Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
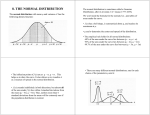
2.1 Describing Location in a Distribution Do You Sudoku? Each of you get a Sudoku puzzle; your work alone; no talking; no consulting each other Get your phone out so you may time yourself (use the stopwatch); total time will be rounded to the nearest 10th of a minutes (i.e., 4.3 minutes) Your total time includes you checking your Sudoku to make sure it is correct & complete Let’s make sure we all understand how to do a sudoku puzzle; https://www.youtube.com/watch?v=OtKxtvMUahA Your Sudoku times… Write your times on the board; copy all data on your Sudoku; be sure to indicate which time is YOURS (we will use these more tomorrow) What can we say about our distribution of times? What type of graphical representation should we choose to display our data? SOCS (review) Where do YOU stand within the distribution? Review/Preview mean, standard deviation (what are these?) primarily histograms (or dot plots or stem plots) median, Q1, Q3 (what are these?) (primarily) box plots What is meant by Q1? By Q3? PREVIEW: mean & standard deviation density curves z-scores, measures of location of data relative to mean (# of SD’s from mean) Percentile The pth percentile of a distribution is the value with p percent of the observations (= to or) less than it. Q1 25th percentile 25% of the distribution is equal to or less than that given value within the distribution Q3 75th percentile 75% of the distribution is equal to or less than that given value within the distribution Our sudoku times… Q1 and Q3 are percentiles that are used often However we can calculate any percentile; i.e., 18th percentile, 79th percentile, 99th percentile, etc. What is your percentile (comparing your time with everyone else’s time)? What is your guess? In this case if a low percentile good or is a high percentile good? Sudoku percentiles… How many sudoku times do we have? Count where yours is; then divide by total Count all times below yours; then divide by total Either calculation is acceptable as your percentile Is it good to be in a low percentile or a high percentile for this distribution? How about for test scores? Times 0 – 59 seconds 60 – 119 seconds Frequency Sudoku frequency table… 120 – 179 seconds 180 – 239 seconds 240 – 299 seconds 300 – 359 seconds 360 – 419 seconds 420 – 479 seconds 480 – 539 seconds 540 – 599 seconds 600 – 659 seconds 660 – 719 seconds 720 + seconds Sudoku frequency table… Times 0 – 59 seconds 60 – 119 seconds 120 – 179 seconds 180 – 239 seconds 240 – 299 seconds 300 – 359 seconds 360 – 419 seconds 420 – 479 seconds 480 – 539 seconds 540 – 599 seconds Frequency Now let’s expand to include relative frequency, cumulative frequency and cumulative relative frequency Times 0 – 59 seconds 60 – 119 seconds 120 – 179 seconds 180 – 239 seconds 240 – 299 seconds 300 – 359 seconds 360 – 419 seconds 420 – 479 seconds 480 – 539 seconds 540 – 599 seconds 600 – 659 seconds Frequency Relative Frequency Cumulative Frequency Cumulative Relative Frequency Cumulative Relative Frequency Graph (or “ogive”) … example from text, age of U. S. presidents on day of inauguration Ogive for our Sudoku data… Measuring position: z-scores… Are you happy with your test score in Physics? You earned a 78/100 on your test. Are you satisfied? How about if everyone else earned 98/100, 99/100, and 100/100? How about if everyone else earned 54/100, 61/100, 45/100, etc.? It’s all about how YOU did compared to others who took the Physics test. In chapter 1... we described entire sets of data (SOCS) now focus on individual observations (and how that observation compares to the entire distribution) Similar to percentiles; how you did on your Sudoku time versus how everyone else did _____ earned an 86%... All the scores for that Physics test were: 67 75 80 79 81 77 73 83 74 93 72 77 82 77 83 90 79 85 83 89 73 80 78 86 84 Input data into list, do 1-var stats Mean? Median? SD? mean ( x ) = 80 median = 80 s = 6.07 So, 86 is above average, but by how much? ≈ 1 standard deviation Another measure relative standing (besides percentile) that is used very often in statistics z-scores Z-Scores z-scores are one way to describe a particular data point in a distribution via the # of SD’s above or below mean (remember what standard deviation is ...how much variation exists from the mean; measure of spread) Standardizing a Value When we ‘standardize’ a data value, we convert the raw data or original data to standard deviation units So 86% (raw, original data) on Physics test once standardized converts to a standardized value of ≈ 1 (number of SD’s away from mean) Z-Score Formula x mean z SD # of SD’s (+ or -) away from mean; directional 86% on Physics test ... Remember ... x = 80 s = 6.07 So ≈ 1 SD above mean Now calculate exactly 86 80 z 0.99 6.07 x mean z SD Z-Scores, Standardizing, # of SD’s Away From Mean Got 93/100. Calcuate z-score. • Got 72%. Calculate z-score x mean z SD Z-Scores, Standardizing, # of SD’s Away From Mean 93/100 raw score 72% raw score 93 80 z 2.14 6.07 72 80 z 1.32 6.07 Now on to AP Statistics... 82% on an AP Stats test. Disappointed? Happy? (relative to 86 on Physics test) AP Stats distribution of test scores was fairly symmetric with 𝑥 = 76, s = 4 Calculate z-score for 82% on AP Stats test. AP Stats Test Score 82 76 z 1.5 4 Raw score: lower than Physics test score (82% vs. 86%) Relative to everyone else who took each test: better; z- score of 1.5; 1 ½ SDs above mean Z-Scores, Standardizing, # of SD’s Away From Mean Standardize (raw score changes to z-score) observations from distributions to express relative standing in a distribution Standardize (change to z-scores) observations to express values from two or more observations on a common scale (i.e., 8-year old with height 5 foot vs. 18year old with height 5 foot) ACT vs. SAT scores; different scales REVIEW…Measuring Relative Standing: Percentile Can also describe performance on Physics test or AP Stats test by using percentiles. pth percentile of a distribution as a value with p percent of observations at or below it. Measuring Relative Standing: Percentile Go to list of physics test scores; sort ascending Score of 86/100 on Physics test is where on list? 22nd on list; so 22/25 = 88th percentile 88th percentile; 88% of students are at or below a test score of 86/100 Measuring Relative Standing: Percentile How about test score of 72/100? Only 2 at or below 72/100; so 2/25 = .08 8th percentile; 8% of students are at or below a test score of 72/100 Measuring Relative Standing: Percentile Note: Some textbooks define the pth percentile of a distribution as the value with p percent of observations BELOW the given value. If this is the case, it is never possible for an individual to fall at the 100th percentile AP readers & me: either acceptable Transforming Data… Transforming data… Think about the last time you went out to dinner. How much was the bill? Write on the board (round to nearest dollar) Input into lists Do 1-var stats; What is 𝑥 ? What is s? How about other key values, like Q1, Q3, etc.? Graph it (let’s do a histogram) Transforming data… The chef prepared such a delicious meal we want to ‘tip’ her. We are going to tip the chef $10 Input new values into other list (+$10 each entry) 1-var stats; What is 𝑥 ? What is s? How about other key values like Q1, Q3, etc.? Graph it (again); let’s do a histogram Transforming data… So, what do you think happens when we add (or subtract) an amount to a distribution? Shape unchanged Spread unchanged Everything (all/each data point) just moved to right or left, including the center Transforming data… Now, instead of dining in Santa Clarita, we go to exact restaurant but in Beverly Hills They charge 20% more for their menu offerings We order the same thing Take original distribution and multiply by 20% Transforming data… 1-var stats What is 𝑥 ? What is s? How about other key values like Q1, Q3, etc.? Graph new data (histogram) Transforming data… So, what do you think happens when we multiply (or divide) a distribution? Shape unchanged Everything (each/all data points) else is increased/decreased, including center AND spread Linear Transformation A linear transformation changes the original variable x into the new variable xnew given by an equation of the form xnew = a + bx Adding/subtracting the constant a shifts all values of x upward or downward by the same amount. Multiplying/dividing by the positive constant b changes the size of the unit of measurement. Linear Transformation Effects Multiplying (or dividing) each observation by a positive number b multiplies (or divides) both measures of center (mean and median) and measures of spread (interquartile range and standard deviation) by b. Everything changes except the shape of the distribution Adding (or subtracting) the same number a (either positive, zero, or negative) to each observation adds (or subtracts) a to measures of center and location (mean, median, quartiles, percentiles) but does not change measures of spread (IQR, standard deviation) nor shape of distribution. Other examples of linear transformations… Consider a data set of summer temperatures (in Fahrenheit) of all 50 U. S. states Decided we want those temperatures in Celsius (not Fahrenheit) Conversion: subtract 32, then divide by 9 Z-scores… how are these linear transformations? What is the formula to convert to a z-score? Review… what are z-scores? Homework… Page 99, #1, 3, 5, 9 (skip part ‘c’), 11, 13, 15, 19, 21, 23 Page 99, #25- #30 MC SECTION 2-1 HW QUIZ TOMORROW … 2.2 Density Curves & Normal Distributions… Key Strategies Used for Exploring Uni-variate Distributions Always plot data, make a graph (usually box plot, stem plot, histogram, dot plot) Look for overall patterns (SOCS) Calculate numerical summary (1-var stats) New Step for Uni-variate Data… • Sometimes the overall pattern of a large number of observations is so regular we can describe it by a smooth curve (density curve) model Density Curves (in general) Fairly symmetric, uni-modal, no gaps/outliers Good description of data, good mathematical model for distribution Often easier to use and fairly accurate Idealized description Ignore minor irregularities Fill in bars density curve Density Curves Model… NOTE: all ‘models’ are wrong, but some are very helpful Density curves fits this description well Essential Characteristics of Density Curves Density curves are always… • On or above horizontal axis • Have an area of exactly 1 under it • Describe an overall pattern of a distribution. • And … Characteristics of Density Curves Area under density curve and above any interval of values on the horizontal axis is the proportion of all observations that fall in that interval. Side Note on Density Curves … • This material is introductory only • Density curves can be many shapes (uniform, bimodal, etc.) • Real power of density curves comes when the function/distribution is Normal or approximately Normal • Normal (or fairly Normal) distributions are KEY for the entire course Density Curves & Mean/Median Don’t worry about locating mean and median by eye on density curve Will use mathematical methods to locate Just know, in general: Sample vs. Population (statistic) Sample Mean 𝑥 (parameter) Population µ Standard Deviation s σ Density Curves… Usually for density curves we will use µ and σ Normal Distributions Important type of density curves Good descriptor/model of many real-life data sets, such as test scores, biology, heights, weights, outcomes of chance, inference, etc. Normal Distributions Symmetric, single-peaked (uni-modal) Bell-Shaped Mean ≈ Median (very close in value) & represents highest point on density curve All are same basic shape More criteria later … Normal Distributions Exact density curve for particular Normal distribution is described by its mean µ and its standard deviation σ. Investigating Normal Distributions… See your activity in your data & questions called “Investigating Normal Distributions” 68-95-99.7 Rule (Empirical Rule) If Normal distribution with mean µ and standard deviation σ, then: 68% of observations fall within 1 SD’s of µ 95% of observations fall within 2 SD’s of µ 99.7% of observations fall within 3 SD’s of µ 68-95-99.7 Rule (Empirical Rule) For Normal Distributions Only Normal Distributions Notation: If a distribution is considered Normal, then notation to identify that distribution as Normal is: N ( µ, σ ) Normal distribution with mean µ and SD σ. Girls… who considers themselves short? Females in class who consider themselves short (names and heights in inches) Actress you think is short? (height in inches) Athlete you consider short? (height in inches) Who considers themselves tall? Average height? “Short” Girls • Distribution of heights (in inches) of young women aged 18 to 24 is approximately Normal. • N (64.5, 2.5) • So how ‘short’ are these females? “Short Girls” The Standard Normal Distribution Many Normal density curves/distributions, depending on µ and σ. But ALL standard Normal density curves are the SAME because they are STANDARDIZED to z-scores. 𝑥−𝜇 𝑧= 𝜎 Standard Normal Distribution: N (0, 1) Standard Normal Distribution Note: If variable/distribution we standardize has a Normal distribution, then so does the new variable, z (linear transformation) Standard Normal Calculations Four cases for finding area under a curve Area to right, area to left, area ‘inside’ and area ‘outside’ (see drawings) There is a proportion of observations that lie in some range of values. How do we find this area under the curve? Standard Normal Table (Table A) Area to LEFT of value Standard Normal Table (Table A) Practice: Find the area under the curve such that …(sketch each curve) • z < 1.5 • z < -2.17 • z<0 • z > -1 • z > 3.04 • z > -2.42 Standard Normal Table (Table A) More practice… sketch curves. • -1 < z < 1 • -1.4 < z < 1.07 • 0.49 < z < 0.99 • 0 < z < 3.49 • z < -1 or z > 1.9 • z < 1.55 or z > 3.01 • z < -3 or z > 3 Is cholesterol a problem for boys? The level of cholesterol in the blood is important because high cholesterol levels may increase the risk of heart disease. The distribution of blood cholesterol levels in a large population of people of the same age and gender is roughly Normal. For 14-year old boys, the mean is µ = 170 milligrams of cholesterol per deciliter of blood (mg/dl) and the standard deviation is σ = 30 mg/dl. Is cholesterol a problem for boys? µ = 170 mg/dl σ = 30 mg/dl Draw density curve and label with raw data /information. Is cholesterol a problem for boys? • Table A is standardized (not raw data). • Now draw a standardized density curve (change to z- scores). • Think about how we are changing the scale on this density curve… input µ and σ … x mean z SD Is cholesterol a problem for boys? What proportion of cholesterol levels are at or below 170 mg/dl? Use regular density curve then use the standardized density curve. Shade in area. Answer in context, always. Draw and mark up the density curve, always. Is cholesterol a problem for boys? What proportion of cholesterol levels are at or below 140 mg/dl? Sketch the density curve and shade in area. Can you use your raw-score density curve to determine this proportion? Or do you need to use your standardized density curve? Is cholesterol a problem for boys? You must standardize your data value. µ = 170 mg/dl σ = 30 mg/dl x mean z SD Is cholesterol a problem for boys? 140 170 z 1 30 Now that we have a z-score, we can use Table A (remember reads to left) So, proportion of cholesterol levels at or below 140 is about 15.87%. Is cholesterol a problem for boys? What proportion of cholesterol levels are at or below 110 mg/dl? What proportion of cholesterol levels are at or below 187 mg/dl? Share answers and sketches. Include context always! Sketch always! Is cholesterol a problem for boys? What proportion of cholesterol levels are at or above 200 mg/dl? What proportion of cholesterol levels are at or above 115 mg/dl? Share answers and sketches. Include context always! Sketch always! Is cholesterol a problem for boys? What proportion of cholesterol levels are between 137 mg/dl and 224 mg/dl? Share answers and sketches. Include context always! Sketch always! Calculator Time • Need to know how to do these calculations using Table A. Definitely. • But, calculator can also do calculations. Easier, faster. • Calculator vs. Table A: Are they the same? • normalcdf (low, high, µ, σ ); second-vars, 2 • If you use your calculator, then you MUST: draw, shade, label density curve; calculate (define input), answer in context (always!) • Let’s try some of these problems with calculator now Working Backwards… Given a proportion, find the x, the raw specific value in your distribution. x mean z SD Working Backwards… What is the cholesterol level for a 14-year old boy for him to be in the top 25% of population? µ = 170 mg/dl σ = 30 mg/dl Draw density curve, labeled with µ and σ; area shaded. Working Backwards… • Remember, Table A is value at or below • So want to look up 0.75 (not 0.25) • Look in body of Table A (body is area under density curve; that’s what we have) • Area of 0.75 to left corresponds to z = 0.67 Working Backwards … x 170 0.67 30 A 14-year old boy would have to have a cholesterol level of 190.1 mg/dl for him to be in the top 25% of population. invnorm (area, µ, σ) Normal Distribution Criteria Criteria for a distribution to be considered Normal? symmetric Uni-modal mean ≈ median 68-95-99.7 … and …. one more thing… Normal Distribution Criteria Unless problem situation clearly states that the distribution is Normal or fairly Normal… It is risky to assume a distribution is (fairly) Normal without creating a Normal Probability Plot (NPP) Note: You need raw data to create a NPP Often you will be given a NPP and you must interpret it Normal Distribution Criteria If points on NPP lie close to a straight line, then data is Normal (or fairly Normal). If points on a NPP do not lie close to a straight line, data is not Normal. Outliers appear far away from the overall pattern in NPP. Normal Probability Plot Normal Probability Plots Normal Probability Plot Write on board number of pets you own Enter into L1 Create NPP (together) According to our NPP, is our data Normal? Why or why not? Caution: Normal vs. Fairly Normal • If problem states Normal, then data is Normal; Exactly. • If problem doesn’t state Normal: check for … discuss with partner for 1 minute • Unimodal, symmetric, mean ≈ median, 68-95-99.7, and NPP… means FAIRLY NORMAL • If Normal, mean it. If fairly Normal, mean it. Homework… Page 128 #33, 35, 37, 39, 41, 43, 45, 47, 49, 51, 53, 55, 57, 61, 63, 65, 67 MC: #69 – 74 Case Closed… Pg 126 & 127 On line MC FRQ’s Read chapter review pg 134 Chapter 2 ap stats practice test (?) Chapter 2 review exercises FRAPPY