Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
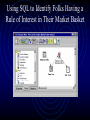
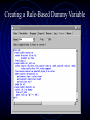
The Marriage of Market Basket Analysis to Predictive Modeling Sanford Gayle How Would You Mine This Transactional Data? Is Data Mining Simply Market Basket Analysis? Market Basket Analysis identifies the rule /our_company/bboard/hr/café/ … but • How do you use this information? • Can the information be used to develop a predictive model? • More generally, how do you develop predictive models using transactional tables? Data Mining Software Objectives • • • • Predictive Modeling Clustering Market Basket Analysis Feature Discovery; that is, improve the predictive accuracy of existing models Agenda • Converting a transactional to a modeling table • The curse of dimensionality & possible fixes • A feature discovery process; using market basket analysis output as an input to predictive modeling • A dimensional reduction scheme using confidence DM Table Structures • Transactional tables (Market Basket Analysis) Trans-id page spend count id-1 id-1 id-1 id-1 id-1 id-2 • page1 page2 page3 page4 page5 page1 $0 $0 $0 $19.99 $0 $0 1 1 1 1 1 1 Modeling tables (modeling & clustering tools) Trans-id page spend count id-1 id-2 . . $19.95 $0 5 1 Converting Transactional Into Modeling Data • Continuous variable case - easy • Collapse the spend or count columns via the sum, mean, or frequency statistic for each transaction-id value • Proc sql; create table new as select id,sum(amount) as total from old group by id; • Categorical variable case - challenging • It seems the detail page information is lost when the rows are rolled-up or collapsed • However, with transposition you collapse the rows onto a single row for each id, with each distinct page now being a column in the modeling table and taking the count or sum statistic as its value The Input Discovery Process • Existing modeling table contains: id-1, age, income, job-category, married, recency, frequency, zip-code … • New potential predictors per transpose contains: id-1, spend on page1, spend on page2, spend on page3, spend on page4, spend on page5 • Augment existing modeling table with the new inputs and, hopefully, discover new, significant predictors to improve predictive accuracy Problem with Transpose Method • • • Suppose the server has 1,000 distinct pages; the transpose method now produces 1,000 new columns instead of 5 Sparsity: new columns have a preponderance of missing values; e.g., id-2 will have 5 missing values and the 1 non-missing Regression, Neural, and Cluster tools struggle with this many variables, especially when there is such a preponderance of the same values (e.g., zeros or missing) The Curse of Dimensionality • • • Suppose interest lies in a second classification column too; e.g., both time (hour) and page visited Transpose method now produces 1,000+24 new variables, assuming no interest in interactions If interactions are of interest, then there will be 24,000 (1,000x24) new variable generated General Fix • Reduce the number of levels of the categorical variable (e.g., using confidence) • Use the transpose method to convert the transactional to a modeling table • Add the new inputs to the traditional modeling table in an effort to improve predictive accuracy Creating Rules-Based Dummy Variables • • • • • • Obtain rules using market basket analysis Choose the rule of interest Identify folks having the rule of interest in their market basket Create a dummy variable flagging them Augment the traditional modeling table with the dummy variable Use the dummy variable as an input or target in a predictive modeling tool Using SQL to Identify Folks Having a Rule of Interest in Their Market Basket Creating a Rule-Based Dummy Variable The All-Info Table Feature Discovery: A new potential predictor or input Possible Sub-setting Criteria • • • • Any rule of interest The confidence - e.g., all rules having confidence >= 100 (optimal level of confidence?) The support - e.g., all rules having support >= 10 (optimal level of support?) The lift - e.g., all rules having lift >= 5 (optimal level of lift) Using Confidence as the Basis for a Reclassification Scheme • • • Suppose diapersbeer has a confidence of 100% Then the two levels “diapers” & “beer” can be mapped into the value “diapersbeer”, it seems Actually, both the rule and its reverse must have a confidence of 100% The Confidence Reclassification Scheme • • • If confidence for the rule and its opposite is >80, then combine the two levels into the rulebased level e.g., “page1” & “page2” both mapped into “page1page2” Using 80 instead of 100 will introduce inaccuracy, but the analyst overwhelmed with too many levels will likely be willing to substitute a little accuracy for dimensional reduction The Confidence Reclassification Scheme • • • Use the transpose method to generate candidate predictors Augment the traditional modeling table with the new candidate predictors table Develop an enhanced model using some of the candidate predictors in the hope of fostering predictive accuracy Contact Information [email protected]