Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
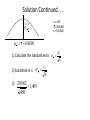
Advanced Quantitative Techniques Lab 3 Sept 22nd LAB 3: Hypothesis testing #1 Review from last week: – CI (skim over) Hypothesis testing #1 • Hypotheses • Proportion tests (prtest) – single sample, multiple samples • T-tests (ttest) • Single sample • Read more with policy examples here: http://www.urban.org/research/datamethods/data-analysis/quantitative-data-analysis/impact-analysis/paired-testing Also: • Importing from excel • Groups (by) • Errors Inferential Statistics What can we infer about the population based on a sample? • From now on, we’re estimating the population mean (μ) with the sample mean (x). • We are no longer talking about individual behavior; we’re talking about average behavior Sampling Distributions: The Key Points • We generally don’t know anything about the population distribution • We have a sample of data from the population • We assume that the average/mean is the most appropriate description of population (no more median because we assume normal distribution) • The sample is to be random and representative (“large enough”) Distribution of Means • Take a random sample over, and over, and over again (random means each data point has an equal chance of being chosen). • You get many sample means x1 , x2 , x3 , x4 , x5 ,..., x • Plot the sampling distribution of these means: you get a distribution of averages (not raw data points!) Distribution of Means • Sampling Distribution of Means: Frequency distribution (histogram) of the sample means, not of the data themselves. Frequency x Distribution of all possible sample means **This is not the distribution of x** Remember . . . • If we sample randomly from a large enough population, the distribution of the averages of the data (not the population data) is a bell curve (normal distribution). • This is the case regardless of what the population distribution looks like. Example Question We take a random sample of 450 UP graduates. The average salary is $64,800. The standard deviation of this sample is $29,882. What is the probability that if we randomly gather another group of UP grads, their average salary will be greater than $67,000? Solution n = 450 x = $64,800 s = $29,882 (sample size) (sample mean) (sample standard deviation) distribution of all sample means not data x =? x x 64,800 Solution Continued. . . x = ? n = 450 x = $64,800 s = $29,882 x x 64,800 1) Calculate the standard error: x sx 2) Substitute in s: x n 3) 29,882 450 1,409 x n Solution Continued. . . n = 450 x = $64,800 s = $29,882 x = 1,409 x x 64,800 z67,000 67,000 x x x 67,000 64,800 1.5614 1,409 Now, look up 1.5614 in the z-table P( x2 67,000) =.55.9% .4406 .054 5.4% There is a 5.9% chance that the average salary of our new sample group of UP people is > $67,000. Confidence Intervals • The goal of calculating confidence intervals is to determine how sure we are that the true population mean, μ, is approximated by the sample mean x. • We build a confidence interval around the sample mean. • Confidence intervals are only for averages, not for individual data points. How to Form a Confidence Interval To form a confidence interval we need to know: 1) x : The mean of the sample 2) σ : The standard deviation of the population (this can be approximated by using the standard deviation of the sample (s) if σ is unknown) 3) n : The size of the sample, and 4) α : estimation error = 1 – CI. One vs. two-tail? Estimation Error • α is the total estimation error (or error allowance) – α/2 on the left is the over-estimation error – α/2 on the right is under-estimation error. Overestimation Error Underestimation Error α/2 α/2 x x The CI Formula • We then use the following formula: x z* n • If we only have the sample standard deviation, then the interval can be approximated by: s xz n * Comparing Two CIs The two CIs must have the same error allowance, but they can have different n and different s. If two confidence intervals do not overlap, then they are statistically different (regardless of their n and s). If two confidence intervals do overlap, then n and s will become important for judgment. Do not compare an interval and a single average (point estimate) from two different samples unless the standard deviations and the sample sizes are the same. Comparing Two CIs s and n from both samples are the same Compare x from Sample 2 to the confidence interval from Sample 1 If x falls within the CI, the population means are statistically equal. If x falls outside the CI, the population means are statistically significantly different. s and n from the two samples are different DO NOT COMPARE! Two CIs from the two The population means are statistically equal (i.e., no difference between the samples partially two means). overlap CAN’T TELL! …because the overlap could be caused by a change in mean OR a higher variability in one of the datasets. One CI fully covers the other one (complete) overlap The population means are statistically equal (i.e., no difference between the two means). The population means are statistically equal (i.e., no difference between the two means). The CIs from the two samples do not overlap The population means are statistically significantly different The population means are statistically significantly different Single-mean hypothesis test • Hypothesis testing with a single sample enables us to make an inference about the mean (μ) of a population. 1. 2. 3. 4. 5. Which variable are you interested in? What is the null hypothesis? What is your alpha? What is the sample size? State appropriate assumptions. Null and Alternative Hypotheses Null Hypothesis (Ho): Prior belief or default belief (usually a statement of “no effect” or “no difference”) Alternative Hypothesis (H1): New way of thinking or researcher’s claim (usually what we are interested in proving) Ho and H1 are always stated in terms of population mean behavior (μ) The Ho and the H1 never overlap and are exhaustive Probability testing PR test: one sample Does less than half of the population support school prayer? Ho =? Ha = ? [one tail or two tail?] Download gss2002_chapter7 and open in STATA recode prayer (1 = 1) (2 = 0) gen schpray tab prayer schpray, missing prtest schpray == .5 Probability testing PR test cont. Treatment vs. control Policy example from each person! Import pr_test_lab3.xlsx prtest treat == control ‘Success’ = 1 Control (no change) Treated (your program) household success Household success 1 0 1 0 2 1 2 0 3 1 3 0 4 0 4 1 …40 1 …40 0 Probability testing PR test cont.: 2-sample • Treatment vs. control – another way that data might be stored Does support for school prayer vary by gender? prtest schpray, by(sex) household Success? Treated? 1 0 0 2 1 1 3 1 0 4 0 0 …40 1 1 Testing means: z vs. t - stats General rule of thumb..not always Stata Command: ttest ttest “variable” = “null hypothesis” if “the condition” , level (?) • Note that one or two “=” signs are OK in the first part of the command • Two “=” signs are required in the “if” clause • Stata defaults to 95% level • Level is the “confidence” level • Even though your alternative hypothesis may be one-tailed, the Stata command ALWAYS uses “=”. Note that putting in > or < for the ttest command will cause Stata errors Import excel sheet to STATA • Download Lab_3_Data.xls • File -> import -> excel spreadsheet -> Lab_3_Data.xls • Select “Import first row as variable names” Working Hours In the 1990s, the average workweek was 42.5 hours. In 1999, the legislature passed a bill to limit the average workweek to 40 hours. In 2000, are average work hours equal to 42.5? Use alpha 5%. H 0 : 42.5 sum hrs1 H A : 42.5 n = 1818 Dataset is a sample of the population Sample is representative. We assume the sample is random. Distribution of means is normal. α =5% = .05 ttest command ttest hrs1=42.5 if wrkstat=="working" .05 p 0.0549 p Fail to reject the null hypothesis Properties of p-values • The p-value is the probability of obtaining a test statistic at least as extreme as the one that was actually observed, assuming that the null hypothesis is true • If smaller than alpha then H1 is true • We cannot compare one p-value to that of another sample • p-value is not dependent on alpha • Compare p-value to α and decide whether or not to reject the null with p-value P-value < α reject HO P-value >= α reserve judgment on HO Interpreting Stata 1. Key values: population mean, sample mean, t-value, d.f., one/two tailed, p-value 2. Decide whether p-value is greater than or less than your alpha. 3. Reject or fail to reject null hypothesis accordingly. Working Hours: conclusions .05 p value 0.0549 p value Based on this sample of 1818 workers taken in 2000, we were unable to say that the average hours worked per week was not 42.5. We cannot conclude that the bill to reduce work hours has lowered the average workweek since 1999. However, we could have asked a bunch of workaholics or lazy workers (two-tailed) when the reality of my population is different. In this case, we would have failed to reject the null when I should have rejected it (Type II error). Errors: Alpha and Beta α = alpha = Type I error •“false positives” (see Reinhart, p. 11) •You rejected the Null Hypothesis when you shouldn’t have • Example: jury convicted innocent person • Used for making decisions about null hypotheses • Example: You found that the average number of cigarettes consumed this year is different from last year, when in fact average cigarette consumption did not change. β = beta = Type II error •“false negatives” (see Reinhart, p. 11) •You failed to reject the Null Hypothesis when you should have • Example: jury frees a guilty person • Difficult to compute – we will not quantify it in this course • Example: You found that the average number of cigarettes consumed this year is the same as last year, when in fact average cigarette consumption has changed. Do you reject the null with an alpha of 10%? .10 p value 0.0549 p value Reject the null hypothesis Based on this sample of 1818 workers taken in 2000, I found that the average hours worked per week was not equal to 42.5. I can conclude that the average hours worked are statistically significantly different since the bill was passed in 1999. However, there is a 10% chance that I made this conclusion when it is not true. For example, I might have asked a lot of people working fewer hours when in reality most people work more than the ones that I talked to. In this case, I would have rejected the null when I should have not rejected it (Type I error). Note that we only quantify type I error. Relationships / formulas standard error = SD / sq root of sample size [sample] [pop estimate] [sample] t statistic = sample mean – pop mean / standard error