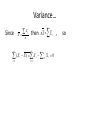Survey
* Your assessment is very important for improving the workof artificial intelligence, which forms the content of this project
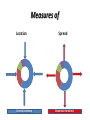
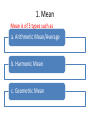
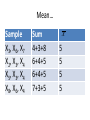
A.MEASURES OF LOCATION & B.MEASURES OF SPREAD Central tendency and measures of dispersion Measures of Location Central tendency Spread Dispersion tendency A Measures of Location (Central tendency) Common measures of location are 1. Mean 2. Median 3. Mode 1. Mean Mean is of 3 types such as a. Arithmetic Mean/Average b. Harmonic Mean c. Geometric Mean Arithmetic Mean The most widely utilized measure of central tendency is the arithmetic mean or average. The population mean is the sum of the values of the variables under study divided by the total number of observations in the population. It is denoted by μ (‘mu’). Each value is algebraically denoted by an X with a subscript denotation ‘i’. For example, a small theoretical population whose objects had values 1,6,4,5,6,3,8,7 would be denoted X1 =1, X2 = 6, X3 = 4……. X8=7 …….1.1 Mean…. We would denote the population size with a capital N. In our theoretical population N=8. The pop. mean μ would be 1 6 4 5 6 3 8 7 5 8 Formula 1.1: The algebraic shorthand formula N for a pop. mean is Xi i 1 μ= N Mean….. • The Greek letter (sigma) indicates summation, the subscript i=1 means to start with the first observation, and the superscript N means to continue until and including the Nth observation. For the example above, Xi would indicate the sum of X2+X3+X4+X5 or 6+4+5+6 = 21. To reduce clutter, if the summation sign is not indexed, for example Xi, it is implied that the operation of addition begins with the first observation and continues through the last observation in a X population, that is, = 5 i2 N i 1 Xi i Mean… N X i The sample mean is defined by X = n Where n is the sample size. The sample mean is usually reported to one more decimal place than the data and always has appropriate units associated with it. The symbol X (X bar) indicates that the observations of a subset of size n from a population have been averaged. i 1 Mean…. X is fundamentally different from μ because samples from a population can have different values for their sample mean, that is, they can vary from sample to sample within the population. The population mean, however, is constant for a given population. Mean….. Again consider the small theoretical population 1,6,4,5,6,3,8,7. A sample size of 3 may consists of 5,3,4 with X = 4 or 6,8,4 with X = 6. Actually there are 56 possible samples of size 3 that could be drawn from the population 1.1. Only four samples have a sample mean the same as the population mean ie X = μ. Mean… Sample X3, X6, X7 X2, X3, X4 X5, X3, X4 X8, X6, X4 Sum 4+3+8 6+4+5 6+4+5 7+3+5 X 5 5 5 5 Mean… Each sample mean X is an unbiased estimate of μ but depends on the values included in the sample size for its actual value. We would expect the average of all possible X ‘s to be equal to the population parameter, μ . This is in fact, the definition of an unbiased of the pop. mean. estimator Mean… If you calculate the sample mean for each of the 56 possible samples with n=3 and then average these sample means, they will give an average value of 5 , that is, the pop. mean, μ. Remember that most real populations are too large or too difficult to census completely, so we must rely on using a single sample to estimate or approximate the population characteristics. Harmonic mean Geometric mean n= no of obs., X1, X2, X3……..Xn are individual obs. Median The second measure of central tendency is the MEDIAN. The median is the middle most value of an ordered list of observations. Though the idea is simple enough, it will prove useful to define in terms of an even simple notion. The depth of a value is its position relative to the nearest extreme (end) when the data are listed in order from smallest to largest. Median: Example 2.1 Table below gives the circumferences at chest height (CCH) in cm and their corresponding depths for 15 sugar maples measured in a forest in Ohio. CCH Depth 18 1 21 22 29 29 36 37 38 56 59 66 70 88 93 120 2 3 4 5 6 7 8 7 6 5 4 3 No. of obs. = 15 (odd) The population median M is the observation whose depth is d = N 2 1 , where N is the population size. 2 1 Median… A sample median M is the statistic used to approximate or estimate the population median. M is defined as the observation n 1 whose depth is d = 2 where n is the sample size. In example 2.1 the sample size is n=15 so the depth of the sample median is d=8. the sample median X n 1 = X8 = 38 cm. 2 Median: Example 2.2 The table below gives CCH (cm) for 12 cypress pines measured near Brown lake on North Stradebroke Island CCH 17 19 31 39 48 56 68 73 73 75 80 122 Depth 1 2 3 4 5 6 6 5 4 3 2 1 No. of observation = 12 (even) 12 1 Since n=12, the depth of the median is = 6.5. Obviously no observation has 2 depth 6.5 , so this is the interpretation as the average of both observations whose depth is 6 in the list above. So M = 56 68 = 62 cm. 2 Mode The mode is defined as the most frequently occurring value in a data set. The mode in example 2.2 would be 73 cm while example 2.1 would have a mode of 29 cm. Mean, median and mode concide • In symmetrical distributions (NORMAL DISTRIBUTION), the MEAN, MEDIAN and MODE coincide. Exercise Hen egg sizes(ES,g) on 12 wks of lay were randomly measured in a layer flock as follows. Determine mean, median and mode of eggs. size. Hen 01 No. 02 03 04 05 06 07 08 09 10 11 12 ES 41 47 50 49 44 46 41 39 38 45 40 44 B Measures of Spread (dispersion) It measures variability of data. There are 4 measures in common. 1. Range 2. Variance 3. Standard Deviation (SD) 4. Standard Error (SE) Range Range: The simplest measure of dispersion or spread of data is the RANGE Formula: The difference between the largest and smallest observations (two extremes) in a group of data is called the RANGE. Sample range= Xn – X1 ; Population range=XN-X1 The values Xn and X1 are called ‘sample range limits’. Range: Example Marks of Biometry of 10 students are as follows (Full marks 100) Student ID Marks Obtained Marks ordered 01 35 80 02 40 75 03 30 70 04 25 60 05 75 40 06 80 40 07 39 39 08 40 35 09 60 30 10 70 25 Here, Range = X1-X10=80-25 = 55 Range… The range is a crude estimator of dispersion because it uses only two of the data points and is somewhat dependent on sample size. As sample size increases, we expect largest and smallest observations to become more extreme. Therefore, sample size to increase even though population range remains unchanged. It is unlikely that sample will include the largest and smallest values from the population, so the sample range usually underestimates the population range and is ,therefore, a biased estimator. Variance Suppose we express each observation as a distance from the mean xi = Xi - X . These differences are called deviates and will be sometimes positive (Xi is above the mean) and sometimes negative (Xi is below the mean). If we try to average the deviates, they always sum to zero. Because the mean is the central tendency or location, the negative deviates will exactly cancel out the positive deviates. Variance… X Mean 2 3 1 8 6 Sum -2 -1 -3 4 2 0 4 = Deviates (X X ) i 0 Example Variance… • Algebraically one can demonstrate the same result more generally, n n n ( Xi X ) X X i 1 Since X n (X i 1 i 1 i 1 is a constant for any sample, X ) i 1 X i n X , n i i Variance… Since X X n n (X i 1 i then n X X i , n i X ) X i i 1 X i 0 i 1 n so Variance… • To circumvent the unfortunate property , the widely used measure of dispersion called the sample variance utilizes the square of the deviates. The quantity ( X X ) is the sum of these squared deviates and is referred to as the corrected sum of squares (CSS). Each observation is corrected or adjusted for its distance from the mean. n 2 i 1 i Variance… • Formula: The CSS is utilized in the formula for the sample variance s 2 2 ( X X ) i n The sample variance is usually reported to two more decimal places than the data and has units that are the square of the measurement units. Variance… Or s 2 X 2 i ( X i ) / n 2 n 1 With a similar deviation the population variance computational formula can be shown to be 22 22 X X ( ( X X ) ) ii // Nn 22 ii N Variance…Example(unit Kg) • Data set 3.1, 17.0, 9.9, 5.1, 18.0, 3.8, 10.0, 2.9, 21.2 X i 91 X 2 i 1318.92 n=9 1318.92 (91) 2 / 9 1318.92 920.11 398.81 s 49.851Kg 2 9 1 8 8 2 Variance… Remember, the numerator must always be a positive number because it is sum of squared deviations. Population variance formula is rarely used since most populations are too large to census directly. Standard deviation (SD) • Standard deviation is the positive square root of the variance X i ( X i ) / N 2 And s X 2 N 2 i ( X i ) 2 / n n 1 Standard Error (SE) SE SD n= no. of observation n Exercise 2 Daily milk yield (L) of 12 cows are tabulated below. Calculate mean, median, mode, variance and standard error. Cow no 1 Milk yield Cow no 23.7 7 Milk yield 21.5 2 12.8 8 25.2 3 4 5 6 28.9 21.4 14.5 28.3 9 10 11 12 21.4 25.2 19.5 19.6 Problem 1 • Two herds of cows located apart in Malaysia gave the following amount of milk/day (L). Compute arithmetic mean, median, mode, range, variance, SD and SE of daily milk yield in cows of the two herds. Put your comments on what have been reflected from two sets of milk records as regards to their differences. Table Herd 1 Herd 2 • Cow no. 1 18.25 • 2 12.60 • 3 15.25 • 4 16.10 • 5 18.25 • 6 15.25 • 7 12.80 • 8 15.65 • 9 14.20 • 10 10.20 • 11 10.90 • 12 12.60 • • • • • • • • • • • • • • Cow no. 1 7.50 2 6.95 3 4.20 4 5.10 5 4.50 6 6.15 7 6.90 8 7.50 9 7.80 10 10.20 11 6.30 12 7.50 13 5.75 14 4.75 Problem 2 • Sex adjusted weaning weight of lambs in two different breeds of sheep were recorded as follows. Compute mean, median, range, variance and SE in weaning weight of lambs in two breed groups. Put your comments on various differences between the two groups. Weaning wt. (Kg) of lambs Breed 1 Breed 2 • • • • • • • • • • • • • • • • • • • • • • • • • • 7.5 6.9 8.1 5.8 5.9 5.8 6.2 7.5 9.1 8.7 8.1 8.5 5.6 4.7 9.8 4.5 6.1 3.6 5.7 4.9 5.1 5.1 5.9 4.0 9.8 10.2 Problem No 3 In a market study data on the price (RM) of 10 kg rice were collected from 2 different markets in Malaysia. Using descriptive statistics show the differences relating to price of rice in the two markets. Pasar 1: 20, 25, 22, 23, 22, 24, 23, 21, 25, 25,23,22,25,24,24 Pasar 2: 25, 24, 26, 23, 26, 25, 25, 26, 24, 26, 24, 23,22, 25, 26, 26, 24