
Statistical models of network connectivity in cortical microcircuits
... experimental studies suggest, however, that cortical microcircuits are not well represented by ER models [1,2]. One major finding that supports this idea is the fact that the probability of a directed connection between a pair of neurons increases with the number of common neighbors they have [2]. I ...
... experimental studies suggest, however, that cortical microcircuits are not well represented by ER models [1,2]. One major finding that supports this idea is the fact that the probability of a directed connection between a pair of neurons increases with the number of common neighbors they have [2]. I ...

Application of ART neural networks in Wireless sensor networks
... with ART neural networks. There are two basic techniques: Fast learning ○ new values of W are assigned in at discreet moments in time and are determined by algebraic equations Slow learning ○ values of W at given point in time are determined by values of continuous functions at that point and de ...
... with ART neural networks. There are two basic techniques: Fast learning ○ new values of W are assigned in at discreet moments in time and are determined by algebraic equations Slow learning ○ values of W at given point in time are determined by values of continuous functions at that point and de ...

Neural Networks - Temple Fox MIS
... or not an output is produced (neuron fires) The transformation occurs before the output reaches the next level in the network Sigmoid (logical activation) function: an S-shaped transfer function in the range of zero to one –exp(x)/(1exp(x)) ...
... or not an output is produced (neuron fires) The transformation occurs before the output reaches the next level in the network Sigmoid (logical activation) function: an S-shaped transfer function in the range of zero to one –exp(x)/(1exp(x)) ...


Neural networks.
... in the radial basis function the kernel is the Gaussian transformation of the Euclidean distance between the support vector and the input). In the specific case of rbf networks—that we will use as an example of SVM—the output of the units of the hidden layers are connected to an output layer compose ...
... in the radial basis function the kernel is the Gaussian transformation of the Euclidean distance between the support vector and the input). In the specific case of rbf networks—that we will use as an example of SVM—the output of the units of the hidden layers are connected to an output layer compose ...

Biological Inspiration for Artificial Neural Networks
... Biological Inspiration for Artificial Neural Networks Nick Mascola ...
... Biological Inspiration for Artificial Neural Networks Nick Mascola ...

Artificial Intelligence 人工智能
... ji : the error valu e associated with the ith neuron in Layer j W jik : the connection weight from kth neuron in layer (j - 1) to the ith neuron in Layer j ...
... ji : the error valu e associated with the ith neuron in Layer j W jik : the connection weight from kth neuron in layer (j - 1) to the ith neuron in Layer j ...

machine learning and artificial neural networks for face
... • But still, we have no idea how we ‘perform’ face detection, we are just good at it • Nowadays, it’s « easy » to gather a lot of data (internet, social networks, …), so we have a lot of training data available ...
... • But still, we have no idea how we ‘perform’ face detection, we are just good at it • Nowadays, it’s « easy » to gather a lot of data (internet, social networks, …), so we have a lot of training data available ...


Artificial Neural Network (ANN)
... in the input data with no help from a teacher, basically performing a clustering of input space. • The system learns about the pattern from the data itself without a priori knowledge. This is similar to our learning experience in adulthood “For example, often in our working environment we are thrown ...
... in the input data with no help from a teacher, basically performing a clustering of input space. • The system learns about the pattern from the data itself without a priori knowledge. This is similar to our learning experience in adulthood “For example, often in our working environment we are thrown ...

Neural Networks
... The Discovery of Backpropagation • The backpropagation learning algorithm was developed independently by Rumelhart [Ru1], [Ru2], Le Cun [Cun] and Parker [Par] in 1986. • It was subsequently discovered that the algorithm had also been described by Paul Werbos in his Harvard Ph.D thesis in 1974 [Wer] ...
... The Discovery of Backpropagation • The backpropagation learning algorithm was developed independently by Rumelhart [Ru1], [Ru2], Le Cun [Cun] and Parker [Par] in 1986. • It was subsequently discovered that the algorithm had also been described by Paul Werbos in his Harvard Ph.D thesis in 1974 [Wer] ...
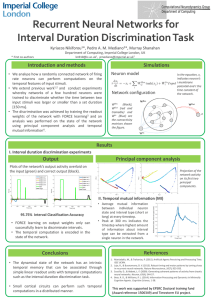
Recurrent Neural Networks for Interval Duration Discrimination Task
... • We analyse how a randomly connected network of firing rate neurons can perform computations on the temporal features of input stimuli. • We extend previous work1,2 and conduct experiments whereby networks of a few hundred neurons were trained to discriminate whether the time between two input stim ...
... • We analyse how a randomly connected network of firing rate neurons can perform computations on the temporal features of input stimuli. • We extend previous work1,2 and conduct experiments whereby networks of a few hundred neurons were trained to discriminate whether the time between two input stim ...

slides - Seidenberg School of Computer Science and Information
... “Neural Networks are an attempt to create machines that work in a similar way to the human brain by building these machines using components that behave like biological neurons” ...
... “Neural Networks are an attempt to create machines that work in a similar way to the human brain by building these machines using components that behave like biological neurons” ...

Part 7.2 Neural Networks
... Start with random weights Load training example’s input Observe computed input Modify weights to reduce difference Iterate over all training examples Terminate when weights stop changing OR when error is very small ...
... Start with random weights Load training example’s input Observe computed input Modify weights to reduce difference Iterate over all training examples Terminate when weights stop changing OR when error is very small ...

Document
... interconnection of simple processing units simple processing units store experience and make it available to use knowledge is acquired from environment thru learning process ...
... interconnection of simple processing units simple processing units store experience and make it available to use knowledge is acquired from environment thru learning process ...



The Symbolic vs Subsymbolic Debate
... (substitutable) grapheme – phoneme mappings and then plug them in (modulo contextual influences). ...
... (substitutable) grapheme – phoneme mappings and then plug them in (modulo contextual influences). ...



Artificial Neural Networks
... • An input is fed into the network and the output is being calculated. • We compare the output of the network with the target output, and we get the error. • We want to minimize the error, so we greedily adjust the weights such that error for this particular input will go towards zero. • We do so us ...
... • An input is fed into the network and the output is being calculated. • We compare the output of the network with the target output, and we get the error. • We want to minimize the error, so we greedily adjust the weights such that error for this particular input will go towards zero. • We do so us ...

A Neural Network Model for the Representation of Natural Language
... 1999), theories of linguistic analysis, and known variables drawn from the brain and cognitive sciences as well as previous neural network systems built for similar purposes. My basic hypothesis is that the association among concepts is primarily an expression of domain-general cognitive mechanisms ...
... 1999), theories of linguistic analysis, and known variables drawn from the brain and cognitive sciences as well as previous neural network systems built for similar purposes. My basic hypothesis is that the association among concepts is primarily an expression of domain-general cognitive mechanisms ...

Syllabus P140C (68530) Cognitive Science
... • Efficiency – Solve the combinatorial explosion problem: With n binary units, 2n different representations possible. (e.g.) How many English words from a combination of 26 alphabet letters? ...
... • Efficiency – Solve the combinatorial explosion problem: With n binary units, 2n different representations possible. (e.g.) How many English words from a combination of 26 alphabet letters? ...


Catastrophic interference

Catastrophic Interference, also known as catastrophic forgetting, is the tendency of a artificial neural network to completely and abruptly forget previously learned information upon learning new information. Neural networks are an important part of the network approach and connectionist approach to cognitive science. These networks use computer simulations to try and model human behaviours, such as memory and learning. Catastrophic interference is an important issue to consider when creating connectionist models of memory. It was originally brought to the attention of the scientific community by research from McCloskey and Cohen (1989), and Ractcliff (1990). It is a radical manifestation of the ‘sensitivity-stability’ dilemma or the ‘stability-plasticity’ dilemma. Specifically, these problems refer to the issue of being able to make an artificial neural network that is sensitive to, but not disrupted by, new information. Lookup tables and connectionist networks lie on the opposite sides of the stability plasticity spectrum. The former remains completely stable in the presence of new information but lacks the ability to generalize, i.e. infer general principles, from new inputs. On the other hand, connectionst networks like the standard backpropagation network are very sensitive to new information and can generalize on new inputs. Backpropagation models can be considered good models of human memory insofar as they mirror the human ability to generalize but these networks often exhibit less stability than human memory. Notably, these backpropagation networks are susceptible to catastrophic interference. This is considered an issue when attempting to model human memory because, unlike these networks, humans typically do not show catastrophic forgetting. Thus, the issue of catastrophic interference must be eradicated from these backpropagation models in order to enhance the plausibility as models of human memory.