Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
Data Quality Challenges in
Community Systems
AnHai Doan
University of Wisconsin-Madison
Joint work with Pedro DeRose, Warren Shen,
Xiaoyong Chai, Byron Gao, Fei Chen,
Yoonkyong Lee, Raghu Ramakrishnan, Jeff Naughton
Numerous Web Communities
Academic domains
– database researchers, bioinformatists
Infotainments
– movie fans, mountain climbers, fantasy football
Scientific data management
– biomagnetic databank, E. Coli community
Business
– enterprise intranets, tech support groups, lawyers
CIA / homeland security
– Intellipedia
Much Efforts to Build Community Portals
Initially taxonomy based (e.g., Yahoo style)
But now many structured data portals
– capture key entities and relationships of community
No general solution yet on how to build such portals
Cimple Project @ Wisconsin / Yahoo! Research
Develops such a general solution
using extraction + integration + mass collaboration
Maintain and add more sources
Jim Gray
Researcher
Homepages
*
**
*
Pages
* *
Group Pages
mailing list
Keyword search
SQL querying
Web pages
Conference
DBworld
Jim Gray
*
**
**
*
SIGMOD-04
**
*
Text documents
give-talk
SIGMOD-04
Question
answering
Browse
Mining
Alert/Monitor
News summary
DBLP
Mass collaboration
Prototype System: DBLife
Integrate data of the DB research community
1164 data sources
Crawled daily, 11000+ pages = 160+ MB / day
Data Extraction
Data Integration
Raghu Ramakrishnan
co-authors = A. Doan, Divesh Srivastava, ...
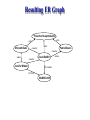
Resulting ER Graph
“Proactive Re-optimization
write
write
Shivnath Babu
coauthor
write
Pedro Bizarro
coauthor
advise
coauthor
Jennifer Widom
David DeWitt
PC-member
PC-Chair
SIGMOD 2005
advise
Provide Services
DBLife system
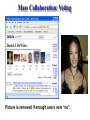
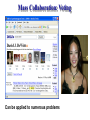
Mass Collaboration: Voting
Picture is removed if enough users vote “no”.
Mass Collaboration via Wiki
Summary: Community Systems
Data integration systems + extraction + Web 2.0
– manage both data and users in a synergistic fashion
In sync with current trends
– manage unstructured data (e.g., text, Web pages)
– get more structure (IE, Semantic Web)
– engage more people (Web 2.0)
– best-effort data integration, data spaces, pay-as-you-go
Numerous potential applications
But raises many difficult data quality challenges
Rest of the Talk
Data quality challenges in
1. Source selection
2. Extraction and integration
3. Detecting problems and providing feedback
4. Mass collaboration
Conclusions & ways forward
1. Source Selection
Maintain and add more sources
Jim Gray
Researcher
Homepages
**
*
*
Pages
* *
Group Pages
mailing list
Keyword search
SQL querying
Web pages
Conference
DBworld
Jim Gray
*
**
**
*
SIGMOD-04
**
*
Text documents
give-talk
SIGMOD-04
Question
answering
Browse
Mining
Alert/Monitor
News summary
DBLP
Mass collaboration
Current Solutions vs. Cimple
Current solutions
– find all relevant data sources
(e.g., using focused crawling, search engines)
– maximize coverage
– have lot of noisy sources
Cimple
– starts with a small set of high-quality “core” sources
– incrementally adds more sources
– only from “high-quality” places
– or as suggested by users (mass collaboration)
Start with a Small Set of “Core” Sources
Key observation: communities often follow 80-20 rules
– 20% of sources cover 80% of interesting activities
Initial portal over these 20% often is already quite useful
How to select these 20%
– select as many sources as possible
– evaluate and select most relevant ones
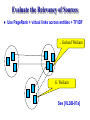
Evaluate the Relevancy of Sources
Use PageRank + virtual links across entities + TF/IDF
... Gerhard Weikum
G. Weikum
See [VLDB-07a]
Add More Sources over Time
Key observation: most important sources will
eventually be mentioned within the community
– so monitor certain “community channels” to find them
Message type: conf. ann.
Subject: Call for Participation: VLDB Workshop on Management of Uncertain Data
Call for Participation
Workshop on
"Management of Uncertain Data"
in conjunction with VLDB 2007
http://mud.cs.utwente.nl
...
Also allow users to suggest new sources
– e.g., the Silicon Valley Database Society
Summary: Source Selection
Sharp contrast to current work
– start with highly relevant sources
– expand carefully
– minimize “garbage in, garbage out”
Need a notion of source relevance
Need a way to compute this
2. Extraction and Integration
Maintain and add more sources
Jim Gray
Researcher
Homepages
**
*
*
Pages
* *
Group Pages
mailing list
Keyword search
SQL querying
Web pages
Conference
DBworld
Jim Gray
*
**
**
*
SIGMOD-04
**
*
Text documents
give-talk
SIGMOD-04
Question
answering
Browse
Mining
Alert/Monitor
News summary
DBLP
Mass collaboration
Extracting Entity Mentions
Key idea: reasonable plan, then patch
Reasonable plan:
– collect person names, e.g., David Smith
– generate variations, e.g., D. Smith, Dr. Smith, etc.
– find occurrences of these variations
ExtractMbyName
Union
s1 … sn
Works well, but can’t handle
certain difficult spots
Handling Difficult Spots
Example
– R. Miller, D. Smith, B. Jones
– if “David Miller” is in the dictionary
will flag “Miller, D.” as a person name
Solution: patch such spots with stricter plans
ExtractMStrict
ExtractMbyName
Union
s1 … sn
FindPotentialNameLists
Matching Entity Mentions
Key idea: reasonable plan, then patch
Reasonable plan
– mention names are the same (modulo some variation)
match
– e.g., David Smith and D. Smith
MatchMbyName
Extract Plan
Union
s1 … sn
Works well, but can’t handle
certain difficult spots
Handling Difficult Spots
MatchMStrict
DBLP: Chen Li
···
41. Chen Li, Bin Wang, Xiaochun Yang.
VGRAM. VLDB 2007.
···
38. Ping-Qi Pan, Jian-Feng Hu, Chen Li.
Feasible region contraction.
Applied Mathematics and Computation.
···
MatchMbyName
Extract Plan
Union
{s1 … sn} \ DBLP
Extract Plan
DBLP
Estimate the semantic ambiguity of data sources
– use social networking techniques [see ICDE-07a]
Apply stricter matchers to more ambiguous sources
Going Beyond Sources:
Difficult Data Spots Can Cover Any
Portion of Data
MatchMStrict2
MatchMStrict
Mentions that
Match “J. Han”
MatchMbyName
Extract Plan
Extract Plan
Union
{s1 … sn} \ DBLP
DBLP
Summary: Extraction and Integration
Most current solutions
– try to find a single good plan, applied to all of data
Cimple solution: reasonable plan, then patch
So the focus shifts to:
– how to find a reasonable plan?
– how to detect problematic data spots?
– how to patch those?
Need a notion of semantic ambiguity
Different from the notion of source relevance
3. Detecting Problems
and Providing Feedback
Maintain and add more sources
Jim Gray
Researcher
Homepages
**
*
*
Pages
* *
Group Pages
mailing list
Keyword search
SQL querying
Web pages
Conference
DBworld
Jim Gray
*
**
**
*
SIGMOD-04
**
*
Text documents
give-talk
SIGMOD-04
Question
answering
Browse
Mining
Alert/Monitor
News summary
DBLP
Mass collaboration
How to Detect Problems?
After extraction and matching, build services
– e.g., superhomepages
Many such homepages contain minor problems
– e.g., X graduated in 19998
X chairs SIGMOD-05 and VLDB-05
X published 5 SIGMOD-03 papers
Intuitively, something is semantically incorrect
To fix this, lets build a Semantic Debugger
– learns what is a normal profile for researcher, paper, etc.
– alerts the builder to potentially buggy superhomepages
– so feedback can be provided
What Types of Feedback?
Say that a certain data item Y is wrong
Provide correct value for Y, e.g., Y = SIGMOD-06
Add domain knowledge
– e.g., no researcher has ever published 5 SIGMOD
papers in a year
Add more data
– e.g., X was advised by Z
– e.g., here is the URL of another data source
Modify the underlying algorithm
– e.g., pull out all data involving X
match using names and co-authors, not just names
How to Make
Providing Feedback Very Easy?
“Providing feedback” for the masses
– in sync with current trends of empowering the masses
Extremely crucial in DBLife context
If feedback can be provided easily
– can get more feedback
– can leverage the mass of users
But this turned out to be very difficult
How to Make
Providing Feedback Very Easy?
Say that a certain data item Y is wrong
Provide correct value for Y, e.g., Y = SIGMOD-06
Add domain knowledge
Add more data
Provide form
interfaces
Modify the underlying algorithm
Provide a Wiki
interface
Critical in our
experience, but
unsolved
Unsolved, some
recent interest on
how to mass
customize software
See our IEEE Data Engineering Bulletin paper
on user-centric challenges, 2007
What Feedback
Would Make the Most Impact?
I have one hour spare time, would like to “teach” DBLife
– what problems should I work on?
– what feedback should I provide?
Need a Feedback Advisor
– define a notion of system quality Q(s)
– define questions q1, ..., qn that DBLife can ask users
– for each qi, evaluate its expected improvement in Q(s)
– pick question with highest expected quality improvement
Observations
– a precise notion of system quality is now crucial
– this notion should model the expected usage
Summary: Detection and Feedback
How to detect problems?
– Semantic Debugger
What types of feedback &
how to easily provide them?
– critical, largely unsolved
What feedback would make most impact?
– crucial in large-scale systems
– need a Feedback Advisor
– need a precise notion of system quality
4. Mass Collaboration
Maintenance and expansion
Jim Gray
Researcher
Homepages
**
*
*
Pages
* *
Group Pages
mailing list
Keyword search
SQL querying
Web pages
Conference
DBworld
Jim Gray
*
**
**
*
SIGMOD-04
**
*
Text documents
give-talk
SIGMOD-04
Question
answering
Browse
Mining
Alert/Monitor
News summary
DBLP
Mass collaboration
Mass Collaboration: Voting
Can be applied to numerous problems
Example: Matching
Dell laptop X200 with mouse ...
Mouse for Dell laptop 200 series ...
Dell X200; mouse at reduced price ...
Hard for machine, but easy for human
Challenges
How to detect and remove noisy users?
– evaluate them using questions with known answers
How to combine user feedback?
– # of yes votes vs. # of no votes
See [ICDE-05a, ICDE-08a]
Mass Collaboration: Wiki
Data
Sources
M
G
T
V1
W1
V2
W2
V3
W3
V3’
W3’
T3 ’
Community wikipedia
– built by machine + human
– backed up by a structured database
u1
Mass Collaboration: Wiki
Machine
<# person(id=1){name}=David J. DeWitt #>
Professor
<# person(id=1){title}=Professor #>
<strong>Interests:</strong>
<# person(id=1).interests(id=3)
.topic(id=4){name}=Parallel Database #>
Human
Human
<# person(id=1){name}=David J. DeWitt #>
<# person(id=1){title}=John P. Morgridge
Professor #>
<# person(id=1) {organization}=UW #>
since 1976
<strong>Interests:</strong>
<# person(id=1).interests(id=3)
.topic(id=4){name}=Parallel Database #>
David J. DeWitt
Interests:
Parallel Database
Machine
Machine
<# person(id=1){name}=David J. DeWitt #>
<# person(id=1){title}= John P. Morgridge
Professor #>
<# person(id=1){organization}=UW-Madison#>
since 1976
<strong>Interests:</strong>
<# person(id=1).interests(id=3)
.topic(id=4){name}=Parallel Database #>
<# person(id=1).interests(id=5)
.topic(id=6){name}=Privacy #>
David J. DeWitt
John P. Morgridge Professor
UW-Madison since 1976
Interests:
Parallel Database
Privacy
Sample Data Quality Challenges
How to detect noisy users?
– no clear solution yet
– for now, limit editing to trusted editors
– modify notion of system quality to account for this
How to combine feedback, handle inconsistent data?
– user vs. user
– user vs. machine
How to verify claimed ownership of data portions?
– e.g., this superhomepage is about me
– only I can edit it
See [ICDE-08b]
Summary: Mass Collaboration
What can users contribute?
How to evaluate user quality?
How to reconcile inconsistent data?
Additional Challenges
Dealing with evolving data (e.g., matching)
Iterative code development
Lifelong quality improvement
Querying over inconsistent data
Managing provenance and uncertainty
Generating explanations
Undo
Conclusions
Community systems:
– data integration + IE + Web 2.0
– potentially very useful in numerous domains
Such systems raise myriad data quality challenges
– subsume many current challenges
– suggest new ones
Can provide a unifying context for us to make progress
– building systems has been a key strength of our field
– we need a community effort, as always
See “cimple wisc” for more detail
Let us know if you want code/data