Survey
* Your assessment is very important for improving the workof artificial intelligence, which forms the content of this project
Net neutrality law wikipedia , lookup
Multiprotocol Label Switching wikipedia , lookup
Backpressure routing wikipedia , lookup
Piggybacking (Internet access) wikipedia , lookup
Airborne Networking wikipedia , lookup
Computer network wikipedia , lookup
Distributed firewall wikipedia , lookup
Drift plus penalty wikipedia , lookup
Buffer overflow wikipedia , lookup
Buffer overflow protection wikipedia , lookup
Network tap wikipedia , lookup
Asynchronous Transfer Mode wikipedia , lookup
Wake-on-LAN wikipedia , lookup
Recursive InterNetwork Architecture (RINA) wikipedia , lookup
Cracking of wireless networks wikipedia , lookup
Internet protocol suite wikipedia , lookup
UniPro protocol stack wikipedia , lookup
Quality of service wikipedia , lookup
The Internet’s architecture
for managing congestion
Damon Wischik, UCL
www.wischik.com/damon
Some Internet History
• 1974: First draft of TCP/IP
[“A protocol for packet network interconnection”,
Vint Cerf and Robert Kahn]
• 1983: ARPANET switches on TCP/IP
• 1986: Congestion collapse
• 1988: Congestion control for TCP
[“Congestion avoidance and control”, Van Jacobson]
“A Brief History of the Internet”, the Internet Society
End-to-end control
Internet congestion is controlled by the end-systems.
The network operates as a dumb pipe.
[“End-to-end arguments in system design” by Saltzer, Reed, Clark, 1981]
request
User
Server
(TCP)
End-to-end control
Internet congestion is controlled by the end-systems.
The network operates as a dumb pipe.
[“End-to-end arguments in system design” by Saltzer, Reed, Clark, 1981]
Server
(TCP)
User
data
End-to-end control
Internet congestion is controlled by the end-systems.
The network operates as a dumb pipe.
[“End-to-end arguments in system design” by Saltzer, Reed, Clark, 1981]
acknowledgements
Server
(TCP)
User
data
The TCP algorithm, running on the server, decides how fast to send data.
traffic rate [0-100 kB/sec]
TCP
time [0-8 sec]
if (seqno > _last_acked) {
if (!_in_fast_recovery) {
_last_acked = seqno;
_dupacks = 0;
inflate_window();
send_packets(now);
_last_sent_time = now;
return;
}
if (seqno < _recover) {
uint32_t new_data = seqno - _last_acked;
_last_acked = seqno;
if (new_data < _cwnd) _cwnd -= new_data; else _cwnd=0;
_cwnd += _mss;
retransmit_packet(now);
send_packets(now);
return;
}
uint32_t flightsize = _highest_sent - seqno;
_cwnd = min(_ssthresh, flightsize + _mss);
_last_acked = seqno;
_dupacks = 0;
_in_fast_recovery = false;
send_packets(now);
return;
}
if (_in_fast_recovery) {
_cwnd += _mss;
send_packets(now);
return;
}
_dupacks++;
if (_dupacks!=3) {
send_packets(now);
return;
}
_ssthresh = max(_cwnd/2, (uint32_t)(2 * _mss));
retransmit_packet(now);
_cwnd = _ssthresh + 3 * _mss;
_in_fast_recovery = true;
_recover = _highest_sent;
}
How TCP shares capacity
individual
flow
bandwidths
available
bandwidth
sum of flow
bandwidths
time
Motivation: buffer size
• Internet routers have buffers,
to accomodate bursts in traffic.
• How big do the buffers need to be?
– 3 GByte? Rule of thumb—what Cisco does today
– 300 MByte? [Appenzeller, Keslassy, McKeown, 2004 ]
– 30 kByte?
• Large buffers are unsustainable:
– Data volumes double every 10 months
– CPU speeds double every 18 months
– Memory access speeds double every 10 years
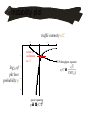
Motivation: TCP’s teleology
[Kelly, Maulloo, Tan, 1998]
U(x)
P(y,C)
• Consider several TCP flows sharing a single link
• Let xr be the mean bandwidth of flow r [pkts/sec]
Let y be the total bandwidth of all flows [pkts/sec]
Let C be the total available capacity [pkts/sec]
• TCP and the network act so as to solve
maximise r U(xr) - P(y,C)
over xr0 where y=r xr
x
C
y
U(x)
Bad teleology
severe penalty for
allocating too little
bandwidth
little extra valued
attached to highbandwidth flows
x
Bad teleology
U(x)
flows with large
RTT are satisfied
with little bandwidth
flows with small
RTT want more
bandwidth
x
P(y,C)
Bad teleology
no penalty unless
links are overloaded
C
y
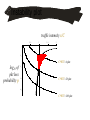
TCP’s teleology
U(x)
P(y,C)
• The network acts as if it’s trying to
solve an optimization problem
• Is this what we want the Internet to
optimize?
• Does it even succeed in performing the
optimization?
x
C
y
Synchronization
Desynchronized
TCP flows:
Synchronized
TCP flows:
aggregate
traffic rate
individual
flow rates
– aggregate traffic
is smooth
– network solves the
optimization
+
+
=
– aggregate traffic
is bursty
– network oscillates
about the optimum
+
+
=
time
Synchronization
Desynchronized
TCP flows:
Synchronized
TCP flows:
aggregate
traffic rate
individual
flow rates
– aggregate traffic
is smooth
– network solves the
optimization
+
+
=
– aggregate traffic
is bursty
– network oscillates
about the optimum
+
+
=
time
TCP traffic model
• When there are many TCP flows, the aggregate traffic rate
xt varies smoothly, according to a differential equation
[Misra, Gong, Towsley, 2000]
aggregate
traffic rate
• The equation involves
– pt, the packet loss probability at time t,
– RTT, the average round trip time
desynchronized
time
synchronized
traffic rate [0-100 kB/sec]
TCP
time [0-8 sec]
if (seqno > _last_acked) {
if (!_in_fast_recovery) {
_last_acked = seqno;
_dupacks = 0;
inflate_window();
send_packets(now);
_last_sent_time = now;
return;
}
if (seqno < _recover) {
uint32_t new_data = seqno - _last_acked;
_last_acked = seqno;
if (new_data < _cwnd) _cwnd -= new_data; else _cwnd=0;
_cwnd += _mss;
retransmit_packet(now);
send_packets(now);
return;
}
uint32_t flightsize = _highest_sent - seqno;
_cwnd = min(_ssthresh, flightsize + _mss);
_last_acked = seqno;
_dupacks = 0;
_in_fast_recovery = false;
send_packets(now);
return;
}
if (_in_fast_recovery) {
_cwnd += _mss;
send_packets(now);
return;
}
_dupacks++;
if (_dupacks!=3) {
send_packets(now);
return;
}
_ssthresh = max(_cwnd/2, (uint32_t)(2 * _mss));
retransmit_packet(now);
_cwnd = _ssthresh + 3 * _mss;
_in_fast_recovery = true;
_recover = _highest_sent;
}
Queue model
• How does packet loss probability pt
depend on buffer size?
• There are two families of answers,
depending on queueing delay:
– Small buffers (queueing delay « RTT)
– Large buffers (queueing delay RTT)
2000
20
20
200
10
20
5
5
20
20
200
15
time
0
0
time
[0-5
sec]
42
43
44
45
20
41
15
40
queueing
2000 delay
0.19 ms
15
20
15
200 delay
queueing
1.9 ms
10
val1
15
10
5
0
queue size
[0-15 pkt]
20
queueing
20 delay
19 ms
10
0
0
5
5
10
val1
15
15
Small buffers
val1
10
5
0
20
15
10
5
0
0
5
10
As the optical fibre’s line rate increases
– queue size fluctuates more and more rapidly
– queue size distribution
does
not
change
20
40
41
42
43
44
45
time
(it depends only on link utilization,
not on line rate)
40
41
42
43
time
44
45
Large buffers (queueing delay 200 ms)
queue
val1size
0
50
100
150
pkt]
[0-160
queueapprox
40
42
44
46
time
50
time 48[0-10 sec]
• When xt<C the queue size is small (C=line rate)
• No packet drops, so TCP increases xt
Large buffers (queueing delay 200 ms)
queue
val1size
0
50
100
150
pkt]
[0-160
queueapprox
40
42
44
46
time
50
time 48[0-10 sec]
• When xt<C the queue size is small (C=line rate)
• No packet drops, so TCP increases xt
• When xt>C the queue fills up
and packets begin to get dropped
Large buffers (queueing delay 200 ms)
queue
val1size
0
50
100
150
pkt]
[0-160
queueapprox
40
42
44
46
time
50
time 48[0-10 sec]
• When xt<C the queue size is small (C=line rate)
• No packet drops, so TCPs increases xt
• When xt>C the queue fills up
and packets begin to get dropped
• TCPs may ‘overshoot’, leading to synchronization
Large buffers (queueing delay 200 ms)
queue
val1size
0
50
100
150
pkt]
[0-160
queueapprox
40
42
44
46
time
50
time 48[0-10 sec]
• Drop probability depends on
both traffic rate xt and queue size qt
Analysis
• Write down differential equations
– for aggregate TCP traffic rate xt
– for queue dynamics and loss prob pt
taking account of buffer size
• Calculate
– average link utilization
– average queue occupancy/delay
– extent of synchronization
and consequent loss of utilization, and jitter
[Gaurav Raina, PhD thesis, 2005]
Stability/instability analysis
traffic
rate xt/C
1.4
1.2
0.8
0.6
20
40
60
80
100
20
40
60
80
100
1.4
1.2
0.8
0.6
• For some values of C*RTT,
the dynamical system is stable
• For others it is unstable and there are oscillations
(i.e. the flows are partially synchronized)
• When it is unstable,
we can calculate the amplitude of the oscillations
time
Instability plot
traffic intensity x/C
0.5
-1
log10 of
pkt loss
probability p
1
extent of
oscillations
in x/C
-2
-3
-4
queue equation
1.5
2
TCP throughput equation
Instability plot
traffic intensity x/C
0.5
1
1.5
2
-1
C*RTT=4 pkts
log10 of
pkt loss
probability p
-2
-3
C*RTT=20 pkts
-4
C*RTT=100 pkts
Alternative buffer-sizing rules
Intermediate buffers buffer = bandwidth*delay / sqrt(#flows)
or
Large buffers buffer = bandwidth*delay
b25
b100
b400
-1
-2
Large buffers with AQM
-3
buffer=bandwidth*delay*{¼,1,4}
-4
0.5
b10
1
1.5
b20
b50
-1
-2
Small buffers
-3
buffer={10,20,50} pkts
-4
0.5
b50
1
1.5
b1000
-1
-2
Small buffers, ScalableTCP
p -3
-4
buffer={50,1000} pkts
[Vinnicombe 2002] [T.Kelly 2002]
-5
-6
0.5
1
1.5
Conclusion
• The network acts to
solve an optimization problem.
– We can choose which optimization problem,
by choosing the right buffer size
& by changing TCP’s code.
• It may or may not attain the solution
– In order to make sure the network is stable,
we need to choose the buffer size & TCP code
carefully.
Prescription
• ScalableTCP in end-systems
need to persuade Microsoft, Linus
• Much smaller buffers in routers
need to persuade BT/AT&T
ScalableTCP gives
more weight to highbandwidth flows.
And it’s been shown
to be stable.
U(x)
P(y,C)
With small buffers,
the network likes to
run with slightly
lower utilization,
hence lower delay
x
C
y