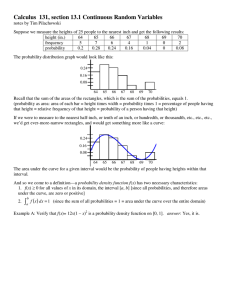
Calculus 131, section 13.1 Continuous Random Variables
... The area under the curve for a given interval would be the probability of people having heights within that ...
... The area under the curve for a given interval would be the probability of people having heights within that ...

Chapter 7 Lesson 8 - Mrs.Lemons Geometry
... Chapter 7 Lesson 8 Objective: To use segment and area models to find the probabilities of events. ...
... Chapter 7 Lesson 8 Objective: To use segment and area models to find the probabilities of events. ...

Consider Exercise 3.52 We define two events as follows: H = the
... We now calculate the following conditional probabilities. The probability of F given H, denoted by P(F | H), is _____ . We could use the conditional probability formula on page 138 of our text. Note that P(F | ࡴ ) = ______ Comparing P(F), P(F | H) and P(F | ࡴ ) we note that the occurrence or nonoc ...
... We now calculate the following conditional probabilities. The probability of F given H, denoted by P(F | H), is _____ . We could use the conditional probability formula on page 138 of our text. Note that P(F | ࡴ ) = ______ Comparing P(F), P(F | H) and P(F | ࡴ ) we note that the occurrence or nonoc ...

Bayesian Networks and Hidden Markov Models
... A simplified Bayes Theorem simply tells us that in the absence of other evidence, the likelihood of an event is equal to its past likelihood. It assumes that the consequences of an incorrect classification are always the same (unlike, for example, a state such as “infected with HIV vs. uninfected wi ...
... A simplified Bayes Theorem simply tells us that in the absence of other evidence, the likelihood of an event is equal to its past likelihood. It assumes that the consequences of an incorrect classification are always the same (unlike, for example, a state such as “infected with HIV vs. uninfected wi ...

ML_Lecture_6
... prior probabilities of the various hypotheses in H. Prior probability of h, P(h): it reflects any background knowledge we have about the chance that h is a correct hypothesis (before having observed the data). Prior probability of D, P(D): it reflects the probability that training data D will be ...
... prior probabilities of the various hypotheses in H. Prior probability of h, P(h): it reflects any background knowledge we have about the chance that h is a correct hypothesis (before having observed the data). Prior probability of D, P(D): it reflects the probability that training data D will be ...

ML_Lecture_6
... prior probabilities of the various hypotheses in H. Prior probability of h, P(h): it reflects any background knowledge we have about the chance that h is a correct hypothesis (before having observed the data). Prior probability of D, P(D): it reflects the probability that training data D will be ...
... prior probabilities of the various hypotheses in H. Prior probability of h, P(h): it reflects any background knowledge we have about the chance that h is a correct hypothesis (before having observed the data). Prior probability of D, P(D): it reflects the probability that training data D will be ...

L70
... dropped back in the bag. Both marbles were red. If another marble is drawn, what is the probability that it will be red? ...
... dropped back in the bag. Both marbles were red. If another marble is drawn, what is the probability that it will be red? ...

Certain, impossible, event, mutually exclusive, conditional, bias
... exclusive probabilities add up to 1. ...
... exclusive probabilities add up to 1. ...

Syllabus - UMass Math
... Description: The subject matter of probability theory is the mathematical analysis of random events, which are empirical phenomena having some statistical regularity but not deterministic regularity. The theory combines aesthetic beauty, deep results, and the ability to model and to predict the beha ...
... Description: The subject matter of probability theory is the mathematical analysis of random events, which are empirical phenomena having some statistical regularity but not deterministic regularity. The theory combines aesthetic beauty, deep results, and the ability to model and to predict the beha ...

I I I I I I I I I I I I I I I I I I I
... the posterior probability to the prior, and noting that the higher the prior, the smaller this ratio and so the less confirmatory the evidence is of the hypothesis. In particular, if P (H) is higher than P(HJE), then even if P(HJE) is high, E will be evidence against H and so the effect of combining ...
... the posterior probability to the prior, and noting that the higher the prior, the smaller this ratio and so the less confirmatory the evidence is of the hypothesis. In particular, if P (H) is higher than P(HJE), then even if P(HJE) is high, E will be evidence against H and so the effect of combining ...

Inf2D-Reasoning and Agents Spring 2017
... relative importance of various goals and the likelihood that (and degree to which) they will be achieved ...
... relative importance of various goals and the likelihood that (and degree to which) they will be achieved ...


General Probability, I: Rules of probability
... consistent with this rule (assuming areas are normalized so that the entire sample space S has area 1), and you can derive each of these rules simply by calculating areas in Venn diagrams. Moreover, the area trick makes it very easy to find probabilities in other, more complicated, situations. for e ...
... consistent with this rule (assuming areas are normalized so that the entire sample space S has area 1), and you can derive each of these rules simply by calculating areas in Venn diagrams. Moreover, the area trick makes it very easy to find probabilities in other, more complicated, situations. for e ...

coppin chapter 12e
... we can eliminate it, and simply aim to find the classification ci, for which the following is maximised: ...
... we can eliminate it, and simply aim to find the classification ci, for which the following is maximised: ...

coppin chapter 12
... Since P(E) is independent of Hi it will have the same value for each hypothesis. Hence, it can be ignored, and we can find the hypothesis with the highest value of: We can simplify this further if all the hypotheses are equally likely, in which case we simply seek the hypothesis with the highest val ...
... Since P(E) is independent of Hi it will have the same value for each hypothesis. Hence, it can be ignored, and we can find the hypothesis with the highest value of: We can simplify this further if all the hypotheses are equally likely, in which case we simply seek the hypothesis with the highest val ...

Belief-Function Formalism
... • It is a generalization of the traditional probability density function. • For example… ...
... • It is a generalization of the traditional probability density function. • For example… ...
Dempster–Shafer theory

The theory of belief functions, also referred to as evidence theory or Dempster–Shafer theory (DST), is a general framework for reasoning with uncertainty, with understood connections to other frameworks such as probability, possibility and imprecise probability theories. First introduced by Arthur P. Dempster in the context of statistical inference, the theory was later developed by Glenn Shafer into a general framework for modeling epistemic uncertainty - a mathematical theory of evidence. The theory allows one to combine evidence from different sources and arrive at a degree of belief (represented by a mathematical object called belief function) that takes into account all the available evidence.In a narrow sense, the term Dempster–Shafer theory refers to the original conception of the theory by Dempster and Shafer. However, it is more common to use the term in the wider sense of the same general approach, as adapted to specific kinds of situations. In particular, many authors have proposed different rules for combining evidence, often with a view to handling conflicts in evidence better. The early contributions have also been the starting points of many important developments, including the Transferable Belief Model and the Theory of Hints.