Survey
* Your assessment is very important for improving the workof artificial intelligence, which forms the content of this project
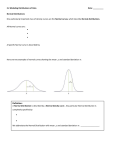
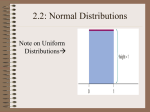
A density curve is similar to a histogram, but there are several important distinctions. 1. Obviously, a smooth curve is used to represent data rather than bars. However, a density curve describes the proportions of the observations that fall in each range rather than the actual number of observations. 2. The scale should be adjusted so that the total area under the curve is exactly 1. This represents the proportion 1 (or 100%). 3. While a histogram represents actual data (i.e., a sample set), a density curve represents an idealized sample or population distribution. (describes the proportion of the observations) 4. Always on or above the horizontal axis 5. We will still utilize mu m for mean and sigma s for standard deviation. Three points that have been previously made are especially relevant to density curves. 1. The median is the "equal areas" point. Likewise, the quartiles can be found by dividing the area under the curve into 4 equal parts. 2. The mean of the data is the "balancing" point. 3. The mean and median are the same for a symmetric density curve. We have mostly discussed right skewed, left skewed, and roughly symmetric distributions that look like this: Uniform Distributions Bi-modal Distributions Multi-modal Distributions Many other distributions exist, and some do not clearly fall under a certain label. Frequently these are the most interesting, and we will discuss them later. #1 RULE – ALWAYS MAKE A PICTURE It is the only way to see what is really going on! Curves that are symmetric, singlepeaked, and bell-shaped are often called normal curves and describe normal distributions. All normal distributions have the same overall shape. They may be "taller" or more spread out, but the idea is the same. The "control factors" are the mean μ and the standard deviation σ. Changing only μ will move the curve along the horizontal axis. The standard deviation σ controls the spread of the distribution. Remember that a large σ implies that the data is spread out. You can locate the mean μ by finding the middle of the distribution. Because it is symmetric, the mean is at the peak. The standard deviation σ can be found by locating the points where the graph changes curvature (inflection points). These points are located a distance σ from the mean. In a NORMAL DISTRIBUTIONS with mean μ and standard deviation σ: 68% of the observations are within σ of the mean μ. 95% of the observations are within 2 σ of the mean μ. 99.7% of the observations are within 3 σ of the mean μ. 1. They occur frequently in large data sets (all SAT scores), repeated measurements of the same quantity, and in biological populations (lengths of roaches). 2. They are often good approximations to chance outcomes (like coin flipping). 3. We can apply things we learn in studying normal distributions to other distributions. The distribution of heights of young women aged 18 to 24 is approximately normally distributed with mean m = 64.5 inches and standard deviation s = 2.5 inches. Where do the middle 95% of heights fall? What percent of the heights are above 69.5 inches? A height of 62 inches is what percentile? What percent of the heights are between 62 and 67 inches? What percent of heights are less than 57 in.? Suppose, on average, it takes you 20 minutes to drive to school, with a standard deviation of 2 minutes. Suppose a normal model is appropriate for the distribution of drivers times. › How often will you arrive at school in less than 20 minutes? › How often will it take you more than 24 minutes?