new ˆ o ˆ (6) 1 Lower and upper limits for xnew are found using Fieller’s approach, which solves for the values of x̂ new at which the prediction limits 1 1 xˆ x 2 yˆ t / 2,n 2 MSE new S XX m n (7) are equal to ynew, where m is the mean size or weight and n S xx xi x 2 (8) i 1 Additional calculations may be found in the Simple Regression documentation. 2009 by StatPoint Technologies, Inc. Calibration Models - 17