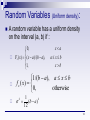Survey
* Your assessment is very important for improving the workof artificial intelligence, which forms the content of this project
Review of Probability
1
Probability Theory:
Many techniques in speech processing
require the manipulation of probabilities
and statistics.
The two principal application areas we will
encounter are:
Statistics
pattern recognition.
Modeling of linear systems.
2
Events:
It is customary to refer to the probability of
an event.
An event is a certain set of possible
outcomes of an experiment or trial.
Outcomes are assumed to be mutually
exclusive and, taken together, to cover all
possibilities.
3
Axioms of Probability:
To any event A we can assign a number,
P(A), which satisfies the following axioms:
P(A)≥0.
P(S)=1.
If
A and B are mutually exclusive, then
P(A+B)=P(A)+P(B).
The number P(A) is called the probability
of A.
4
Axioms of Probability (some consequence):
Some immediate consequence:
If
A is the complement of A, then
( A A) S
P( A ) 1 P( A)
P(ø) ,the probability of the impossible event,
P(A)
is 0.
≤ 1.
If two event A and B are not mutually
exclusive, we can show that
P(A+B)=P(A)+P(B)-P(AB).
5
Conditional Probability:
The conditional probability of an event A,
given that event B has occurred, is defined
P( AB)
as:
P( A | B)
P( B)
We can infer P(B|A) by means of Bayes’
theorem:
P( B)
P( B | A) P( A | B)
P( A)
6
Independence:
Events A and B may have nothing to do
with each other and they are said to be
independent.
Two events are independent if
P(AB)=P(A)P(B).
Independence -> mutually exclusive
Mutually exclusive +> independence
P( A | B) P( A)
From the definition of conditional
P( B | A) P( B)
probability:
P( A B) P( A) P( B) P( A) P( B)
7
Independence:
Three events A,B and C are independent
only if:
P( AB) P( A) P( B)
P( AC ) P( A) P(C )
P( BC ) P( B) P(C )
P( ABC ) P( A) P( B) P(C )
8
Random Variables:
A random variable is a number chosen at
random as the outcome of an experiment.
Random variable may be real or complex
and may be discrete or continuous.
In
S.P. ,the random variable encounter are
most often real and discrete.
We can characterize a random variable by
its probability distribution or by its
probability density function (pdf).
9
Random Variables (distribution function):
The distribution function for a random
variable y is the probability that y does not
exceed some value u,
Fy (u ) P( y u )
and
P(u y v) Fy (v) Fy (u )
10
Random Variables (probability density function):
The probability density function is the
derivative of the distribution:
d
f y (u ) Fy (u )
du
and,
v
P(u y v) f y ( y)dy
u
Fy () 1
f y ( y)dy 1
11
Random Variables (expected value):
We can also characterize a random
variable by its statistics.
The expected value of g(x) is written
E{g(x)} or <g(x)> and defined as
Continuous random variable:
g ( x) g ( x) f ( x)dx
Discrete random variable:
g ( x) g ( x) p( x)
x
12
Random Variables (moments):
The statistics of greatest interest are the
moment of p(x).
The kth moment of p(x) is the expected
k
value of x .
For a discrete random variable:
mk x x p( x)
k
k
x
13
Random Variables (mean & variance):
The first moment, m1,is the mean of x.
Continuous:
x xf ( x)dx
Discrete:
x x xp( x)
x
The second central moment, also known
as the variance of p(x), is given by
2 ( x x ) 2 p ( x)
x
m2 x 2
14
Random Variables …:
To estimate the statistics of a random
variable, we repeat the experiment which
generates the variable a large number of
times.
If
the experiment is run N times, then each
value x will occur Np(x) times, thus
1
ˆk
m
N
1
̂ x
N
N
k
x
i
i 1
N
x
i 1
i
15
Random Variables (Uniform density):
A random variable has a uniform density
on the interval (a, b) if :
0,
Fx ( x) ( x a) /(b a),
1,
xa
a xb
xb
1 /(b a), a x b
f x ( x)
otherwise
0,
1
(b a ) 2
12
2
16
Random Variables
(Gaussian density):
The gaussian, or normal, density function
is given by:
1
( x ) 2 / 2 2
n( x; , )
e
2
17
Random Variables (…Gaussian density):
The distribution function of a normal
variable is:
x
N ( x; , ) n(u; , )du
If we define error function as
erf ( x)
Thus,
1
2
x
e
u 2 / 2
du
1
x
N ( x; , ) erf (
)
18
Two Random Variables:
If two random variables x and y are to be
considered together, they can be described in
terms of their joint probability density f(x, y) or,
for discrete variables, p(x, y).
Two random variable are independent if
p ( x, y ) p ( x ) p ( y )
19
Two Random Variables(…Continue):
Given a function g(x, y), its expected
value is defined as:
Continuous: g ( x, y )
g ( x, y) f ( x, y)dxdy
Discrete:
g ( x, y ) g ( x, y ) p( x, y )
x, y
And joint moment for two discrete random variable is:
mij x y p( x, y )
i
j
x, y
20
Two Random Variables(…Continue):
Moments are estimated in practice by averaging
repeated measurements:
1 N i j
mˆ ij x y
N 1
A measure of the dependence of two random
variable is their correlation and the correlation of
two variable is their joint second moment:
m11 xy xyp( x, y )
x, y
21
Two Random Variables(…Continue):
The joint second central moment of x , y is
their covariance:
xy ( x x )( y y ) m11 x y
If x and y are independent then their covariance is zero.
The correlation coefficient of x and y is
their covariance normalized to their
standard deviations:
xy
rxy
x y
22
Two Random Variables(…Gaussian Random Variable):
Two random variables x and y are jointly
gaussian if their density function is :
n ( x, y )
1
2 x y
Where
x 2 2rxy y 2
1
exp
2
2
2
1 r 2
2(1 r ) x x y y
xy
rxy
x y
23
Two Random Variables(…Sum of Random Variable):
The expected value of the sum of two
random variables is :
x y x y
This is true whether x and y are independent or not
And
also we have :
cx c x
x
i
i
xi
i
24
Two Random Variables(…Sum of Random Variable):
The variance of the sum of the two independent
random variable is :
2
x y
2
x
2
y
If two random variable are independent, the
probability density of their sum is the convolution
of the densities of the individual variables :
Continuous:
Discrete:
f x y ( z) f x (u) f y ( z u)du
px y ( z)
p (u) p ( z u)
u
x
y
25
Central Limit Theorem
Central Limit Theorem (informal
paraphrase):
If many independent random variable are
summed, the probability density function
(pdf) of the sum tends toward the gaussian
density, no matter what their individual
densities are.
26
Multivariate Normal Density
The normal density function can be generalized
to any number of random variables.
Let
x be the random vector,
Col[ X 1 , X 2 ,..., X n ]
1
n / 2
1
N ( x) (2 )
| R | exp Q( x x )
2
Where
1
Q( x x ) ( x x ) R ( x x )
T
The
matrix R is the covariance matrix of x
(R is Positive-Definite)
R ( x x )( x x )
T
27
Random Functions :
A random function is one arising as the
outcome of an experiment.
Random function need not necessarily be
functions of time, but in all case of interest
to us they will be.
A discrete stochastic process is
characterized by many probability density
of the form,
p( x1 , x2 , x3 ,..., xn , t1 , t2 , t3 ,..., tn )
28
Random Functions :
If the individual values of the random
signal are independent, then
p( x1 , x2 ,..., xn , t1 , t2 ,..., tn ) p( x1 , t1 ) p( x2 , t2 )... p( xn , tn )
If these individual probability densities are
all the same, then we have a sequence of
independent, identically distributed
samples (i.i.d.).
29
mean & autocorrelation
The mean is the expected value of x(t) :
x (t ) x(t ) xp( x, t )
x
The autocorrelation function is the
expected value of the product x(t1 ) x(t2 ) :
r (t1 , t2 ) x(t1 ) x(t2 ) x1 x2 p( x1 , x2 ,t1 , t2 )
x1 , x2
30
ensemble & time average
Mean and autocorrelation can be determined in
two ways:
The experiment can be repeated many times
and the average taken over all these
functions. Such an average is called
ensemble average.
Take any one of these function as being
representative of the ensemble and find the
average from a number of samples of this one
function. This is called a time average.
31
ergodic & stationary
If the time average and ensemble average
of a random function are the same, it is
said to be ergodic.
A random function is said to be stationary
if its statistics do not change as a function
of time.
Any ergodic function is also stationary.
32
ergodic & stationary
In stationary signal we have:
x (t ) x
p( x1, x2 , t1, t2 ) p( x1, x2 , )
Where
t2 t1
And the autocorrelation function is :
r ( ) x1 x2 p( x1 , x2 , )
x1 , x2
33
ergodic & stationary
When x(t) is ergodic, its mean and
autocorrelation is :
1 N
x lim
x(t )
N 2 N
t N
N
1
r ( ) x(t ) x(t ) lim
x(t ) x(t )
N N
t N
34
cross-correlation
The cross correlation of two ergodic
random functions is :
1
rxy ( ) x(t ) y (t ) lim
N N
N
x(t ) y(t )
t N
The subscript xy indicates a cross-correlation.
35
Random Functions (power & cross spectral density):
The Fourier transform of r ( ) (the
autocorrelation function of an ergodic
random function) is called the power
spectral density of x(t) :
S ( ) r ( )e j
The cross-spectral density of two ergodic
random function is :
S xy ( )
r
xy
( )e
j
36
Random Functions (…power density):
For ergodic signal x(t), r ( ) can be written
as:
r ( ) x( ) x( )
Then
from elementary Fourier transform properties,
S ( ) X ( ) X ( )
X ( ) X ( )
| X ( ) |
2
37
Random Functions (White Noise):
If all values of a random signal are
uncorrelated,
2
r ( ) ( )
Then
this random function is called white noise
The power spectrum of white noise is constant,
S ( ) 2
White noise is mixture of all frequencies.
38
Random Signal in Linear Systems :
Let T[ ] represent the linear operation; then
T [ x(t )] T [ x(t ) ]
Given a system with impulse response h(n),
y(n) x(n) h(n) x(n) h(n)
A stationary signal applied to a linear system
yields a stationary output,
ryy ( ) rxx ( ) h( ) h( )
S yy () S xx () | H () |
2
39