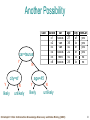
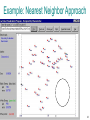
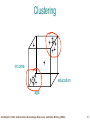
Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
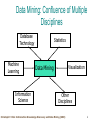
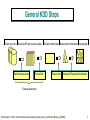
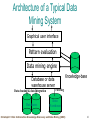
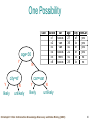
Promising “Newer” Technologies to Cope with the Information Flood Knowledge Discovery and Data Mining (KDD) Agent-based Technologies Ontologies and Knowledge Brokering Non-traditional data analysis techniques Model Generation As an Example To Explain / Discuss Technologies Christoph F. Eick: Introduction Knowledge Discovery and Data Mining (KDD) 1 Knowledge Discovery in Data [and Data Mining] (KDD) Let us find something interesting! Definition := “KDD is the non-trivial process of identifying valid, novel, potentially useful, and ultimately understandable patterns in data” (Fayyad) Frequently, the term data mining is used to refer to KDD. Many commercial and experimental tools and tool suites are available (see http://www.kdnuggets.com/siftware.html) Field is more dominated by industry than by research institutions Christoph F. Eick: Introduction Knowledge Discovery and Data Mining (KDD) 2 Making Sense of Data --Knowledge Discovery and Data Mining 2005 Lectures 1. 2. 3. 4. 5. 6. 7. Introduction to KDD Similarity Assessment Clustering Classification (very very brief) Association Rule Mining Spatial Databases and Spatial Data Mining Data Warehouses and OLAP Christoph F. Eick: Introduction Knowledge Discovery and Data Mining (KDD) 3 Data Mining: Confluence of Multiple Disciplines Database Technology Machine Learning Information Science Statistics Data Mining Visualization Other Disciplines Christoph F. Eick: Introduction Knowledge Discovery and Data Mining (KDD) 4 General KDD Steps Data sources Selected/Preprocessed data Select/preprocess Transform Transformed data Extracted information Knowledge Data mine Interpret/Evaluate/Assimilate Data preparation Christoph F. Eick: Introduction Knowledge Discovery and Data Mining (KDD) 5 Popular KDD-Tasks Classification (try to learn how to classify) Clustering (finding groups of similar object) Estimation and Prediction (try to learn a function that predicts an th value of a continuous output variable based on a set of input variables) Bayesian and Dependency Networks Deviation and Fraud Detection Text Mining Web Mining Visualization Transformation and Data Cleaning Christoph F. Eick: Introduction Knowledge Discovery and Data Mining (KDD) 6 KDD and Classical Data Analysis KDD is less focused than data analysis in that it looks for interesting patterns in data; classical data analysis centers on analyzing particular relationships in data. The notion of interestingness is a key concept in KDD. Classical data analysis centers more on generating and testing pre-structured hypothesis with respect to a given sample set. KDD is more centered on analyzing large volumes of data (many fields, many tuples, many tables, …). In a nutshell the the KDD-process consists of preprocessing (generating a target data set), data mining (finding something interesting in the data set), and post processing (representing the found pattern in understandable form and evaluated their usefulness in a particular domain); classical data analysis is less concerned with the the preprocessing step. KDD involves the collaboration between multiple disciplines: namely, statistics, AI, visualization, and databases. KDD employs non-traditional data analysis techniques (neural networks, association rules, decision trees, fuzzy logic, evolutionary computing,…). Christoph F. Eick: Introduction Knowledge Discovery and Data Mining (KDD) 7 Generating Models as an Example The goal of model generation (sometimes also called predictive data mining) is the creation, evaluation, and use of models to make predictions and to understand the relationships between various variables that are described in a data collection. Typical example application include: – generate a model to that predicts a student’s academic performance based on the applicants data such as the applicant’s past grades, test scores, past degree,… – generate a model that predicts (based on economic data) which stocks to sell, hold, and buy. – generate a model to predict if a patient suffers from a particular disease based on a patient’s medical and other data. Model generation centers on deriving a function that can predict a variable using the values of other variables: v=f(a1,…,an) Neural networks, decision trees, naïve Bayesian classifiers and networks, regression analysis and many other statistical techniques, fuzzy logic and neurofuzzy systems, association rules are the most popular model generation tools in the KDD area. All model generation tools and environments employ the basic train-evaluatepredict cycle. 8 Christoph F. Eick: Introduction Knowledge Discovery and Data Mining (KDD) Why Do We Need so many Data Mining / Analysis Techniques? No generally good technique exists. Different methods make different assumptions with respect to the data set to be analyzed (to be discussed on the next transparency) Cross fertilization between different methods is desirable and frequently helpful in obtaining a deeper understanding of the analyzed dataset. Christoph F. Eick: Introduction Knowledge Discovery and Data Mining (KDD) 9 Motivation: “Necessity is the Mother of Invention” Data explosion problem – Automated data collection tools and mature database technology lead to tremendous amounts of data stored in databases, data warehouses and other information repositories We are drowning in data, but starving for knowledge! Solution: Data warehousing and data mining – Data warehousing and on-line analytical processing – Extraction of interesting knowledge (rules, regularities, patterns, constraints) from data in large databases Christoph F. Eick: Introduction Knowledge Discovery and Data Mining (KDD) 10 Why Data Mining? — Potential Applications Database analysis and decision support – Market analysis and management • target marketing, customer relation management, market basket analysis, cross selling, market segmentation – Risk analysis and management • Forecasting, customer retention, improved underwriting, quality control, competitive analysis – Fraud detection and management Other Applications – Text mining (news group, email, documents) and Web analysis. – Intelligent query answering Christoph F. Eick: Introduction Knowledge Discovery and Data Mining (KDD) 11 Market Analysis and Management Where are the data sources for analysis? – Credit card transactions, loyalty cards, discount coupons, customer complaint calls, plus (public) lifestyle studies Target marketing – Find clusters of “model” customers who share the same characteristics: interest, income level, spending habits, etc. Determine customer purchasing patterns over time – Conversion of single to a joint bank account: marriage, etc. Cross-market analysis – Associations/co-relations between product sales – Prediction based on the association information Christoph F. Eick: Introduction Knowledge Discovery and Data Mining (KDD) 12 Fraud Detection and Management Applications – widely used in health care, retail, credit card services, telecommunications (phone card fraud), etc. Approach – use historical data to build models of fraudulent behavior and use data mining to help identify similar instances Examples – auto insurance: detect a group of people who stage accidents to collect on insurance – money laundering: detect suspicious money transactions (US Treasury's Financial Crimes Enforcement Network) – medical insurance: detect professional patients and ring of doctors and ring of references Christoph F. Eick: Introduction Knowledge Discovery and Data Mining (KDD) 13 Other Applications Sports – IBM Advanced Scout analyzed NBA game statistics (shots blocked, assists, and fouls) to gain competitive advantage for New York Knicks and Miami Heat Astronomy – JPL and the Palomar Observatory discovered 22 quasars with the help of data mining Internet Web Surf-Aid – IBM Surf-Aid applies data mining algorithms to Web access logs for market-related pages to discover customer preference and behavior pages, analyzing effectiveness of Web marketing, improving Web site organization, etc. Christoph F. Eick: Introduction Knowledge Discovery and Data Mining (KDD) 14 Data Mining and Business Intelligence Increasing potential to support business decisions Making Decisions Data Presentation Visualization Techniques Data Mining Information Discovery End User Business Analyst Data Analyst Data Exploration Statistical Analysis, Querying and Reporting Data Warehouses / Data Marts OLAP, MDA Data Sources Paper, Files, Information Providers, Database Systems, OLTP Christoph F. Eick: Introduction Knowledge Discovery and Data Mining (KDD) DBA 15 Architecture of a Typical Data Mining System Graphical user interface Pattern evaluation Data mining engine Knowledge-base Database or data warehouse server Data cleaning & data integration Databases Filtering Data Warehouse Christoph F. Eick: Introduction Knowledge Discovery and Data Mining (KDD) 16 Example: Decision Tree Approach Christoph F. Eick: Introduction Knowledge Discovery and Data Mining (KDD) 17 Decision Tree Approach2 Christoph F. Eick: Introduction Knowledge Discovery and Data Mining (KDD) 18 Decision Trees Example: • Conducted survey to see what customers were interested in new model car • Want to select customers for advertising campaign sale custId c1 c2 c3 c4 c5 c6 car taurus van van taurus merc taurus age 27 35 40 22 50 25 city newCar sf yes la yes sf yes sf yes la no la no Christoph F. Eick: Introduction Knowledge Discovery and Data Mining (KDD) training set 19 One Possibility sale custId c1 c2 c3 c4 c5 c6 age<30 Y N city=sf Y likely car taurus van van taurus merc taurus age 27 35 40 22 50 25 city newCar sf yes la yes sf yes sf yes la no la no car=van N unlikely Y likely N unlikely Christoph F. Eick: Introduction Knowledge Discovery and Data Mining (KDD) 20 Another Possibility sale custId c1 c2 c3 c4 c5 c6 car=taurus Y N city=sf Y likely car taurus van van taurus merc taurus age 27 35 40 22 50 25 city newCar sf yes la yes sf yes sf yes la no la no age<45 N unlikely Y likely N unlikely Christoph F. Eick: Introduction Knowledge Discovery and Data Mining (KDD) 21 Example: Nearest Neighbor Approach Christoph F. Eick: Introduction Knowledge Discovery and Data Mining (KDD) 22 Clustering income education age Christoph F. Eick: Introduction Knowledge Discovery and Data Mining (KDD) 23 Another Example: Text Each document is a vector – e.g., <100110...> contains words 1,4,5,... Clusters contain “similar” documents Useful for understanding, searching documents sports international news business Christoph F. Eick: Introduction Knowledge Discovery and Data Mining (KDD) 24 Issues Given desired number of clusters? Finding “best” clusters Are clusters semantically meaningful? – e.g., “yuppies’’ cluster? Using clusters for disk storage Christoph F. Eick: Introduction Knowledge Discovery and Data Mining (KDD) 25 Association Rule Mining sales records: tran1 tran2 tran3 tran4 tran5 tran6 cust33 cust45 cust12 cust40 cust12 cust12 p2, p5, p1, p5, p2, p9 p5, p8 p8, p11 p9 p8, p11 p9 market-basket data Example Rules: 1. 2. age(X, “20..29”) ^ income(X, “20..29K”) buys(X, “PC”) [support = 2%, confidence = 60%] buys(x, p2) ^ buys(x,p5) bus(x,p8) [1%, 85%] Christoph F. Eick: Introduction Knowledge Discovery and Data Mining (KDD) 26 Characteristics and Assumptions of Popular Data Mining/Analysis Techniques Distance based approaches (assume that a distance function with respect to the objects in the dataset exists) vs. order-based approaches (just use the ordering of values in their decision making; 3>2>1 is indistinguishable from 2.01>2>1.99) Approaches that make no assumptions / assume a particular distribution of the data in the underlying dataset. Differences in employed approximation techniques – Rectangular vs. other approximation – Linear vs. non-linear approximations Sensitivity to redundant attributes (variables) Sensitivity to irrelevant attributes Sensitivity to attributes of different degrees of importance Different Training Performance / Testing Performance What does the learnt function tell us about the analyzed data set? How difficult is it to understand the learnt function? Deterministic / non-deterministic approaches Stability of the obtained results Christoph F. Eick: Introduction Knowledge Discovery and Data Mining (KDD) 27 Summary KDD KDD: discovering interesting patterns from large amounts of data A natural evolution of database technology, in great demand, with wide applications A KDD process includes data cleaning, data integration, data selection, transformation, data mining, pattern evaluation, and knowledge presentation Mining can be performed in a variety of information repositories Data mining functionalities: characterization, discrimination, association, classification, clustering, outlier and trend analysis, etc. Multi-disciplinary activity Important Issues: KDD-methodologies and user-interactions, scalability, tool use and tool integration, preprocessing, interpretation of results, finding good parameter settings when running data mining tools,… Christoph F. Eick: Introduction Knowledge Discovery and Data Mining (KDD) 28 Where to Find References? Data mining and KDD (SIGKDD member CDROM): – Conference proceedings: KDD, and others, such as PKDD, PAKDD, etc. – Journal: Data Mining and Knowledge Discovery Database field (SIGMOD member CD ROM): – Conference proceedings: ACM-SIGMOD, ACM-PODS, VLDB, ICDE, EDBT, DASFAA – Journals: ACM-TODS, J. ACM, IEEE-TKDE, JIIS, etc. AI and Machine Learning: – Conference proceedings: Machine learning, AAAI, IJCAI, etc. – Journals: Machine Learning, Artificial Intelligence, etc. Statistics: – Conference proceedings: Joint Stat. Meeting, etc. – Journals: Annals of statistics, etc. Visualization: – Conference proceedings: CHI, etc. – Journals: IEEE Trans. visualization and computer graphics, etc. Christoph F. Eick: Introduction Knowledge Discovery and Data Mining (KDD) 29