Survey
* Your assessment is very important for improving the workof artificial intelligence, which forms the content of this project
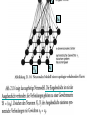
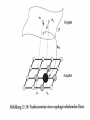
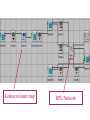
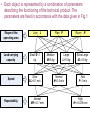
ek wik vij ai vij METHOD FOR AUTOMATED CHOICE OF TECHNICAL PRODUCTS The proposed method is based on automatically classification of technical products using only the entered by the customer parameters. These parameters forms the training set for a self-organizing network of Kohonen type. The automatically achieved classes then form the input training set for a Backpropagation (BPG) neural network which is intended to make the precisely classification of the entered parameters. • Stage 1: Defining the technical products classes per providing basic parameters. Coding of the classes per choosing the right code. • Stage 2: Generating a class related database using Kohonen self-organizing feature map. • Stage 3: Training the BPG neural network with input vectors of the achieved classes. • Stage 4: Automated choice of classes – recognition stage. • Stage 5: Outcome evaluation. Kohonen feature map BPG Network • Each object is represented by a combination of parameters describing the functioning of the technical product. The parameters are fixed in accordance with the data given in Fig.1 Shape of the operating area Line Load carrying capacity Small S<1 kg Speed Slow SL<0.1 m/s Repeatability L Normal NR<±0.1 mm Plain P Medium M<5 kg Large L<15 kg Normal N<0.4 m/s Room R Extra Large XL<15 kg Fast F<1 m/s High H<±0.025 mm Each combination of parameters forms an input vector to the classification system. Input vector • We use 35 combinations (classes) of the full network graph on Fig.1. which must be separated as different classes by the net. • These 35 input vectors form a subset of NN’s input training data (Table 1). Table 1 represents only 10 of the possible input vectors. The eight input parameters of each vector are attached to the neurons in the Kohonen grid. (Fig.2). • At the end of these stage we achieve automatically the definition of the classes. • The eight input parameters corresponding to each of the defined by Kohonen network classes are attached to the neurons in the input layer of a BPG neural network (Fig.2). • Results of Kohonen classification These network is intended to be trained with these parameters aiming to make an end precisely classification. We choose a 3-layered network with one input layer, one hidden layer and one output layer. The doubled number (16) of neurons by comparison with the number in the input layer would be a good choice [4] considering the high degree of class overlapping. The output layer contains 35 neurons each representing the corresponding class. The BPG NN training mode is chosen to be “Random Pattern Presentation” and Tangens Hyperbolic is applied as Transfer function for each NN layer. EVALUATION OF THE EXPERIMENTAL RESULTS • The size of the map is 10x10 nodes (Fig.2) which is the best case in terms of a good distinguishing between the classes. • The BPG network is trained with the data in Table 1 and with the preliminary defined classes, achieving a training error (MSE-Mean Square Error) of 0.005 (Fig. 3.), by learning rate of 0.2, epoch count of 31646 and 37 seconds training time (Table 2.). • In query mode 50 exemplars (not included in the training set) of products with different combinations between input parameters were classified with a very good classification rate of 96% (Table 2.). Die Hauptnachteile von KNN sind gegenwärtig • Das Trainieren von KNN führt in der Regel zu hochdimensionalen, nichtlinearen Optimierungsproblemen. • Die prinzipielle Schwierigkeit bei der Lösung dieser Probleme besteht in der Praxis häufig darin, dass man nicht sicher sein kann, ob man das globale (!) Optimum gefunden hat oder nur ein lokales. • Eine zeitaufwändige Näherung an die globale Lösung erreicht man durch die vielfache Wiederholung der Optimierung mit immer neuen Startwerten. • Die Kodierung der Trainingsdaten muss problemangepasst und nach Möglichkeit redundanzfrei gewählt werden. • In welcher Form die zu lernenden Daten dem Netz präsentiert werden, hat einen großen Einfluss auf die Lerngeschwindigkeit, sowie darauf, ob das Problem überhaupt von einem Netz gelernt werden kann. • Je präziser das Problem allein durch die Vorverarbeitung und Kodierung gestellt wird, desto erfolgreicher kann ein KNN dieses verarbeiten. Konsequenzen • Neuronale Netze sind ungeeignet für deterministische Aufgaben (Regeln, Berechnungen, absolute Fehlerfreiheit). Es ist besser kleine Neuronale Netze zu verwenden (kurze Trainingszeiten / geringe Gefahr des Auswendiglernens / gute Generalisierungsfähigkeit / gut analysierbar). Redundanz in den Outputs verwenden (gute Unterscheidung von klaren und unsicheren Entscheidungen des Netzwerks / gute Überprüfung der Reaktion des Netzwerks auf untrainierte Inputs / gute Erkennung der für das Netzwerk neuen Situationen. Vorverarbeitung gut planen (Entwicklung geeigneter Trainings- und Test-Dateien aus den vorliegenden Daten / Umwandlung großer Input-Vektoren in (evtl. mehrere) kleine Input-Vektoren für kleine Netze . Modularisierung des Netzwerks (Aufbau des Gesamtsystems aus Teilen mit verschiedenen Einzelaufgaben wie etwa: Vorverarbeitungen, Regelverarbeitungen, Berechnungen / klassischer top-down-Entwurf eines hybriden Systems, in dem Netze und klassische Programmteile realisiert werden.). Vorverarbeitung In allen Anwendungssituationen ist eine mehr oder weniger aufwendige Aufarbeitung der vorhandenen Daten nötig. Verschiedene Eingabeparameter müssen auf etwa übereinstimmende Größenordnungen normiert werden, damit nicht ein Parameter alle übrigen dominiert. Korrelationen zwischen verschiedenen Parametern sollten eliminiert werden. Periodisches Zeitverhalten kann vorab durch Fourier-Analyse und Ähnliches bestimmt werden.