Survey
* Your assessment is very important for improving the workof artificial intelligence, which forms the content of this project
Yelp Dataset Project
TEAM #1:
NIENTZU KUAN
KATHY APPLEBAUM
Why Are Reviews Interesting?
We all use reviews to make decisions
Does the sentiment of the text match the rating?
Do reviews change over time?
Yelp Academic Dataset
A small subset of data made available for
research
10 cities in 4 countries
Over 2 million reviews and ½ million tips from ½
million users
https://www.yelp.com/dataset_challenge
The Data
Nested JSON format:
{ "yelping_since":"2004-10",
"votes":{
"funny":167,
"useful":280,
"cool":245
},
"review_count":108,
"name":"Russel",
"user_id":"18kPq7GPye-YQ3LyKyAZPw",
…
"friends":[ "rpOyqD_893cqmDAtJLbdog",
Data Preprocessing
Examine data structure
Design traditional SQL database
Write Java program to convert JSON into
multiple SQL tables
Data Warehouse
What questions can we answer?
Design schema to help us do that
Schema
• Snowflake schema
• Allows both data mart
and data mining
SQL Ninja
Athena is very slow
Adding an index made queries slower on
Athena
Question: Why is this?
Data Cube
Partially materialized data cube
Worst query went from 2.4
seconds to 0.01 seconds
Added little complexity to front
end
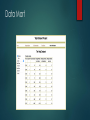
Data Mart
Data Mining
Does the subjective response of Yelp review text
match the star rating?
Conduct sentiment analysis and classification on
Yelp Academic Dataset text to help us do that.
Method
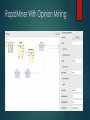
Used the data mining tool RapidMiner.
Utilized RapidMiner extension, Text Processing,
for statistical text analysis.
Applied Support Vector Machine to predict
whether the text is a positive or negative review.
Data Collection for Mining
Collected data for Mining from the MySQL
database created in our Data Warehouse part.
Executed several MySQL queries and stored
results in CSV format.
SELECT text FROM review WHERE stars=4 OR stars=5 Order by
Rand() LIMIT 20000 > pos_reviews.csv
SELECT text FROM review WHERE stars=1 OR stars=2 OR stars=3
Order by Rand() LIMIT 20000 > neg_reviews.csv
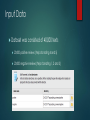
Input Data
Dataset was consisted of 40,000 texts
20,000 positive reviews (Yelp star rating 4 and 5)
20,000 negative reviews (Yelp star rating 1, 2 and 3)
Data Preprocessing for Mining
Used RapidMiner to perform data preprocessing
for classification.
RapidMiner With Opinion Mining
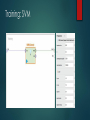
Training: SVM
Testing: 10-fold Cross Validation
The Result
Accuracy achieved is 84.46%
What is recall?
What is precision?
Conclusion
The result is satisfactory with an accuracy of
84.46% in predicting the Yelp star rating.
This means that 84 out of 100 Yelp text reviews are correctly
predicted as either rating 4/5 (positive review) or rating 1/2/3
(negative review).
Since the sentiment of Yelp text review
correlates to its star rating, users can trust the
Yelp rating system.
Data Mining Learning Experience
Difficulties encountered in learning the tool
which contained sentiment analysis support.
Issues with a large amount of data for training
and validation.
Tried a more aggressive goal to make it a
multiclass classification problem with no success.
Any Questions?