Survey
* Your assessment is very important for improving the workof artificial intelligence, which forms the content of this project
OLAP Over Uncertain and
Imprecise Data
Adapted from a talk by
T.S. Jayram (IBM Almaden)
with Doug Burdick (Wisconsin), Prasad Deshpande
(IBM), Raghu Ramakrishnan (Wisconsin), Shivakumar
Vaithyanathan (IBM)
Adapted by S. Sudarshan
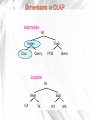
Dimensions in OLAP
Automobile
All
Truck
Sedan
Civic
Camry
F150
Sierra
Location
All
East
West
CA
TX
NY
MA
Measures, Facts, and Queries
Automobile
Auto = F150
Loc = NY
Repair = $200
ALL
Truck
Sedan
Civic
Camry
F150
MA
NY
East
p2
p1
Auto = Truck
Loc = East
SUM(Repair) = ?
Sierra
ALL
TX
West
Location
p7
p6
p8
p4
p5
CA
p3
Cell
Restriction on Imprecision
We restrict the sets of values in an imprecise fact to
either:
1. A singleton set consisting of a leaf level member of
the hierarchy, or,
2. The set of all the leaf level members under some
non-leaf level member of the hierarchy.
Cells and Regions
A region is a vector of attribute values from an
imprecise domains of each dimension of the cube.
A cell is a region in which all values are leaf level
members.
Let reg(R) represent the set of cells in a region R.
Queries on precise data
A query Q = (R, M, A) refers to a region R, a measure
M, and an aggregate function A. Eg : (<Ambassador,
Location>, Repairs, Sum)
The result of the query in a precise database is
obtained by applying A on the measure M of all cells in
R.
For the example above, the result is (P1 + P2)
Extend the OLAP model to handle data
ambiguity
Imprecision
Uncertainty
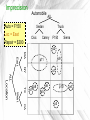
Imprecision
Auto = F150
Loc = East
Repair = $200
Automobile ALL
Truck
Sedan
Civic
Camry
F150
Sierra
p2
MA
East
p9
p11
NY
p1
ALL
TX
West
Location
p7
p6
p8
p10
p5
CA
p3
p4
Representing Imprecision using Dimension
Hierarchies
Dimension hierarchies lead to a natural space
of “partially specified” objects
Sources of imprecision: incomplete data,
multiple sources of data
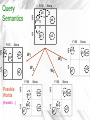
Motivating Example
Query: COUNT
Truck
F150
MA
p3
Sierra
p4
East
We propose desiderata
that enable
p5
appropriate definition of query
semantics for imprecise data
NY
p1
p2
Queries on imprecise data
Consider the query region <Pune, Model> in the figure.
It overlaps two imprecise facts P4 and P5.
Three (naive) options for including fact in query:
Contains: consider only if contained in query
Overlaps: consider if overlapping query
None: ignore all imprecise facts
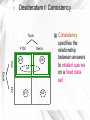
Desideratum I: Consistency
Truck
F150
Sierra
MA
p3
p4
p5
East
NY
p1
p2
Consistency
specifies the
relationship
between answers
to related queries
on a fixed data
set
Notions of Consistency
Generic idea: if query region is partitioned, and
aggregate applied on each partition, then aggregate q
on whole region must be consistent in some ways with
aggregates qi on partitions
General idea: alpha consistency for property alpha
Specific forms of consistency discussed in detail in
paper
Sum consistency (for count/sum)
Boundedness consistency (for average)
Contains option : Consistency
Intuitively, consistency means that the answer to a query
should be consistent with the aggregates from individual
partitions of the query.
Using the Contains option could give rise to inconsistent
results.
For example, consider the sum aggregate of the query above
and that of its individual cells. With the Contains option, will
the individual results add up to be the same as the collective?
Desideratum II: Faithfulness
Data Set 1
F150
Data Set 2
Sierra
p4
p5
p3
p4
p1
p2
F150
NY
p2
NY
NY
p1
Sierra
MA
p3
MA
MA
p5
F150
Data Set 3
Sierra
p5
p4
p3
p1
p2
Faithfulness specifies the relationship between
answers to a fixed query on related data sets
Notion of result quality relative to the quality of the data
input to the query.
–
For example, the answer computed for Q=F150,MA
should be of higher quality if p3 were precisely known.
Formal definitions of both Consistency and
Faithfulness depend on the underlying
aggregation operator
Can we define query semantics that satisfy
these desiderata?
F150
Query
Semantics
p5
MA
p4
p3
NY
F150
Sierra
p1
p2
F150
Sierra
p5
w1
p4
w2
p2
F150
p1
Sierra
p4
p2
F150
NY
p3
w3
MA
p5
NY
[Kripke63,…]
MA
Possible
Worlds
p3
p5 p4
w4
NY
NY
p1
MA
MA
p3
Sierra
Sierra
p5 p4
p3
p1
p2
p1
p2
Possible Worlds Query Semantics
Given all possible worlds together with their
probabilities, queries are easily answered
(using expected values)
But number of possible worlds is exponential!
Allocation
Allocation gives facts weighted assignments to
possible completions, leading to an extended
version of the data
Size increase is linear in number of (completions of)
imprecise facts
Queries operate over this extended version
Key contributions:
Appropriate characterization of the large space of
allocation policies
Designing efficient allocation policies that take into
account the correlations in the data
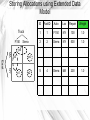
Storing Allocations using Extended Data
Model
Truck
F150
Sierra
MA
NY
East
ID
FactID
Auto
Loc
Repair
Weight
1
1
F150
NY
100
1.0
2
2
Sierra
NY
500
1.0
5
4
Sierra
MA
200
1.0
p5
p4
p3
p1
p2
Advantages of EDM
No extra infrastructure required for representing
imprecision
Efficient algorithms for aggregate queries :
SUM and COUNT : linear time algo.
AVERAGE : slightly complicated algorithm running in
O(m + n3) for m precise facts and n imprecise facts.
Aggregating Uncertain Measures
Opinion pooling: provide a consensus opinion from a
set of opinions Θ.
The opinions in Θ as well as the consensus opinion are
represented as pdfs over a discrete domain O
linear operator LinOp(Θ) produces a consensus pdf P that is a
weighted linear combination of the pdfs in Θ,
Allocation Policies
For every region r in the database, we want to assign
an allocation pc, r to each cell c in Reg(r), such that
∑c Reg(r) pc, r = 1
Three ways of doing so:
1. Uniform : Assign each cell c in a region r an equal
probability.
pc, r = 1 / |Reg(r)|
Allocation Policies
For every region r in the database, we want to assign
an allocation pc, r to each cell c in Reg(r), such that
∑c Reg(r) pc, r = 1
However, we can do better. Some cells may be
naturally inclined to have more probability than others.
Eg : Mumbai will clearly have more repairs than
Bhopal. We can do this automatically by giving more
probability to cells with higher number of precise facts.
2. Count based :
where Nc is the number of precise facts in cell c
Allocation Policies
For every region r in the database, we want to assign
an allocation pc, r to each cell c in Reg(r), such that
∑c Reg(r) pc, r = 1
Again, we can arguably get a better result by looking at
not just the count, but rather than the actual value of
the measure in question.
3. Measure based : next slide.
Measure Based Allocation
Assumes the following model :
The given database D with imprecise facts has been
generated by randomly injecting imprecision in a
precise database D'.
D' assigns value o to a cell c according to some
unknown pdf P(o, c).
If we could determine this pdf, the allocation is simply
pc, r = P(c) / ∑ c' in Reg(r) P(c')
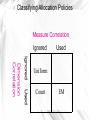
Classifying Allocation Policies
Measure Correlation
Ignored
Used
Ignored
Used
Dimension
Correlation
Uniform
Count
EM
Results on Query Semantics
Evaluating queries over extended version of
data yields expected value of the aggregation
operator over all possible worlds
intuitively, the correct value to compute
Efficient query evaluation algorithms for SUM,
COUNT
consistency and faithfulness for SUM, COUNT are
satisfied under appropriate conditions
Dynamic programming algorithm for AVERAGE
Unfortunately, consistency does not hold for
AVERAGE
Alternative Semantics for AVERAGE
APPROXIMATE AVERAGE
E[SUM] / E[COUNT] instead of E[SUM/COUNT]
simpler and more efficient
satisfies consistency
extends to aggregation operators for uncertain
measures
Maximum Likelihood Principle
A reasonable estimate for this function P can be that
which maximises the probability of generating the
given imprecise data set D.
Example :
Suppose the pdf depends only on the cells and is
independent of the measure values. Thus, the pdf is a
mapping : C where C is the set of cells.
This pdf can be found by maximising the likelihood
function :
( ) = r D ∑c Reg(r) (c)
EM Algorithm
The Expectation Maximization algorithm provides a
standard way of maximizing the likelihood, when we
have some unknown variables in the observation set.
Expectation step (compute data): Calculate the
expected value of the unknown variables, given the
current estimate of variables.
Maximization step (compute generator): Calculate the
distribution that maximizes the probability of the
current estimated data set.
EM Algorithm : Example
Initialization Step: Data: [4, 10, ?, ?] Initial mean value: 0
New Data: [4, 10, 0, 0]
Step 1: New Mean: 3.5
New Data:[4, 10, 3.5, 3.5]
Step 4: New Mean: 6.5625
New Data: [4, 10, 6.5625, 6.5625]
Step 2: New Mean: 5.25
New Data: [4, 10, 5.25, 5.25]
Step 5: New Mean: 6.7825
New Data: [4, 10, 6.7825, 6.7825]
Step 3: New Mean: 6.125
New Data: [4, 10, 6.125, 6.125]
Result: New Mean: 6.890625
EM Algorithm : Application
Experiments : Allocation run time
Experiments : Query run time
Experiments : Query run time
Experiments : Accuracy
Uncertainty
Measure value is modeled as a probability
distribution function over some base domain
e.g., measure Brake is a pdf over values {Yes,No}
sources of uncertainty: measures extracted from text
using classifiers
Adapt well-known concepts from statistics to
derive appropriate aggregation operators
Our framework and solutions for dealing with
imprecision also extend to uncertain measures
Summary
Consistency and faithfulness
desiderata for designing query semantics for
imprecise data
Allocation is the key to our framework
Efficient algorithms for aggregation operators
with appropriate guarantees of consistency
and faithfulness
Iterative algorithms for allocation policies
Correlation-based Allocation
Involves defining an objective function to capture
some underlying correlation structure
a more stringent requirement on the allocations
solving the resulting optimization problem yields the
allocations
EM-based iterative allocation policy
interesting highlight: allocations are re-scaled
iteratively by computing appropriate aggregations