Survey
* Your assessment is very important for improving the workof artificial intelligence, which forms the content of this project
History of randomness wikipedia , lookup
Indeterminism wikipedia , lookup
Stochastic geometry models of wireless networks wikipedia , lookup
Probabilistic context-free grammar wikipedia , lookup
Probability box wikipedia , lookup
Infinite monkey theorem wikipedia , lookup
Birthday problem wikipedia , lookup
Ars Conjectandi wikipedia , lookup
Dempster–Shafer theory wikipedia , lookup
Probabilistic Prediction
Algorithms
Jon Radoff
Biophysics 101
Fall 2002
Bayesian Decision Theory
• Originally developed by Thomas Bayes in
1763.*
• The general idea is that the likelihood of a
future event occurring is based on the past
probability that it occurred.
*Thomas Bayes. An essay towards solving a problem in the doctrine of
chances. Philosophical Transaction of the Royal Society (London),
53:370-418, 1763.
Bayes Theorem: Basic Example
A simplified Bayes Theorem simply tells us that in the
absence of other evidence, the likelihood of an event is
equal to its past likelihood. It assumes that the
consequences of an incorrect classification are always
the same (unlike, for example, a state such as “infected
with HIV vs. uninfected with HIV).
Let’s say we have a basket full of apples and oranges.
We remove 10 fruit from the basket, and observe that 8
are apples and 2 are oranges. A friend comes along and
picks a fruit, but hides it behind their back, challenging
us to guess what the fruit is. What’s our guess?
Bayes Theorem: Basic Example
In the format of Bayes Theorem, we’d give each
possibility a “class,” typically. We’ll designate
this with the set w:
w={w1,w2}
w1=apple
w2=orange
Based on prior information, P(w1)=0.8 and
P(w2)=0.2. Since P(w1) > P(w2), we guess that it
is an apple.
Bayes: Multiple Evidence
You might have multiple pieces of evidence. For
example, in addition to knowing the likelihood of
a random fruit from our basket, perhaps we had
previously used a colorimeter to that let us
associate the wavelength of light emitted from a
fruit with the type of fruit it was. In an informal
form, you could think of this as:
Posterior = likelihood X prior / evidence
Example: Continued
Let’s say we had taken those light readings earlier, and
generated a graph of the probability density of
detecting a particular wavelength of light given a
particular fruit. We’ll call the probability density p(x|wj).
The wavelength of light will be represented by the
random variable x.
0.3
0.25
0.15
0.1
0.05
0
40
0
45
0
50
0
55
0
60
0
65
0
70
0
Note that since this is
a probability density,
the area under either
curve is always 1.
0.2
w1 (apple)
w2 (orange)
Bayes: Formal Definition
Let P(x) be the probability mass of an
event. Let p(x) be the probability
density of an event (lowercase p).
P(wj|x) = p(x|wj) X P(wj) / p(x)
Bayes: Example, Continued
Let’s redo our original experiment.
Our friend is going to take a fruit from
the basket again, but he’s also going
to tell us that the wavelength of light
detected by his colorimeter was
575nm. What is our prediction now?
Bayes: Example, Continued
Previous probabilities from our light readings:
p(575|w1) = .05, p(575|w2) = .25
P(w1|575) = 0.05 X 0.8
/ ((.05 X 0.8)+(0.25 X 0.2)) = .44
P(w2|575) = 0.25 X 0.2
/ ((.05 X 0.8)+(0.25 X 0.2)) = .56
In this case, the additional evidence from the
colorimeter leads us to guess that it is an
orange (.56 > .44).
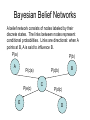
Bayesian Belief Networks
A belief network consists of nodes labeled by their
discrete states. The links between nodes represent
conditional probabilities. Links are directional: when A
points at B, A is said to influence B.
P(a)
P(b)
A
P(c|a)
P(e|c)
E
B
P(c|b)
C
P(d|c)
D
Bayesian Belief Network: Example
This over-simplified network illustrates how lung cancer is
influenced by other states, and how the presence of
particular symptoms might be influenced by lung cancer.
P(a)
P(b)
A
B
Smoker
P(c|a)
P(c|b)
Asbestos
exposure
C
P(e|c)
Lung
Cancer
P(d|c)
E
D
Coughing
Chest pain
Bayesian Belief Networks: Example
A human expert might provide us with
the matrices of all the probabilities in
the network, for example:
P(cancer|smoking):
cancer
healthy
Never
0.001
0.999
former
0.005
0.995
heavy
0.06
0.94
light
0.04
0.96
…and so forth for the 4 other nodes.
Bayesian Belief Networks
If you have complete matrices for
your belief network, you can make
predictions for any state in the
network given a set of input variables.
According to Bayes Theorem, if we
don’t know a particular state, we can
simply default to the overall prior
probability.
Bayesian Belief Networks: Example
Continued
In our example, we could now answer
questions such as:
•What is the likelihood a person will have
lung cancer given that they are a heavy
smoker and have been exposed to asbestos?
•A person has severe coughing, chest pain
and is a smoker. What is the likelihood of a
cancer diagnosis?
•What is the likelihood of past absestos
exposure given that a person has been
diagnosed with cancer?
Bayesian Belief Networks
The probability of a particular state is
the product of the probabilities of all
the states, given their prior states.
d
p ( k | x ) p ( xi | k )
i 1
Remember that p(x) is for probability
density, and P(x) is for probability mass.
Markov Chain
A markov chain is a type of belief network
where you have a sequence of states (x1, x2 …
xi) where the probability of each state is
dependent only on the previous state, i.e:
P(x1,x2,…xi,xi+1)
=P(xi+1|x1,x2,…xi)P(x1,x2,…xi)
Some content in this section from Matthew Wright, Hidden Markov Models
Markov Chain: Example
Let’s say we know the probability of any
particular nucleotide following another
nucleotide in a DNA sequence. For
example, the probability that a C follows
an A might be written as P(AC). If we
wanted to find the probability of finding
the sequence ACGTC, it would be
expressed as follows:
P(ACGTC)
=P(A)P(AC)P(CG)P(GT)P(TC)
Hidden Markov Models
In a Hidden Markov Model (HMM) the a
Markov Chain is expanded to include the
idea of hidden states. Given a set of
observations x1, x2…xn and a set of
hidden underlying states s1, s2…sn,
there is now a transition probability for
moving between the hidden states:
akl P(si l | si 1 k )
…where l and k are the states at positions I and i-1.
Emission Probabilities
At each state, there is a probability of
“emitting” a particular observation. We
define this as:
ekb P( xi b | si k )
…where e is the probability that the state k at
position i emits observation b, and si is the state at
position i and xi is the observation at that point.
Probability of a Path
The probability of an individual path
through a sequence of hidden states is a
restatement of Bayes theorem:
P( x, s) a0 s1 esi xi asi si1
i
In other words, the probability that we observe the
sequence of visible states is equal to the product of
the conditional probability that the system has made
a particular transition multiplied by the probability
that it emitted the observation in our target
sequence.
HMM Example: CpG Island
Let’s go back to our earlier example of the
sequence ACGTC, but now we’ll introduce two
hidden states: we may either be “in” or “out” of
a CpG island. Let’s designate in by + and out
by -. Here is how you would depict all the
transitions visually:
A C G T C
A+ C+ G+ T+ C+
A-
C- G- T-
C-
HMM Example: CpG Island
What is the probability that we’re in a CpG
island at position 3? (G+) We could depict all
of the potential paths to this as follows:
A C G T C
A+ C+ G+ T+ C+
A-
C- G- T-
C-
Simplified Total Probability of a
Path
In this example, we exclude emission
probabilities because there won’t be a
case of something such as a C- state
emitting an A observation. Algebraically,
the recursion of our formula for
determining the probability of a path
simplifies to:
L,i a kl a k ,i 1
k
HMM Example: CpG Island
Since this is a recursive algorithm, we need to
find position 2 before we can find position 3.
The possibility of C- at position 2 may be
expressed as:
C , 2 (a A ,C )(a 0, A )(a A,C )(a 0, A )
A C G T C
A+ C+ G+ T+ C+
A-
C- G- T-
C-
HMM Example: CpG Island
Likewise, the likelihood of C+ in position 2 is:
C , 2 (a A ,C )(a 0, A )(a A ,C )(a 0, A )
A C G T C
A+ C+ G+ T+ C+
A-
C- G- T-
C-
HMM Example: CpG Island
The probability of G+ in position 3 is thus:
G ,3 (a C ,G )[(a A,C )(a 0, A )(a A,C )(a 0, A )]
(a C ,G )[(a A,C )(a 0, A )(a A,C )(a 0, A )]
A C G T C
A+ C+ G+ T+ C+
A-
C- G- T-
C-