

Tests of Hypotheses Using Statistics
... The method of hypothesis testing uses tests of significance to determine the likelihood that a statement (often related to the mean or variance of a given distribution) is true, and at what likelihood we would, as statisticians, accept the statement as true. While understanding the mathematical conc ...
... The method of hypothesis testing uses tests of significance to determine the likelihood that a statement (often related to the mean or variance of a given distribution) is true, and at what likelihood we would, as statisticians, accept the statement as true. While understanding the mathematical conc ...


Sample Size Estimation and Power Analysis
... * Peduzzi P et al. A simulation study of the number of events per variable in logistic regression analysis. J Clin Epidemiol. 1996 Dec;49(12):1373-9. * Peduzzi P et al. Importance of events per independent variable in proportional hazards regression analysis. II. Accuracy and precision of regression ...
... * Peduzzi P et al. A simulation study of the number of events per variable in logistic regression analysis. J Clin Epidemiol. 1996 Dec;49(12):1373-9. * Peduzzi P et al. Importance of events per independent variable in proportional hazards regression analysis. II. Accuracy and precision of regression ...

Extended-answer questions (90 MARKS)
... Extended-answer questions (90 MARKS) Show answers and any working in the spaces provided. Marks are given for correct and clearly set out working and answers. ...
... Extended-answer questions (90 MARKS) Show answers and any working in the spaces provided. Marks are given for correct and clearly set out working and answers. ...

The Population Standard Deviation
... The results vary from a low of 9.969 mL to a high of 9.994 mL. This 0.025-mL spread of data results directly from an accumulation of all random uncertainties in the experiment. The spread in a set of replicate measurements can be defined as the difference between the highest and lowest result. The f ...
... The results vary from a low of 9.969 mL to a high of 9.994 mL. This 0.025-mL spread of data results directly from an accumulation of all random uncertainties in the experiment. The spread in a set of replicate measurements can be defined as the difference between the highest and lowest result. The f ...


Unit 3 Statistics - Georgia Standards
... In tasks 5-7 of this framework, students will use statistics to determine if movie stars are exceptionally beautiful when compared to the general population. They will do this by making certain measurements of the face and calculating their ratios. Students will explore whether the movie star ratios ...
... In tasks 5-7 of this framework, students will use statistics to determine if movie stars are exceptionally beautiful when compared to the general population. They will do this by making certain measurements of the face and calculating their ratios. Students will explore whether the movie star ratios ...

Unit 1 Date Analysis
... 2. Reviewing some basics: a. Think about a single bag of Reese’s Pieces. Does this single bag represent a sample of Reese’s Pieces or the population of Reese’s pieces? b. We use the term statistic to refer to measures based on samples and the term parameter to refer to measures of the entire populat ...
... 2. Reviewing some basics: a. Think about a single bag of Reese’s Pieces. Does this single bag represent a sample of Reese’s Pieces or the population of Reese’s pieces? b. We use the term statistic to refer to measures based on samples and the term parameter to refer to measures of the entire populat ...

Extended-answer questions (90 MARKS)
... 34 It is reasonable to use the mean measure of the centre of a distribution: A when the distribution is negatively skewed B when the distribution is positively skewed C when the distribution is symmetric D when the distribution is symmetric with outliers E always 35 A student’s mark on a test is 75. ...
... 34 It is reasonable to use the mean measure of the centre of a distribution: A when the distribution is negatively skewed B when the distribution is positively skewed C when the distribution is symmetric D when the distribution is symmetric with outliers E always 35 A student’s mark on a test is 75. ...

Lecture 10: Descriptive Statistics
... The mode is the score that occurs most frequently. It is possible for there to be no mode for a distribution. It is possible for there to be more than one mode for a single distribution. It is relatively easy to locate and is useful in preliminary description. It is the only measure of central t ...
... The mode is the score that occurs most frequently. It is possible for there to be no mode for a distribution. It is possible for there to be more than one mode for a single distribution. It is relatively easy to locate and is useful in preliminary description. It is the only measure of central t ...


Respondent-Generated Intervals (RGI) For Recall in
... There is one comparison study so far. Schwartz and Paulin, 2000, carried out a study comparing response rates of different groups of randomly assigned participants who used either range cards, unfolding brackets, or RGI, with respect to income questions. To include RGI in their study Schwartz and Pa ...
... There is one comparison study so far. Schwartz and Paulin, 2000, carried out a study comparing response rates of different groups of randomly assigned participants who used either range cards, unfolding brackets, or RGI, with respect to income questions. To include RGI in their study Schwartz and Pa ...

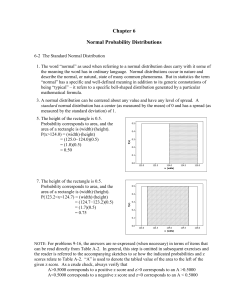
Chapter Six
... 35. a. The z scores are always unit free. Because the numerator and the denominator of the fraction z = (x-μ)/σ have the same units, the units will divide out. b. For a population of size N, μ = Σx/N and σ2 = Σ(x-μ)2/N. As shown below, μ = 0 and σ = 1 will be true for any set of z scores – regardles ...
... 35. a. The z scores are always unit free. Because the numerator and the denominator of the fraction z = (x-μ)/σ have the same units, the units will divide out. b. For a population of size N, μ = Σx/N and σ2 = Σ(x-μ)2/N. As shown below, μ = 0 and σ = 1 will be true for any set of z scores – regardles ...

Chapter 1 Collecting Data in Reasonable Ways
... 1.30 Random assignment allows the researcher to create groups that are equivalent, so that the subjects in each experimental group are as much alike as possible. This ensures that the experiment does not favor one experimental condition (playing Unreal Tournament 2004 or Tetris) over another. 1.31 ...
... 1.30 Random assignment allows the researcher to create groups that are equivalent, so that the subjects in each experimental group are as much alike as possible. This ensures that the experiment does not favor one experimental condition (playing Unreal Tournament 2004 or Tetris) over another. 1.31 ...



Chapt22_BPS
... F = 31.61 I = 3 classes of vehicle n1 = 31 midsize, n2 = 31 SUVs, n3 = 14 trucks N = 31 + 31 + 14 = 76 dfnum = (I1) = (31) = 2 dfden = (NI) = (763) = 73 Look up dfnum=2 and dfden=73 (use 50) in Table D; the value F = 31.61 falls above the 0.001 critical value. Thus, the P-value for this ANOVA F ...
... F = 31.61 I = 3 classes of vehicle n1 = 31 midsize, n2 = 31 SUVs, n3 = 14 trucks N = 31 + 31 + 14 = 76 dfnum = (I1) = (31) = 2 dfden = (NI) = (763) = 73 Look up dfnum=2 and dfden=73 (use 50) in Table D; the value F = 31.61 falls above the 0.001 critical value. Thus, the P-value for this ANOVA F ...

Chapter 8 Describing Data: Measures of Central Tendency and
... The reason why the sum of all the observations’ values is divided by N (the number of observations) is probably intuitively clear. Computing the Mean is something you have likely done innumerable times. It may, however, be informative to explain why the simple sum of a set of observations does not h ...
... The reason why the sum of all the observations’ values is divided by N (the number of observations) is probably intuitively clear. Computing the Mean is something you have likely done innumerable times. It may, however, be informative to explain why the simple sum of a set of observations does not h ...


Measuring Skewness: A Forgotten Statistic?
... usually are covered later in the semester (if at all). An instructor who does not want to develop the idea of statistical inference at this point can simply say that the current learning objective is to understand the concept of skewness, and to recognize its symptoms in a general way. Exam question ...
... usually are covered later in the semester (if at all). An instructor who does not want to develop the idea of statistical inference at this point can simply say that the current learning objective is to understand the concept of skewness, and to recognize its symptoms in a general way. Exam question ...


