
HEALTH ECONOMETRICS: Dealing with the selection problem and
... use of bootstrap methods to deal with cases where the asymptotic theory is intractable or where the asymptotics are known but finite sample properties of an estimator are unknown (see e.g., Jeong and Maddala, 1993). The aim of these methods is to reduce bias and to provide more reliable confidence i ...
... use of bootstrap methods to deal with cases where the asymptotic theory is intractable or where the asymptotics are known but finite sample properties of an estimator are unknown (see e.g., Jeong and Maddala, 1993). The aim of these methods is to reduce bias and to provide more reliable confidence i ...

CHAPTER 3 CLASSICAL LINEAR REGRESSION MODELS
... All model criteria are structured in terms of the estimated residual variance ^ 2 plus a penalty adjustment involving the number of estimated parameters, and it is in the extent of this penalty that the criteria di¤er from. For more discussion about these, and other selection criteria, see Judge et ...
... All model criteria are structured in terms of the estimated residual variance ^ 2 plus a penalty adjustment involving the number of estimated parameters, and it is in the extent of this penalty that the criteria di¤er from. For more discussion about these, and other selection criteria, see Judge et ...


Heteroskedasticity and Correlations Across Errors
... test statistic has a Chi-square(k*) distribution asymptotically, where k* is the number of slope coefficients in equation 2. Critical values of the Chi-square distribution are in the text (table B-8). if the test statistic exceeds the critical value, reject the null. In Eviews, you first run the reg ...
... test statistic has a Chi-square(k*) distribution asymptotically, where k* is the number of slope coefficients in equation 2. Critical values of the Chi-square distribution are in the text (table B-8). if the test statistic exceeds the critical value, reject the null. In Eviews, you first run the reg ...

Stat 112: Notes 2
... Before making any inferences using the simple linear regression model, we need to check the assumptions: Based on the data ( X 1 , Y1 ), , ( X n,Yn ) , 1. We estimate 0 and 1 by the least squares estimates b0 and b1 . 2. We estimate the disturbances ei by the residuals eˆi Yi Eˆ (Y | X i ) ...
... Before making any inferences using the simple linear regression model, we need to check the assumptions: Based on the data ( X 1 , Y1 ), , ( X n,Yn ) , 1. We estimate 0 and 1 by the least squares estimates b0 and b1 . 2. We estimate the disturbances ei by the residuals eˆi Yi Eˆ (Y | X i ) ...

Johnson, N.L.; (1972)A method of separation of residual and interaction effects in cross-classification."
... Variability about this expected value is represented by addition of a random variable with zero expected value. ...
... Variability about this expected value is represented by addition of a random variable with zero expected value. ...

ENGG
... #heads = ½ #tosses + chance error where chance error becomes large in absolute terms but small as % of #tosses as #tosses increases. • The Law of Averages states that an average result for n independent trials converges to a limit as n increases. • The law of averages does not work by compensation. ...
... #heads = ½ #tosses + chance error where chance error becomes large in absolute terms but small as % of #tosses as #tosses increases. • The Law of Averages states that an average result for n independent trials converges to a limit as n increases. • The law of averages does not work by compensation. ...

Test Code : QR ( Short answer type ) 2005
... variables and their moments. Bivariate distributions (with special emphasis on bivariate normal), marginal and conditional distributions, correlation and regression. Multivariate distributions, marginal and conditional distributions, regression, independence, partial and multiple correlations. Order ...
... variables and their moments. Bivariate distributions (with special emphasis on bivariate normal), marginal and conditional distributions, correlation and regression. Multivariate distributions, marginal and conditional distributions, regression, independence, partial and multiple correlations. Order ...

Robust nonparametric statistical methods.
... Algina, J., Keselman, H., & Penfield, R. (2005b). Effect sizes and their intervals: The two-level repeated measures case. Educational and Psychological Measurement, 65, 241–258. Algina, J., Keselman, H. J., & Penfield, R. D. (2006a). Confidence interval coverage for Cohen’s effect size statistic. Ed ...
... Algina, J., Keselman, H., & Penfield, R. (2005b). Effect sizes and their intervals: The two-level repeated measures case. Educational and Psychological Measurement, 65, 241–258. Algina, J., Keselman, H. J., & Penfield, R. D. (2006a). Confidence interval coverage for Cohen’s effect size statistic. Ed ...

Quality of service parameters and link operating point estimation
... s and t∗ are called the operating point of the link. Therefore, a good estimation of s∗ and t∗ is useful for the network’s design, for the Connection Acceptance Control (CAC) function, or for optimal operation. The technical relevance of the issue is pointed out in section 2, where we briefly presen ...
... s and t∗ are called the operating point of the link. Therefore, a good estimation of s∗ and t∗ is useful for the network’s design, for the Connection Acceptance Control (CAC) function, or for optimal operation. The technical relevance of the issue is pointed out in section 2, where we briefly presen ...

Presentation 2
... Definitions: Measures of Dispersion • Variance: indicates the distance of each score from the mean but in order to account for both + and – differences from the mean (so they don’t just cancel each other out) we square the difference and add them together (Sum of Squares). This indicates the total ...
... Definitions: Measures of Dispersion • Variance: indicates the distance of each score from the mean but in order to account for both + and – differences from the mean (so they don’t just cancel each other out) we square the difference and add them together (Sum of Squares). This indicates the total ...

Homework 3
... 1. When asked the model used in simple linear regression, a student responds: EYi 0 1 Xi i . What was the student's mistake? The student has confused the mean value of Yi (which lies on the line Y 0 1 X ) with the value of one particular Yi , which includes a term for random error. ...
... 1. When asked the model used in simple linear regression, a student responds: EYi 0 1 Xi i . What was the student's mistake? The student has confused the mean value of Yi (which lies on the line Y 0 1 X ) with the value of one particular Yi , which includes a term for random error. ...

Proceedings of the 2013 Winter Simulation Conference
... Llorente and Su´arez the data are heavy-tailed (Crovella and Lipsky 1997). The empirical estimates become more unstable for larger values of p (Angeletti, Bertin, and Abry 2012). These observations directly apply to the estimation of the L p -norm of the residuals in regression. When these estimate ...
... Llorente and Su´arez the data are heavy-tailed (Crovella and Lipsky 1997). The empirical estimates become more unstable for larger values of p (Angeletti, Bertin, and Abry 2012). These observations directly apply to the estimation of the L p -norm of the residuals in regression. When these estimate ...

P. STATISTICS LESSON 14 – 1 ( DAY 1 )
... y to remind ourselves that the regression line gives predictions of IQ. The slope b and intercept a of the leastsquares line of are statistics. That is we calculate them from the sample data. To do formal inference, we think of a and b as estimates of unknown parameters. ...
... y to remind ourselves that the regression line gives predictions of IQ. The slope b and intercept a of the leastsquares line of are statistics. That is we calculate them from the sample data. To do formal inference, we think of a and b as estimates of unknown parameters. ...
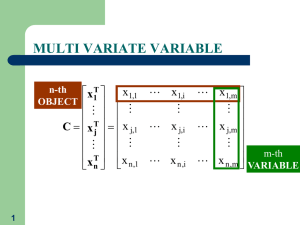
CorrelationRegression
... It is dimensionless measure of correlation; 0 – 1 for positive correlation, 0 – (-1) for negative correlation; 0 means that there is no linear relationship between variables (can be nonlinear!) or this relationship is not statistically significant on the basis of available data; 1 or (-1) indicates ...
... It is dimensionless measure of correlation; 0 – 1 for positive correlation, 0 – (-1) for negative correlation; 0 means that there is no linear relationship between variables (can be nonlinear!) or this relationship is not statistically significant on the basis of available data; 1 or (-1) indicates ...

Spring 2014 - uf statistics
... Can you make money from the lotto? We have data on 254 consecutive daily “pick it” lottery run by the state of New Jersey. In the game, each player selects a three digit number between 000 and 999. A winning number is selected by randomly picking one of 10 balls (numbered 0-9) from each of three con ...
... Can you make money from the lotto? We have data on 254 consecutive daily “pick it” lottery run by the state of New Jersey. In the game, each player selects a three digit number between 000 and 999. A winning number is selected by randomly picking one of 10 balls (numbered 0-9) from each of three con ...

cern_stat_4
... Suppose we have a sample of observed values: We want to find some function of the data to estimate the parameter(s): ← estimator written with a hat Sometimes we say ‘estimator’ for the function of x1, ..., xn; ‘estimate’ for the value of the estimator with a particular data set. G. Cowan ...
... Suppose we have a sample of observed values: We want to find some function of the data to estimate the parameter(s): ← estimator written with a hat Sometimes we say ‘estimator’ for the function of x1, ..., xn; ‘estimate’ for the value of the estimator with a particular data set. G. Cowan ...

Assessing the Uncertainty of Point Estimates We notice that, in
... can be reduced by increasing the number of observations and, in principle, can be made as small as desired by choosing an appropriate sample size. Statisticians have been very effective in explaining sampling variability to the scientific ...
... can be reduced by increasing the number of observations and, in principle, can be made as small as desired by choosing an appropriate sample size. Statisticians have been very effective in explaining sampling variability to the scientific ...

1 The sample size needed to estimate a population mean within 2
... 19 In the past a university has determined that 50% of students receive some sort of financial aid. Assume the proportion of all students receiving financial aid has not changed. In a random sample of size 100, what is the chance of finding at least 55 that receive some sort of financial aid? a. 0. ...
... 19 In the past a university has determined that 50% of students receive some sort of financial aid. Assume the proportion of all students receiving financial aid has not changed. In a random sample of size 100, what is the chance of finding at least 55 that receive some sort of financial aid? a. 0. ...

Temporal Process Regression
... (2001). A third is Lin (2000) proportional means model for medical costs data. The focus of this paper is different from these earlier works, in that the coefficients are completely unspecified. Nonparametric inference for time-dependent coefficients has been well studied in proportional hazards re ...
... (2001). A third is Lin (2000) proportional means model for medical costs data. The focus of this paper is different from these earlier works, in that the coefficients are completely unspecified. Nonparametric inference for time-dependent coefficients has been well studied in proportional hazards re ...

Self-Entry-Level Test
... (d) Recall that the mean of Ȳ is µY and its variance is σȲ2 = σY2 /n. According to the central limit theorem, when n is large, the distribution of Ȳ is approximately N (µY , σȲ2 ). The distribution of Ȳ is exactly N (µY , σȲ2 ) when the sample is drawn from a population with the normal distrib ...
... (d) Recall that the mean of Ȳ is µY and its variance is σȲ2 = σY2 /n. According to the central limit theorem, when n is large, the distribution of Ȳ is approximately N (µY , σȲ2 ). The distribution of Ȳ is exactly N (µY , σȲ2 ) when the sample is drawn from a population with the normal distrib ...

ANOVA Computations
... sampled from the same population, because they all have the same mean and the same variance ( σ 2 / n ). That is, over repeated samples, the sample means should show a variability that is solely due to the sampling variability of the mean if the null hypothesis is true. This in turn implies that the ...
... sampled from the same population, because they all have the same mean and the same variance ( σ 2 / n ). That is, over repeated samples, the sample means should show a variability that is solely due to the sampling variability of the mean if the null hypothesis is true. This in turn implies that the ...

Basic Estimation Techniques
... truly related to X (i.e., b 0) • Even if b = 0, it is possible that the sample will produce an estimate b̂ that is different from zero • Test for statistical significance using t-tests or p-values ...
... truly related to X (i.e., b 0) • Even if b = 0, it is possible that the sample will produce an estimate b̂ that is different from zero • Test for statistical significance using t-tests or p-values ...

full text as PDF file
... property for a variety of estimators (e.g., Bunea (2004), Bunea and McKeague (2005), Fan and Li (2002, 2004), Zou (2006), Li and Liang (2007), Wang and Leng (2007), Wang, G. Li, and Tsai (2007), Wang, R. Li, and Tsai (2007), Zhang and Lu (2007), Zou and Yuan (2008)). The sparsity property and the cl ...
... property for a variety of estimators (e.g., Bunea (2004), Bunea and McKeague (2005), Fan and Li (2002, 2004), Zou (2006), Li and Liang (2007), Wang and Leng (2007), Wang, G. Li, and Tsai (2007), Wang, R. Li, and Tsai (2007), Zhang and Lu (2007), Zou and Yuan (2008)). The sparsity property and the cl ...

Stochastic Process
... The difference is that in WLLN/SLLN, sample means converge to a deterministic value rather than a random variable as in CLT. Since CLT also requires finite variance, CLT gives a stronger result than WLLN/SLLN. That is, WLLN/SLLN only tell that sample means converge to a deterministic value but WLLN/ ...
... The difference is that in WLLN/SLLN, sample means converge to a deterministic value rather than a random variable as in CLT. Since CLT also requires finite variance, CLT gives a stronger result than WLLN/SLLN. That is, WLLN/SLLN only tell that sample means converge to a deterministic value but WLLN/ ...