Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
HIDDEN CONCEPT DETECTION IN GRAPHBASED RANKING ALGORITHM FOR
PERSONALIZED RECOMMENDATION
Nan Li
Computer Science Department
Carnegie Mellon University
INTRODUCTION
Previous work:
Represents past user behavior through a
relational graph.
Fail to represent individual differences among
items of a same type.
Our work:
Detect hidden concepts embedded in the
original graph
Build a two-level type hierarchy for explicit
representation of item characteristics.
RELATIONAL RETRIEVAL
1.
2.
Entity-Relation Graph G=(E, T, R):
•
Entity set E={e} Entity types set T={T} Entity
relations R={R}
•
Each entity e in E has its type e.T .
•
Each relation R has two entity types R.T1 and
R.T2. If two entities has relation R, then R(e1,
e2) = 1, o/w 0.
Relational Retrieval Task: Query q = (Eq , Tq)
•
Given Eq = {e’}, predict the relevance of
each entity e of the target type Tq.
PATH RANKING ALGORITHM
Relational Path:
P = (R1, R2, …, Rn) R1.T1=T0 and
Ri.T2=Ri+1.T1.
2. Relational Path Probability Distribution:
The probability corresponds to the
probability of a path random walker reaching
that entity from a query entity.
1.
PRA MODEL
(G, l, θ)
•
The feature matrix A has its each column to be
the distribution hp(e).
•
The scoring function:
TRAINING PRA MODEL
1.
2.
3.
Training data: D = {(q(m),y(m))}, ye(m)=1 if e is
relevant to the query q(m)
Parameter: The weight of path θ
Objective function:
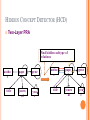
HIDDEN CONCEPT DETECTOR (HCD)
Two-Layer PRA
Find hidden subtype of
relations
autho
r
title
pape
r
gene
journ
al
yea
r
autho
r
title
pape
r
gene
journ
al
yea
r
BOTTOM-UP HCD
Bottom-Up merging algorithm:
For each relation type Ri
Step1: Divide every starting node of relation Ri as a
subrelation Rij.
author
paper
author
paper
Step2: HAC: Each time merge two subrelations Rim
and Rin to maximize the gain of objective functions until
no positive gain:
author
paper
author
paper
APPROXIMATE THE GAIN OF OBJECTIVE
FUNCTION
1.
Calculate the maximum gain of two relations: gm
and gn
2.
Use taylor series to approximate:
EXPERIMENTAL RESULTS
1.
Data Sets:
Saccharomyces Genome Database, a publication data set
about the yeast organism Saccharomyces cerevisiae
Three measurements:
2.
Mean Reciprocal Rank (MRR): inverse of the rank of the
first correct answer
Mean Average Precision (MAP): the area under the
Precision-Recall curve
p@K: precision at K, where K is the actually number of
relevant entities.
NORMALIZED CUT
Training data:
Number of clusters ↑
Recommendation quality↑
Test data:
NCut outperforms random
HCD
•
Training data:
•
•
HCD outperforms PRA
in all three
measurements
Test data:
•
Two systems perform
equally well
FUTURE WORK
Bottom-Up vs Top Down
Improve Efficiency
Type Recovery in Non-Labeled Graph
Building an intelligent agent
that simulates human-level
learning using machine
learning techniques
A COMPUTATIONAL MODEL OF
ACCELERATED FUTURE
LEARNING THROUGH FEATURE
RECOGNITION
Nan Li
Computer Science Department
Carnegie Mellon University
ACCELERATED FUTURE LEARNING
Accelerated Future Learning
Learning more effectively because of prior learning
Has been observed a lot
How?
Expert vs Novice
Expert Deep functional feature (e.g. -3x -3)
Novice Shallow perceptual feature (e.g. -3x 3)
A COMPUTATIONAL MODEL
Model Accelerated Future Learning
Use Machine Learning Techniques
Acquire Deep Feature
Integrated into a Machine-Learning Agent
AN EXAMPLE IN ALGEBRA
FEATURE RECOGNITION AS
PCFG INDUCTION
Under lying structure in the problem
Grammar
Feature Intermediate symbol in a grammar
rule
Feature learning task Grammar induction
Error Incorrect parsing
PROBLEM STATEMENT
Input is a set of feature recognition records
consisting of
An original problem (e.g. -3x)
The feature to be recognized (e.g. -3 in -3x)
Output
A PCFG
An intermediate symbol in a grammar rule
ACCELERATED FUTURE LEARNING
THROUGH FEATURE RECOGNITION
Extended a PCFG Learning Algorithm (Li et al.,
2009)
Feature Learning
Stronger Prior Knowledge:
Transfer Learning Using Prior Knowledge
Better Learning Strategy:
Effective Learning Using Bracketing Constraint
A TWO-STEP ALGORITHM
•
Greedy Structure
Hypothesizer:
•
Hypothesizes the schema
structure
Viterbi Training Phase:
Refines schema
probabilities
Removes redundant
schemas
Generalizes Inside-Outside Algorithm (Lary & Young,
1990)
GREEDY STRUCTURE HYPOTHESIZER
Structure learning
Bottom-up
Prefer recursive to non-recursive
EM PHASE
Step One:
Plan parse tree
computation
Most probable parse
tree
Step Two:
Selection probabilities
update
s: ai p, aj ak
FEATURE LEARNING
Build Most Probable
Parse Trees
For all observation
sequences
Select an
Intermediate Symbol
that
Matches the most
training records as the
target feature
TRANSFER LEARNING USING PRIOR
KNOWLEDGE
GSH Phase:
Build parse trees
based on previously
acquired grammar
Then call the original
GSH
Viterbi Training:
Add rule frequency in
previous task to the
current task
0.5
0.3
0.5
0.6
3
6
EFFECTIVE LEARNING USING
BRACKETING CONSTRAINT
Force to generate a
feature symbol
Learn a subgrammar
for feature
Learn a grammar for
whole trace
Combine two
grammars
EXPERIMENT DESIGN IN ALGEBRA
EXPERIMENT RESULT IN ALGEBRA
Fig.2. Curriculum one
Fig.3. Curriculum two
Fig.4. Curriculum three
Both stronger prior knowledge and a better learning strategy can yield
accelerated future learning
Strong prior knowledge produces faster learning outcomes
L00 generated human-like errors
LEARNING SPEED IN
SYNTHETIC DOMAINS
Both stronger prior knowledge and a better learning strategy yield faster
learning
Strong prior knowledge produces faster learning outcomes with small amount
of training data, but not with large amount of data
Learning with subtask transfer shows larger difference, 1) training process; 2)
SCORE WITH INCREASING DOMAIN SIZES
The base learner, L00, shows the fastest drop
Average time spent per training record
Less than 1 millisecond except for L10 (266 milliseconds)
L10: Need to maintain previous knowledge, does not separate trace into
small traces
INTEGRATING ACCELERATED FUTURE
LEARNING IN SIMSTUDENT
•
Prepare Lucky for Quiz Level 3 !
A machine-learning
agent that
•
Curriculum Browser
x+5
Level 1:
[+] One-Step Linear Equation
•
Level 2:
[+] Two-Step Linear Equation
Level 3:
[-] Equation with Similar Terms
Overview
In this unit, you will solve
equations with integer or decimal
coefficients, as well as equations
involving more than one variable.
More…
•
Integrate the acquired
grammar into
production rules
Lucky
Tutor Lucky
Next Problem
Quiz Lucky
Acquires production
rules from
Examples and
problem solving
experience
Requires weak
operators (non-domain
specific knowledge)
Less number of
operators
CONCLUDING REMARKS
Presented a computational model of human
learning that yields accelerated future learning.
Showed
Both stronger prior knowledge and a better learning
strategy improve learning efficiency.
Stronger prior knowledge produced faster learning
outcomes than a better learning strategy.
Some model generated human-like errors, while
others did no make any mistake.