Survey
* Your assessment is very important for improving the workof artificial intelligence, which forms the content of this project
* Your assessment is very important for improving the workof artificial intelligence, which forms the content of this project
Universidad Simón Bolívar
Challenges for Consuming and
Mining Linked Data
Maria-Esther Vidal
Joint work with
Guillermo Palma, Maribel Acosta, Louiqa Raschid
1
Graphs …
Relationships among artists in Last.fm
http://sixdegrees.hu/last.fm/
Network of Friends in a High School
Network structure of music genres and
their stylistic origin
http://www.infosysblogs.com/web2/2013/01/network_structure_of_music_gen.html
Network structure of Patent Citations
http://www.infosysblogs.com/web2/2013/07/
2
Tasks to be Solved …
Patterns of connections
between people to understand
functioning of society.
Topological properties
of graphs can be used to identify
patterns that reveal phenomena,
anomalies and potentially lead to
a discovery.
A significant increase of graph data in the form of social & biological information.
3
Graphs …
Linking Open Data Cloud (LOD cloud)
http://data.dws.informatik.uni-mannheim.de/lodcloud/2014/ISWC-RDB/
4
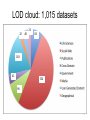
LOD cloud: 1,015 datasets
22
48
22
83
183
41
520
96
5
Five-Star Linked Open Data
6
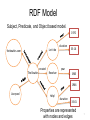
RDF Model
Subject, Predicate, and Object based model.
1970
Let it be
thebeatles.com
The Beatles
created
Revolver
duration
35:16
year
1965
1966
Liverpool
Help!
duration
35:01
Properties are represented
with nodes and edges
7
Five-Star Linked Open Data
8
Linked Datasets
9
Endpoints
Web services that implement the
SPARQL protocol, and enable
users to query particular
datasets or to dereference
Linked Data.
10
Linking Open Data Cloud
Tasks to be Solved …
Traverse and Consume
Linked Data from the LOD cloud or
locally.
11
Linking Open Data Cloud
Life Sciences
85 Datasets comprised of
biological objects (e.g., diseases,
drugs, genes) which are
annotated with controlled
vocabularies:
GO, MeSH, SNOMED, NCI
Thesaurus.
Links form a graph that captures
meaningful knowledge.
Annotation graphs can explain:
phenomena, identify anomalies, and
potentially lead to discovery, e.g.,
patterns between annotation or new
links.
12
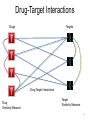
Drug-Target Interactions
Drugs
Targets
13
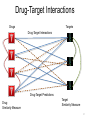
Drug-Target Interactions
Drugs
Targets
Drug
Similarity Measure
14
Drug-Target Interactions
Drugs
Drug
Similarity Measure
Targets
Target
Similarity Measure
15
Drug-Target Interactions
Drugs
Targets
Drug-Target Interactions
Drug
Similarity Measure
Target
Similarity Measure
16
Drug-Target Interactions
Drugs
Targets
Drug-Target Interactions
Drug-Target Predictions
Drug
Similarity Measure
Target
Similarity Measure
17
Agenda
1
Data Mining Techniques
2
Semantic Data Management Techniques
18
1
DATA MINING TECHNIQUES
FOR LINK PREDICTION
Joint work with
Guillermo Palma (PhD student)
Universidad Simón Bolívar
Louiqa Raschid
Guillermo Palma, Maria-Esther Vidal and Louiqa Raschid. Drug-Target Interaction Prediction Using
Semantic Similarity and Edge Partitioning. Accepted at ISWC 2014.
Guillermo Palma, Maria-Esther Vidal, Louiqa Raschid and Andreas Thor.
Exploiting Semantics from Ontologies and Shared Annotations to Partition Linked Data.
DILS 2014.
Guillermo Palma, Maria-Esther Vidal, Eric Haag, Louiqa Raschid and Andreas Thor.
Measuring Relatedness Between Scientific Entities in Annotation Datasets. ACM BCB. 2013.
Joseph Benik, Caren Chang, Louiqa Raschid, Maria-Esther Vidal, Guillermo Palma and
Andreas Thor. Finding Cross Genome Patterns in Annotation Graphs. DILS 2012.
19
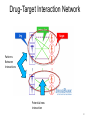
Drug-Target Interaction Network
Patterns
Between
Interactions
Potential new
interaction
20
semEP
Similarity
Measures
21
d1
e4
d2
E1
t1
e1
e2 t2
d3
e7
d
4
d5
e6
e8
e9
e3 t3
e5
E2
t4
t5
Bipartite Graph
22
Semantics Based Edge Partitioning
Problem (semEP)
d1
t1
e1
e4
d2
e2 t2
d3
e7
d
4
d5
e6
e8
e9
Minimize
the number
of clusters
Density of the
Clusters
is
Maximized
e3 t3
e5
t4
t5
Semantics
is
used to compute
similarity
semEP is the problem of partitioning the edges of the bipartite graph into
the minimal set of clusters such that
cluster density is maximized.
23
Mapping to Vertex Coloring
Graph (VCG)
semEP bipartite graph
24
Mapping to VCG
semEP bipartite graph
VCG
Edges in the bipartite graph are mapped to edges in VCG.
There is an edge e between two nodes l1=(t1,d1) and l2=(t2,d2) in VCG iff:
sim(t1,t2) < θt, threshold on the similarity of t1 and t2, OR
sim(d1,d2) < θd, threshold on the similarity of d1 and d2
25
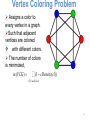
Vertex Coloring Problem
Assigns a color to
every vertex in a graph.
Such that adjacent
vertices are colored
with different colors.
The number of colors
is minimized,
nc(VCG) =
å(1 - cDensity(cl))
clÎUsedColors
26
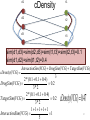
d1
cDensity
t1
d2
t2
d3
t3
sim(d1,d3)=sim(d2,d3)=sim(t1,t3)=sim(t2,t3)=0.1
sim(d1,d2)=sim(t1,t2)=0.4
InteractionSim(VCG) + DrugSim(VCG) + T argetSim(VCG)
cDensity(VCG) =
3
2 * (0.1+ 0.1+ 0.4)
DrugSim(VCG) =
= 0.2
3* 2
2 * (0.1+ 0.1+ 0.4)
T argetSim(VCG) =
= 0.2
3* 2
1+1+1+1+1
InteractionSim(VCG) =
=1
5
cDensity(VCG) =0.47
27
Vertex Coloring Problem
Assigns a color to
every vertex in a graph.
Such that adjacent
vertices are colored
• with different colors.
The number of colors
is minimized.
Deciding if a coloring of the graph is minimal or not is a NP-hard Problem
DSATUR an approximation that can find optimal solutions depending on the
shape of the input graph!
28
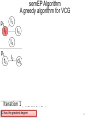
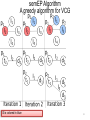
semEP Algorithm
A greedy algorithm for VCG
I2 has the greatest degree
29
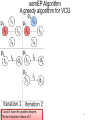
semEP Algorithm
A greedy algorithm for VCG
I1 and I3 have the greatest degree;
The tie is broken in favor of I1
30
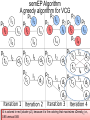
semEP Algorithm
A greedy algorithm for VCG
I3 is colored in blue
31
semEP Algorithm
A greedy algorithm for VCG
I4 is colored in red (cluster p2), because it is the coloring that maximizes cDensity,32i.e.,
0.85 versus 0.65
1
EMPIRICAL EVALUATION
33
Evaluation on Drug-Target Interactions
900 Drugs, 1,000 Targets and 5,000
Interactions: Nuclear receptor, Gproteincoupled receptors (GPCRs), Ion channels, and
Enzymes.
DrugBank
K. Bleakley and Y. Yamanishi. Supervised prediction of drug target interactions using bipartite local
models. Bioinformatics, 25(18).2009.
Drug Similarity: drug-drug chemical similarity Target Similarity: target-target similarity score
based on the normalized Smith-Waterman
score based on the hashed fingerprints from
sequence similarity score.
SMILES
34
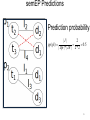
semEP Predictions
Prediction probability:
|I |
2
pp( p1) =
=
= 0.5
| Dp |* | Dt | 2 * 2
35
Method
A 10-fold cross validation:
• Training data: Randomly selected 90% of
positive and negative interactions.
• Test data: remaining 10% of the
interactions.
36
Experiment I
Research Question: Can semEP predictions
improve the performance of state-of-the art
prediction methods?
Method:
Ycntrl
YsemE
P
Best semEP prediction interactions (pp>0.5) are
added to the initial positive predictions of each
method.
No more than 30% of positive predictions added.
The same number of Random predictions are added
as baseline.
37
State-of-the-art Machine Learning
Methods
BLM: Bipartite Local Method [Cheng et al]
LapRLS: Laplacian Regularized Least Squares
[Xia et al]
GIP: Gaussian Interaction Profile [Van
Laarhoven et al]
KBMF2K: Kernelized Bayesian Matrix
Factorization with twin Kernels [Gonen]
NBI: Network-Based Inference [Cheng et al
38
Evaluation of semEP and State-ofthe-art Machine Learning Methods
semEP is able to improve performance of all the methods
Performance of the methods degrades for Ycntrl
39
Overlap of Top10 positive
predictions
The overlap is remarkably low.
Results suggest that semEP predictions are accurate and
diverse.
40
Experiment II
Research Question: Can semEP novel
predictions be validated?
Method:
Top5 novel predicted interactions are
validated in the STITCH drug-target
interaction website.
Novel predicted interaction are interactions
that do not appear in the dataset.
STITCH http://stitch.embl.de/
41
Validation of Top 5 Drug-Target
Interactions (Novel predictions)
Novel predicted interaction are interactions that do not
appear in the dataset.
semEP novel predicted interactions can be validated across
all target groups.
Top 5 were validated in STITCH http://stitch.embl.de/
42
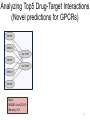
Analyzing Top5 Drug-Target Interactions
(Novel predictions for GPCRs)
Top1:
D00283 hsa:11255
iDensity: 0.9
43
Analyzing Top5 Drug-Target Interactions
(Novel predictions for GPCRs)
Top1:
D00283 hsa:11255
iDensity: 0.9
Top 2, 3, and 4:
D02076 hsa:146
D02076 hsa:147
D00604 has:147
iDensity: 0.8
44
Analyzing Top5 Drug-Target Interactions
(Novel predictions for GPCRs)
Top5:
D02250 has:6751
iDensity: 0.75
Top1:
D00283 hsa:11255
iDensity: 0.9
Top 2, 3, and 4:
D02076 hsa:146
D02076 hsa:147
D00604 has:147
iDensity: 0.8
45
Analyzing Top5 Drug-Target Interactions
(Novel predictions for GPCRs)
Drug Similarity Statistics:
Min:0.0
Max: 1.0
Average: 0.22
Median: 0.21
Threshold: 0.28
Majority of Pair-wise
Drug Similarity
In Percentile 85%
Target Similarity Statistics:
Min:0.01
Max: 0.92
Average: 0.09
Median: 0.07
Threshold: 0.14
Majority of Pair-wise
Target Similarity 46
In Percentile 98%
Analyzing Top5 Drug-Target Interactions
(Novel predictions for GPCRs)
Drug Similarity Statistics:
Min:0.0
Max: 1.0
Average: 0.22
Median: 0.21
Threshold: 0.28
Majority of Pair-wise
Drug Similarity
In Percentile 85%
Target Similarity Statistics:
Min:0.01
Max: 0.92
Average: 0.09
Median: 0.07
Threshold: 0.14
Majority of Pair-wise
Target Similarity 47
In Percentile 90%
Analyzing Top5 Drug-Target Interactions
(Novel predictions for GPCRs)
Drug Similarity Statistics:
Min:0.0
Max: 1.0
Average: 0.22
Median: 0.21
Threshold: 0.28
Pair-wise Drug Similarity
In Percentile 98%
Target Similarity Statistics:
Min:0.01
Max: 0.92
Average: 0.09
Median: 0.07
Threshold: 0.14
Pair-wise Target Similarity
In Percentile 98% 48
Team semEP
Guillermo Palma
Maria-Esther Vidal
Louiqa Raschid
49
Source
Selection
Data
Management
and Query
Processing
Benchmarking
Data Access
50
2
ANAPSID: AN ADAPTIVE
QUERY ENGINE FOR
FEDERATIONS OF SPARQL
ENDPOINTS.
Joint work with
Maribel Acosta
Maribel Acosta, Maria-Esther Vidal, Tomas Lampo, Julio Castillo and Edna Ruckhaus.
ANAPSID: An Adaptive Query Processing Engine for SPARQL Endpoints. ISWC 2011.
Gabriela Montoya, Maria-Esther Vidal and Maribel Acosta. A Heuristic-Based Approach for
Planning Federated SPARQL Queries. COLD 2012.
Gabriela Montoya, Maria-Esther Vidal, Oscar Corcho, Edna Ruckhaus and Carlos Buil-Aranda.
Benchmarking Federated SPARQL Query Engines: Are Existing Testbeds Enough? ISWC 2012.
51
ANAPSID
• An adaptive SPARQL query processing engine
• It is designed for executing queries against a
federation of SPARQL endpoints
– Performs query decomposition and source selection
– Attempts to minimize the workload in the endpoints
• It is open source and implemented in Python 2.7:
– https://github.com/anapsid/anapsid
52
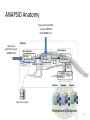
ANAPSID Anatomy
Query with specified
sources (SERVICE
from SPARQL 1.1)
Query w/o
specified sources
(SPARQL 1.0)
Mediator
Query Engine
Query Planner
Query
Decomposer
Logical
Optimizer
SPARQL 1.1 Query
Logical
plan
Physical
Optimizer
Physical
plan
Adaptive Query
Executor
Wrapper
Wrapper
Wrapper
Source Descriptions
Federations of Endpoints
53
Query Decomposer (1)
• Performs three main tasks:
① Query decomposition
① Source selection
① Filter pushdown
54
• CD6 Query from FedBench
@PREFIX foaf:<http://xmlns.com/foaf/0.1/>
@PREFIX geonames:<http://www.geonames.org/ontology#>
SELECT ?name ?location WHERE {
?artist foaf:name ?name .
?artist foaf:based_near ?location .
?location geonames:parentFeature ?germany .
?germany geonames:name 'Federal Republic of Germany’ .
}
55
• CD6 Query from FedBench
@PREFIX foaf:<http://xmlns.com/foaf/0.1/>
@PREFIX geonames:<http://www.geonames.org/ontology#>
@Jamendo
SWDF
SELECT ?name ?location WHERE {
DBpedia,
?artist foaf:name ?name .
Bibliographic
@LMDB ?artist foaf:based_near ?location .
SWDF ?location geonames:parentFeature ?germany .
?germany geonames:name 'Federal Republic of Germany’ .
}
@DBpedia
56
Query Decomposer (2)
① Query decomposition
– Groups triple patterns that can be resolved by the same set of
endpoints
– Exact star-shaped group (ESSG): Groups of pattern combinations
according to exactly one common variable
– Satellite: A triple pattern is a satellite of a ESSG if it shares one
variable with the ESSG and the rest of the pattern is constant
Example of ESSG
with a satellite
57
Query Decomposition
Exact Star-Shaped Groups
Groups of pattern combinations according to exactly
one common variable.
?o
(7) ?o
(8) ?o
(9) ?o
(10)?o
(6)
<http://evs.nci.nih.gov/ftp1/NDF-RT/NDF-RT.owl#UMLS_CUI> ?CUI .
<http://evs.nci.nih.gov/ftp1/NDF-RT/NDF-RT.owl#RxNorm_CUI> ?RN .
<http://evs.nci.nih.gov/ftp1/NDF-RT/NDF-RT.owl#SNOMED_CID> ?SM .
<http://evs.nci.nih.gov/ftp1/NDF-RT/NDF-RT.owl#MeSH_DUI> ?Ms .
<http://evs.nci.nih.gov/ftp1/NDF-RT/NDF-RT.owl#MeSH_Name> ?Mn.
58
Exact Star-Shaped Groups and satellites
Groups of one exact star-shaped group and
triples patterns
t={s p o}
Share one variable with a triple in the exact star
The rest of the triple components are constants.
(3) ?I1 drugbank:interactionDrug2 ?drug1 .
(4) ?I1 drugbank:interactionDrug1 ?drug .
(1) ?drug1 drugbank:drugCategory drugbankres:antibiotics .
59
Query Decomposer (3)
② Source selection
– Implements two heuristics: SSGM & SSGS
– SSGM: selects all the endpoints that can answer the ESSGs.
– SSGS: relevant endpoints are contacted to select only one per sub-goals.
60
• CD6 Query from FedBench
@PREFIX foaf:<http://xmlns.com/foaf/0.1/>
@PREFIX geonames:<http://www.geonames.org/ontology#>
@Jamendo
SWDF
SELECT ?name ?location WHERE {
DBpedia,
?artist foaf:name ?name .
Bibliographic
@LMDB ?artist foaf:based_near ?location .
SWDF ?location geonames:parentFeature ?germany .
?germany geonames:name 'Federal Republic of Germany’ .
}
@DBpedia
61
Query Decomposer (3)
② Source selection
– Implements two heuristics: SSGM & SSGS
– SSGM: selects all the endpoints that can answer the ESSGs.
Example of applying SSGM heuristic
@Jamendo
SWDF
DBpedia,
Bibliographic
– ✖
@DBpedia
@LMDB
SWDF
62
Query Decomposer (3)
② Source selection
– Implements two heuristics: SSGM & SSGS
– SSGM: selects all the endpoints that can answer the ESSGs
– SSGS: relevant endpoints are contacted to select only one per sub-goals.
Example of applying SSGM heuristic
Example of applying SSGS heuristic
@Jamendo
SWDF
DBpedia,
Bibliographic
@DBpedia
– ✖
@DBpedia
@SWDF
@LMDB
SWDF
63
Query Decomposer (3)
② Source selection
– Implements two heuristics: SSGM & SSGS
– SSGM: selects all the endpoints that can answer the ESSGs.
– SSGS: relevant endpoints are contacted to select only one per ESSG.
Example of applying SSGM heuristic
Example of applying SSGS heuristic
@Jamendo
SWDF
DBpedia,
Bibliographic
@DBpedia
– ✖
@DBpedia
Empty Answer
@SWDF
@LMDB
SWDF
64
Query Decomposer (4)
③ Filter pushdown
– Filters pushed to services reduce the amount of data transferred
and intermediate results
– If a filter expression contains variables that are resolved by
different sources, then the filter must be evaluated by the
mediator; else the filter is pushed to the service
Filter pushed
to service
Filter evaluated
in mediator
PREFIX foaf:<http://xmlns.com/foaf/0.1/>
SELECT * WHERE {
{SERVICE <http://service1/sparql>{
?x foaf:knows ?z .
FILTER REGEX(str(?x ), “Tim”)}}
{ SERVICE <http://service2/sparql>{
?y foaf:knows ?z .}}
FILTER (?x != ?y)}
65
Logical Optimizer
• Produces bushy tree plans:
– Reduce the size of intermediate results
– The height of the tree plan is minimized; this allows increasing
the parallelization of workload
• Greedy-based solution to build bushy trees:
– Leaves of the plan correspond to service blocks (Stars)
– Internal nodes correspond to logical operators to
combine the intermediate results accordingly
• Cartesian products are avoided and only placed at the
end, if no other operator can be used
66
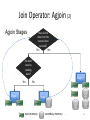
Join Operator: Agjoin
• Extension of the Symmetric Hash Join and Xjoin
When main memory gets full, a resource join tuple is selected as a victim and sent to secondary
memory.
67
Join Operator: Agjoin (2)
Agjoin Stages
Have all the
data from the
sources been
received?
No
Yes
Are both
sources
sending
data?
Stage 3
Yes
No
Stage 1
Stage 2
main memory
secondary memory
.
68
Join Operator: Agjoin (3)
Agjoin properties
No duplicates:
• Definition of timestamps
• Definition of conditions to detect tuples that have been
generated in previous stages
Completeness:
• All the results are produced by comparing tuples stored in
main memory
or secondary memory .
69
Other Operators
• Nested Loop Join
• Optional: Hash and nested loop
implementations, following the same
principles for join operators
Non-blocking
• Union
• Projection
• Distinct
• Limit and offset
• Filter: Able to process composed expressions
Blocking
• Order by
70
2
EMPIRICAL EVALUATION
71
Nine Virtuoso endpoints
9 Local SPARQL Endpoints
Timeout set up to 240 secs, or
71,000 tuples.
Queries
25 FedBech queries
CD, LD, LSD domains
3-6 Triple patterns
Ten additional complex queries
6-47 triple patterns
Metrics
Throughput
Percentage of the Answer (PA)
Federated Engines:
FedX [Schwarte et al 2011]
SPLENDID [Gorlitz and Staab
2011]
ANAPSID
Experimental Environment
Linux Mint machine. Intel Pentium
Core2 Duo 3.0 GHz.
8GB RAM.
72
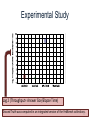
Experimental Study
Log 2 (Throughput= Answer Size/Elapse Time)
Ground Truth was computed in an integrated version of the FedBench collections.
73
Experimental Study
Existing Engines are
competitive in queries
comprise of small
number of triple
patterns.
ANAPSID query
optimization techniques
may overcome existing
Federated engines in
complex queries.
74
ANAPSID
75
Demo
http://silurian.thalassa.cbm.usb.ve/
Complex Query C9
Exclusive
Groups
Endpoints
SSGM
76
Team ANAPSID
Main contributors
Maribel Acosta
Query planning
contributors
Gabriela Montoya
Maria-Esther Vidal
Simón Castillo
77
Mining Linked Data
Allows to Identify Potential Novel
Discoveries
78
@Jamendo
SWDF
DBpedia,
Bibliographic
@DBpedia
@LMDB
SWDF
Semantic Data Management
Techniques are needed
79
Future Directions
Apply semEP to other domains, e.g., to predict drugdrug interactions or side effects.
Extension of existing engines to support specific tasks:
Source selection taking into account replicas, divergence
Graph traversal and mining.
Definition of benchmarks to study the performance and
quality of existing semantic data management techniques
Ensure reproducibility and generality of the results
Extensive empirical evaluation of the performance
and quality of existing engines and semantic data
management techniques
80
MANY THANKS!
QUESTIONS
81