

Lecture 2
... The Lorenz attractor is generated by the system of 3 differential equations dx/dt= -10x ...
... The Lorenz attractor is generated by the system of 3 differential equations dx/dt= -10x ...

Ch. 11: Machine Learning: Connectionist
... what the unit decided to do, given all the inputs and its threshold ...
... what the unit decided to do, given all the inputs and its threshold ...

Ling 8700: Lecture Notes 1 A Model of Neural Activation
... • the model is defined in terms of a ‘context’ vector of neural units, as shown above; • activation of the context vector defines a mental state, as noted above; • the context vector is connected to sensory units (observations); • the context vector is also connected to itself at previous time step, ...
... • the model is defined in terms of a ‘context’ vector of neural units, as shown above; • activation of the context vector defines a mental state, as noted above; • the context vector is connected to sensory units (observations); • the context vector is also connected to itself at previous time step, ...

neuralnet: Training of neural networks
... shows that neural networks are direct extensions of GLMs. However, the parameters, i.e. the weights, cannot be interpreted in the same way anymore. Formally stated, all hidden neurons and output neurons calculate an output f ( g(z0 , z1 , . . . , zk )) = f ( g(z)) from the outputs of all preceding n ...
... shows that neural networks are direct extensions of GLMs. However, the parameters, i.e. the weights, cannot be interpreted in the same way anymore. Formally stated, all hidden neurons and output neurons calculate an output f ( g(z0 , z1 , . . . , zk )) = f ( g(z)) from the outputs of all preceding n ...

Lecture 6 - School of Computing | University of Leeds
... Some common variations on this learning rule: Adding a learning rate 0
... Some common variations on this learning rule: Adding a learning rate 0


Bayesian Curve Fitting and Neuron Firing Patterns
... has involved examining neuronal activity in laboratory animals under varying experimental conditions. Neural information is represented and communicated through series of action potentials, or spike trains, and the central scientific issue in many studies concerns the physiological significance that s ...
... has involved examining neuronal activity in laboratory animals under varying experimental conditions. Neural information is represented and communicated through series of action potentials, or spike trains, and the central scientific issue in many studies concerns the physiological significance that s ...


Integrate and Fire Neural Network
... • This is a digital system for doing IAF simulations, not an analog chip for simulating neurons. – Speed improved by factor of 103 over conventional digital. ...
... • This is a digital system for doing IAF simulations, not an analog chip for simulating neurons. – Speed improved by factor of 103 over conventional digital. ...

MIT Department of Brain and Cognitive Sciences Instructor: Professor Sebastian Seung
... 9.641J, Spring 2005 - Introduction to Neural Networks Instructor: Professor Sebastian Seung ...
... 9.641J, Spring 2005 - Introduction to Neural Networks Instructor: Professor Sebastian Seung ...


ppt
... (two thirds of the examples) and “test set” (remaining one third) • Train PSIPRED on training set, test predictions and compare with known answers on test set. • What is an answer? – For each position of sequence, a prediction of what secondary structure that position is involved in – That is, a seq ...
... (two thirds of the examples) and “test set” (remaining one third) • Train PSIPRED on training set, test predictions and compare with known answers on test set. • What is an answer? – For each position of sequence, a prediction of what secondary structure that position is involved in – That is, a seq ...

Methods S2.
... output of a neuron in layer k depends, through the non–linear activation function, only on the sum of inputs received from the neurons in layer k1, which are, in turn, computed using inputs from layer k2 and so on, up to the input layer. The feature that makes MLPs interesting for practical use is ...
... output of a neuron in layer k depends, through the non–linear activation function, only on the sum of inputs received from the neurons in layer k1, which are, in turn, computed using inputs from layer k2 and so on, up to the input layer. The feature that makes MLPs interesting for practical use is ...


Artificial Intelligence
... Artificial Neurons • Artificial neural networks are modeled on the human brain and consist of a number of artificial neurons. • Neurons in artificial neural networks tend to have fewer connections than biological neurons, and neural networks are all (currently) significantly smaller in terms of numb ...
... Artificial Neurons • Artificial neural networks are modeled on the human brain and consist of a number of artificial neurons. • Neurons in artificial neural networks tend to have fewer connections than biological neurons, and neural networks are all (currently) significantly smaller in terms of numb ...



Bump attractors and the homogeneity assumption
... Solutions • Fine tuning properties of each neuron. • Network learns to tune itself through an activity-dependent mechanism. – “Activity-dependent scaling of synaptic weights, which up- or downregulates excitatory inputs so that the long term average firing rate is similar for each neuron” ...
... Solutions • Fine tuning properties of each neuron. • Network learns to tune itself through an activity-dependent mechanism. – “Activity-dependent scaling of synaptic weights, which up- or downregulates excitatory inputs so that the long term average firing rate is similar for each neuron” ...
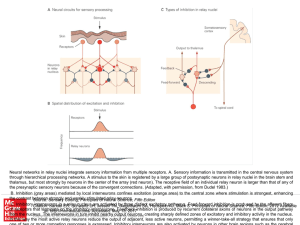


Theoretical Neuroscience: From Single Neuron to Network Dynamics
... – Insert such rules in networks, and study how inputs with prescribed statistics shape network attractor landscape – Study maximal storage capacity of the network, with different types of attractors – Learning rules that are able to reach maximal capacity? ...
... – Insert such rules in networks, and study how inputs with prescribed statistics shape network attractor landscape – Study maximal storage capacity of the network, with different types of attractors – Learning rules that are able to reach maximal capacity? ...

salinas-banbury-2004.
... • wij - connection from GM neuron j to output neuron i • Encoded target location is center of mass of output units • wij set to minimize difference between desired and driven output ...
... • wij - connection from GM neuron j to output neuron i • Encoded target location is center of mass of output units • wij set to minimize difference between desired and driven output ...

Supervised Learning
... Neural networks can use distributed representations; a particular object concept or action is represented by the pattern of activity object, across a population of neurons. Note that this is very different to the way conventional computers represent information using symbols. The connections can lea ...
... Neural networks can use distributed representations; a particular object concept or action is represented by the pattern of activity object, across a population of neurons. Note that this is very different to the way conventional computers represent information using symbols. The connections can lea ...