Survey
* Your assessment is very important for improving the workof artificial intelligence, which forms the content of this project
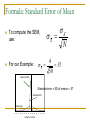
Probability Probability; Sampling Distribution of Mean, Standard Error of the Mean; Representativeness of the Sample Mean Probability – Frequency View Probability is long run relative frequency Same as relative frequency in the population Dice toss p(1) = p(2) = …=p(6) = 1/6 Coin flip p(Head) = p(Tail) = .5 Probability & Decision Making Decision making like gambling – go with what is likely. Lady tasting tea in England. Milk first or second? 5 cups of tea to taste. What is the probability she gets it right? If you cannot tell the difference, how likely will you be right on all cups? Cup Probability Correct 1 .5 ½ 2 .25 ½*½ 3 .125 ½*½*½ 4 .0625 ½*½*½*½ 5 .03125 ½*½*½*½*½ How many cups would it take to convince you? Convention in social science is a probability of .05. Using this standard, she would have to get all 5 right to be convincing in her ability. She did; they were. Frequency Distribution of the Mean What is the distribution of means if we roll dice once? What is the distribution of means if we roll dices twice and take the average? Three times? (See Excel File ‘dice’) Dice Raw Data 1 Die M = 3.5 SD = 1.87 Sampling Distributions of Means Ave of 2 Dice M = 3.5 SD = 1.23 Ave of 3 Dice M = 3.5 SD = .99 Notice the mean, standard deviation, and shape of the distributions. Sampling Distribution Notion of trials, experiments, replications Coin toss example (5 flips, # heads) Repeated estimation of the mean Sampling distribution is a distribution of a statistic (not raw data) over all possible samples. Same as distribution over infinite number of trials. Recall dice example. Estimator We use statistics to estimate parameters Most often X Suppose we want to estimate mean height of students at USF. Sample students, estimate M. Accuracy of estimate depends mostly upon N and SD. Example of Height Hypothetical data. RAW DATA Height of USF Students 66; 4 Relative Frequency 0.80 Note that graph shows the population. 0.64 0.48 0.32 0.16 0.00 50 52 54 56 58 60 62 64 66 68 70 72 74 76 78 80 82 Heignt in Inches Raw Data vs. Sampling Distribution Two Distributions Raw and Sampling 0.8 Relative Frequency Means (N=50) Note middle and spread of the two distributions. How do they compare? 0.6 0.4 0.2 Raw Data 0.0 50 52 54 56 58 60 62 64 66 68 70 Heignt in Inches 72 74 76 78 80 Definition of Bias Statisticians have worked out properties of sampling distributions Middle and spread of sampling distribution are known. If mean of sampling distribution equals parameter, statistic is unbiased. (otherwise, it’s biased.) The sample mean X is unbiased. Best estimate of is X . Definition of Standard Error The standard deviation of the sampling distribution is the standard error. For the mean, it indicates the average distance of the statistic from the parameter. Means (N=50) Standard error of the mean. Standard Error Raw Data 50 52 54 56 58 60 62 64 66 68 70 Heignt in Inches 72 74 76 78 80 Formula: Standard Error of Mean X To compute the SEM, use: X N 4 X .57 50 For our Example: Means (N=50) Standard error = SD of means = .57 Standard Error Raw Data 50 52 54 56 58 60 62 64 66 68 70 Heignt in Inches 72 74 76 78 80 Review What is a sampling distribution? What is bias? What is the standard error of a statistic? Suppose we repeatedly sampled 100 people at a time instead of 50 for height at USF. What would the mean of the sampling distribution? What would be the standard deviation of the sampling distribution? Definition A sampling distribution is a distribution of _____? 1 parameters 2 samples 3 statistics 4 variables Definition What is the standard error of the mean? 1 average distance of standard from the error 2 average distance of raw data (X) from the data average (X-bar) 3 square root of the sampling distribution of the variance 4 standard deviation of the sampling distribution of the mean Computation If the population mean is 50, the population standard deviation is 2, and the sample size is 100, what is the standard error of the mean? 1 .2 2 .5 3 2 4 10 Deciding whether a Sample represents a Population Representativeness: degree to which the sample distribution resembles the population distribution. z X X We can use the normal distribution to figure the probability of a sample mean. If the sample mean is very unlikely (has a low probability) we conclude the sample does not represent the population. If it is likely, we conclude it does. Suppose we grab a sample of 49 students and their mean GPA is 3.7. We know the population mean is 3.1 and the population SD is .35. Is the sample representative? .35 .35 X 3.7 3.2 .5 X .05 z 10 7 49 X .05 .05 Likely? Probability (Relative Frequency) z X X 3.9 3.2 .7 10 .05 .05 Standard Normal Curve 0 .4 50 Percent Area beyond 10 =? 0 .3 From z table: 34.13 % 0 .2 p = 7.69*10-23 0 .1 13.59% 2.15% 0 .0 -3 -2 -1 0 1 2 Scores in standard deviations from mu 3 Recall that anything beyond z = 2 is rare; anything beyond z = 3 is remote. Rejection Region Probability (Relative Frequency) Place in the curve that is unlikely if the scenario is true. Area totals to probability. Standard Normal Curve 0 .4 50 Percent 0 .3 34.13 % 0 .2 0 .1 13.59% 2.15% 0 .0 -3 -2 -1 0 1 2 3 Convention is p = .05; That 5 percent of the area least likely to occur if the scenario is true is the rejection region. In most cases, the extremes of both tails are the places for the rejection region. The sample is unrepresentative if it falls far from the center. For z, the border is +/- 1.96 for p = .05 for 2 tails. For 1 tail, it is 1.65. Scores in standard deviations from mu Bottom 2.5 pct Top 2.5 pct Review We know the population mean is 50 and the population standard deviation is 10. We grab 100 people at random and find the mean of the sample is 45. Does the sample represent the population?