Survey
* Your assessment is very important for improving the workof artificial intelligence, which forms the content of this project
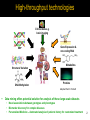
Discovering Combinatorial Biomarkers Vipin Kumar [email protected] http://www.cs.umn.edu/~kumar Department of Computer Science and Engineering ICCABS, Feb 2012 High-throughput technologies Clinical Data e.g. brain imaging SNP Structural Variation DNA Methylation Gene Expression & non-coding RNA Metabolites Proteins Adopted from E. Schadt Data mining offers potential solution for analysis of these large-scale datasets • • • Novel associations between genotypes and phenotypes Biomarker discovery for complex diseases Personalized Medicine – Automated analysis of patients history for customized treatment 2 Biomarker Discovery and its Impact Biomarkers: Genes: BRCA1 (breast cancer) Protein variants IVS5-13insC (type 2 diabetes) Pathways/networks: P53 (cancers) Clinical Impact: Diagnosis Prognosis Treatment fMRI Schizophrenia vs controls Lim et al. Miki et al. 1994 Chiefari et al. 2011 Oren et al. 2010 3 Published Genome-wide Associations through 06/2010 1,904 published GWA at p≤5*10-8 for 165 traits SNP as an illustration NHGRI GWA Catalog www.genome.gov/GWAStudies 4 Published Genome-wide Associations through 06/2011 1,449 published GWA at p≤5*10-8 for 237 traits 50% increase in one year SNP as an illustration NHGRI GWA Catalog www.genome.gov/GWAStudies 5 Challenge: Limitations of Single-locus Association Test High coverage but low odds ratio (1.2) High odds ratio (15.9) but low coverage (7%) Many other studies No significant associations 6 A Example where Single-locus Test Led to No Significant Associations • Given a SNP data set of Myeloma patients, find SNPs that are associated with short vs. long survival. 3404 SNPs • • • 3404 SNPs selected from various regions of the chromosome 70 cases (Patients survived shorter than 1 year) 73 Controls (Patients survived longer than 3 years) Myeloma Survival Data cases Controls Van Ness et al 2008 Top ranked SNP: -log10P-value = 3.8; Odds Ratio = 3.7 Myeloma SNP data has signal the need of discovering combinations of SNPs 7 Single-locus Tests Ignore Genetic Interaction Non-additive effect “Genetic Interaction” Ripke et al. 2011 Extensively observed in model organisms, e.g. yeast, C. elegans, fly. Costanzo et al. 2010 Scholl et al. 2009 Ruzankina et al. 2009 Kamath, 2003 8 The focus of this talk: Higher-order Combinatorial Biomarker ...... Complex biological system Complex human diseases Higher-order genetic buffering Triple mutations only exist in disease subjects Control Disease A synthetic pattern 9 Discovering High-order Combinatorial Biomarkers Challenge I: Computational Efficiency Given n features, there are 2n candidates! The Apriori framework for efficient search of exponential space How to effectively handle the combinatorial search space? Millions of user, thousands of items Brute-force search e.g. MDR can only handle 10~100 SNPs. [Rita et al. 2001] Support based pruning null Disqualified A B C D E AB AC AD AE BC BD BE CD CE DE ABC ABD ABE ACD ACE ADE BCD BCE BDE CDE ABCD ABCE ABDE ABCDE Prune all the supersets ACDE BCDE + + [Agrawal et al. 1994] 10 Discovering High-order Combinatorial Biomarkers Challenge I: Computational Efficiency • Traditional Apriori-based pattern mining techniques • Designed for sparse data • Unique challenges of genomic datasets • High density • A SNP dataset has a density of 33.33% • Three binary columns per SNP the three genotypes • High dimensionality • Makes the search more challenging • Disease heterogeneity • Each combination supported by a small fraction of subjects A novel anti-monotonic objective function designed for mining low-support discriminative patterns from dense and high-dimensional data [Fang et al. TKDE 2010] 11 Discovering High-order Combinatorial Biomarkers Challenge II: Statistical Power • null A B C D E Computational challenges can be addressed by • Better algorithm design, • e.g. Apriori-based • High-performance computing AB AC AD AE BC BD BE CD CE DE • ABC ABD ABE ABCD ACD ABCE ACE ADE ABDE BCD ACDE BCE BCDE BDE CDE Statistical challenges call for additional efforts • Limited sample size • Huge number of hypothesis tests Many combinations are trivial extensions of their subsets ABCDE Myeloma Survival Data Kidney Rejection Data Lung Cancer Data Subsets having lower association Subsets having higher association Targeting patterns with better association than their subsets reduces # of hypothesis tests [Fang, Haznadar, Wang, Yu, Steinbach, Church, Oetting, VanNess, Kumar, PLoS ONE, 2012] 12 High-order Combinatorial Biomarkers: an example Patients Size-5 Best Best size-4 Best size-3 Best size-2 size-1 Control All heavy smokers Lung Cancer Data Jump Data from Church et al. 2010 The five genes are functionally related www.ingenuity.com [Fang, Pandey, Wang, Gupta, Steinbach and Kumar, IEEE TKDE, 2012] [Fang, Haznadar, Wang, Yu, Steinbach, Church, Oettng, Van Ness and Kumar, PLoS ONE, 2012] 13 Insights on High-order Functional Interactions Patterns with positive Jump are functionally more coherent Lungcancer Lung cancer dataset Size-5 Control Best Best size-4 Best size-3 Best size-2 size-1 Kidney Rejection Data Lung Cancer Data Jump Combined 14 [Fang, Haznadar, Wang, Yu, Steinbach, Church, Oettng, Van Ness and Kumar, PLoS ONE, 2012] High-order Combinations Discovered from Different Types of Data mRNA: Breast Cancer Data from Oetting et al. 2008 AE COPD Metabolites: COPD Stable COPD Control No-rejection Rejection Survived (5-year) SNP: acute kidney rejection Data from Vijver et al. 2002 Data from Wendt et al. 2010 The proposed framework is general to handle different types of data [Fang, Pandey, Wang, Gupta, Steinbach and Kumar, IEEE TKDE, 2012] [Fang, Haznadar, Wang, Yu, Steinbach, Church, Oettng, Van Ness and Kumar, PLoS ONE, 2012] 15 Biomarker Discovery using Error-tolerant Patterns True patterns are fragmented due to noise and variability Possible solution: Error-tolerant patterns • X 0 1 1 1 0 0 1 0 1 0 1 1 0 0 0 1 1 1 0 1 1 0 0 0 1 1 1 0 0 0 0 0 0 0 1 0 1 1 1 1 1 0 0 1 1 1 1 1 0 0 0 0 1 1 1 1 0 0 0 0 1 1 1 1 √ These patterns differ in the way errors/noise in the data are tolerated [Yang et al 2001]; [Pei et al 2001]; [Seppanen et al 2004]; [Liu et al 2006]; [Cheng et al 2006]; [Gupta et al., KDD 2008]; [Poernomo et al 2009] See Gupta et al KDD 2008 for a survey 16 Error-tolerant pattern vs. Traditional association patterns Four Breast cancer gene-expression data sets are used for experiments: 158 cases + + GSE7390 GSE6532 + GSE3494 GSE1456 433 controls Cases: patients with metastasis within 5 years of follow-up; Controls: patients with no metastasis within 8 years of follow-up Discriminative Error-tolerant and traditional association patterns case/control are discovered and evaluated by enrichment analysis using MSigDB gene sets Greater fraction of errortolerant patterns enrich at least one gene set (higher precision) Greater fraction of gene sets are enriched by at least one error-tolerant pattern (higher recall) Gupta et al. BICoB 2010; Gupta et al. BMC Bioinformatics 2011 Error-tolerant patterns Traditional patterns Error-tolerant patterns Traditional patterns 17 Differential Coexpression Patterns • Differential Expression (DE) – Traditional analysis targets changes of expression level [Silva et al., 1995], [Li, 2002], [Kostka & Spang, 2005], [Rosemary et al., 2008], [Cho et al. 2009] etc. • Differential Coexpression (DC) – Changes of the coherence of gene expression [Eisen et al. 1999] [Golub et al., 1999], [Pan 2002], [Cui and Churchill, 2003] etc. • • Combinatorial Search Genetic Heterogeneity – calls for subspace analysis 18 Subspace Differential Coexpression Analysis Enriched with the TNF-α/NFkB signaling pathway (6/10 overlap with the pathway, corrected p value: 1.4*10-3) ≈ 10% Suggests that the dysregulation of TNF-α/NFkB ≈ 60% pathway may be related to lung cancer Three lung cancer datasets [Bhattacharjee et al. 2001], [Stearman et al. 2005], [Su et al. 2007] [Fang, Kuang, Pandey, Steinbach, Myers and Kumar, PSB 2010] Selected for highlight talk, RECOMB SB 2010 Best Network Model award, Sage Congress, 2010 Combinatorial Biomarkers: Summary • Higher-order combinations • Important for understanding complex human diseases • A novel framework • Improved computational efficiency • Enhanced statistical power • Naturally handles disease heterogeneity • Error-tolerance • Different types of differentiation: coexpression • General to handle different types of data • SNP • Gene expression • Metabolomic data • Brian imaging data (e.g. fMRI) 20 References • G. Fang, R. Kuang, G. Pandey, M. Steinbach, C.L. Myers, and V. Kumar. Subspace differential coexpression analysis: problem definition and a general approach. Pacific Symposium on Biocomputing, 15:145-156, 2010. • G. Fang, G. Pandey, W. Wang, M. Gupta, M. Steinbach, and V. Kumar. Mining low-support discriminative patterns from dense and high-dimensional data. IEEE TKDE, 24(2):279-294, 2012. • G. Fang, Majda Haznadar, Wen Wang, Haoyu Yu, Michael Steinbach, Tim Church, William Oetting, Brian Van Ness, and Vipin Kumar. High-order SNP Combinations Associated with Complex Diseases: Efficient Discovery, Statistical Power and Functional Interactions. PLoS ONE, page in press, 2012. • R. Gupta, N. Rao, and V. Kumar. Discovery of errortolerant biclusters from noisy gene expression data. In BMC Bioinformatics, 12(S12):S1, 2011. • R. Gupta, Smita Agrawal, Navneet Rao, Ze Tian, Rui Kuang, Vipin Kumar, "Integrative Biomarker Discovery for Breast Cancer Metastasis from Gene Expression and Protein Interaction Data Using Error-tolerant Pattern Mining", In Proc. of the International Conference on Bioinformatics and Computational Biology (BICoB), 2010 • Gowtham Atluri, Rohit Gupta, Gang Fang, Gaurav Pandey, Michael Steinbach and Vipin Kumar, Association Analysis Techniques for Bioinformatics Problems, Proceedings of the 1st International Conference on Bioinformatics and Computational Biology (BICoB), pp 1-13, 2009. • S. Landman Vipin Kumar Michael Steinbach, Haoyu Yu. Identification of Co-occurring Insertions in Cancer Genomes Using Association Analysis. International Journal of Data Mining and Bioinformatics, in press, 2012. • M. Steinbach, H. Yu, G. Fang, and V. Kumar. Using constraints to generate and explore higher order discriminative patterns. Advances in Knowledge Discovery and Data Mining, pages 338-350, 2011. • S. Dey, Gowtham Atluri, Michael Steinbach, Angus MacDonald, Kelvin Lim, and Vipin Kumar. A pattern mining based integrative framework for biomarker discovery. Tech report, Department of Computer Science, University of Minnesota, (002), 2012. • G. Pandey, C. Myers, and V. Kumar. Incorporating functional inter-relationships into protein function prediction algorithms. BMC bioinformatics, 10(1):142, 2009. • G. Pandey, B. Zhang, A.N. Chang, C.L. Myers, J. Zhu, V. Kumar, and E.E. Schadt. An integrative multi-network and multi-classifier approach to predict genetic interactions. PLoS computational biology, 6(9):e1000928, 2010 (Cited as one of the major computational biology breakthroughs of 2010 by a Nature Biotechnology feature article). • J. Bellay, G. Atluri, T.L. Sing, K. Toufighi, M. Costanzo, P.S.M. Ribeiro, G. Pandey, J. Baller, B. VanderSluis, M. Michaut, et al. Putting genetic interactions in context through a global modular decomposition. Genome Research, 21(8):1375-1387, 2011. 21 Acknowledgement Kumar Lab, Data Mining Gang Fang Wen Wang Vanja Paunic Yi Yang Benjamin Oatley Xiaoye Liu Sanjoy Dey Gowtham Atluri Gaurav Pandey Michael Steinbach Myers Lab, FuncGenomics Jeremy Bellay Chad Myers Kuang Lab, Compbio TaeHyun Hwang Rui Kuang Masonic Cancer Center Tim Church Bill Oetting Van Ness Lab, Myeloma Brian Van Ness Lim Lab, Brain Imaging Kelvin Lim McDonald Lab, Behavior Angus McDonald Wendt Lab, Lung Disease Chris Wendt Mayo Clinic-IBM-UMR fellowship, Walter Barnes Lang fellowship, NSF: #IIS0916439, UMII seed grant, BICB seed grant, Computations enabled by the Minnesota Supercomputing Institute. BioMedical Genomics Center at University of Minnesota, International Myeloma Foundation. Etiology and Early Marker Study program of the Prostate Lung Colorectal and Ovarian Cancer Screening Trial Thanks! 23