Survey
* Your assessment is very important for improving the workof artificial intelligence, which forms the content of this project
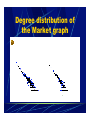
Data Mining and Knowledge Discovery in Dynamic Networks Panos M. Pardalos Center for Applied Optimization Dept. of Industrial & Systems Engineering Affiliated Faculty of: Computer & Information Science & Engineering Department Biomedical Engineering Program, McKnight Brain Institute Massive Datasets The proliferation of massive datasets brings with it a series of special computational challenges. This data avalanche arises in a wide range of scientific and commercial applications. With advances in computer and information technologies, many of these challenges are beginning to be addressed. (Abello, Pardalos & Resende, 2002, Handbook of Massive Datasets) Knowledge Discovery in Databases (KDD) KDD is the process of identifying valid, novel, potentially useful, and ultimately understandable structure (models and patterns) in the data Understand the application domain Create a target dataset Remove (or correct) corrupted data Apply data-reduction algorithms Apply data mining algorithms Interpret the mined patterns Graph Representation of Massive Datasets In many cases, it is convenient to represent a dataset as a graph (network) with certain attributes associated with its vertices and edges Studying the properties of these graphs often provides useful information about the internal structure of the datasets they represent Important Concepts A graph G = (V, E), V = set of vertices, E = set of edges Degrees of the vertices, degree distribution Size of connected components Edge density Cliques and independent sets Example of a graph 1 2 3 4 5 Examples of Real-Life Massive Graphs Web graph (links between websites) Call graph (telephone traffic data) Market graph (stock prices data) Brain networks (neurons and connections between them) Degree Distribution: Power Law Degree distribution of a graph characterizes global statistical patterns underlying the dataset this graph represents Interestingly, the degree distribution of all considered real-life graphs has a well-defined power-law structure: The probability that a vertex has a degree k (i.e., k neighbors) is or (“Self-organized” networks) Cliques and Independent Sets A clique is a subgraph of G that has all possible edges Cliques represent dense clusters of “similar” objects An independent set is a subgraph of G with no edges. Independent sets represent groups of “different” objects Maximum Clique and Independent Set Problems The subject of a special interest is to find the maximum clique and independent set in the graph Maximum clique and maximum independent set problems can be transformed to each other, using the notion of complementary graph These problems are NP-hard Finding cliques and independent sets Heuristic algorithms (no guarantee to find an optimal solution) Exact algorithms (finding maximum clique or independent set) Clique Partitioning Minimum clique partition: dividing the graph into a minimum number of distinct cliques This provides a natural way of partitioning a dataset represented by a graph into a number of clusters of “similar” objects (clustering problem), where the number of clusters is the minimum number of cliques in the graph Graph Coloring Coloring essentially represents the partitioning of the graph into a minimum number of independent sets Partitioning a dataset represented by a graph into a number of clusters of “different” objects Call Graph The “call graph” comes from telecommunications traffic. The vertices of this graph are telephone numbers, and the edges are calls made from one number to another (including additional billing data, such as, the time of the call and its duration). The challenge in studying call graphs is that they are massive. Every day AT & T handles approximately 300 million long-distance calls. (American Scientist Online, Jan- Feb 2000) Careful analysis of the call graph could help with infrastructure planning, customer classification and marketing. How can we visualize such massive graphs? To flash a terabyte of data on a 1000x1000 screen, you need to cram a megabyte of data into each pixel! Call Graph In our experiments with data from telecommunication traffic, in an instance of the corresponding multigraph has 53,767,087 vertices and over 170 million of edges. It is a not a connected graph, but has 3.7 million separate components, yet a giant connected component with 44,989,297 vertices was computed. The maximum (quasi)-clique problem is considered in this giant component. We found cliques of size 30 and there were more than 14000 of these 30member cliques (Abello, Pardalos & Resende) Call graph Call Graph In a battlefield situation, just counting the messages or identifying the source and the intended recipient of each message, constructing a call graph, yields valuable information like the organization of a military force. The records in the call database are collected for commercial purposes. In order to send an itemized bill, a phone company needs to keep track of every call completed, with the originating and receiving phone numbers and the starting and ending times. The largest companies handle roughly 250 million toll calls a day, and so a month's worth of data amounts to several billion call records. AT&T reports that its database of retained records is approaching two trillion calls and more than 300 terabytes of data. Call Graph Historical calling patterns can be used to detect fraud, and some patterns are also of interest in marketing. For example, a company that offers a discounted rate within a "calling circle" can use information from the call graph to estimate the costs and benefits of the program. This kind of traffic data could be compiled for other communications channels. For instance, Federal Express and other courier services keep digitized records of their deliveries, which could readily be transformed into a database of senders and receivers. With a ‘packet sniffer’ installed in the network, we compile this data for the e-mail traffic. (American Scientist Online, Sep-Oct 2006) Degree Distribution of the Call Graph (data by AT&T) Market Graph Vertices are stocks, and an edge connects two stocks if the correlation between their price fluctuations over a certain period is greater than a specified threshold ~6000 vertices (stocks) Market Graph Market graph (all the considered instances for different correlation thresholds) follows the power-law model Using the combination of heuristic and exact algorithms, the exact solution of the maximum clique problem was found (Boginski, Butenko & Pardalos) Degree distribution of the Market graph Finding Cliques in the Market Graph Applying a heuristic algorithm to find a large clique: let N(i) be the set of neighbors of the vertex i Finding Cliques in the Market graph Preprocessing procedure: C is the clique found by the heuristic algorithm: recursively remove from the graph all of the vertices which are not in C and whose degree is less than |C| Denote the resulting (reduced) graph as G’ = (V’, E’) Finding Cliques in the Market graph Using the IP formulation of the maximum clique problem to find the exact solution: Maximum Clique size for different correlation thresholds Large cliques despite very low edge density – confirms the idea about the “globalization” of the market Classification of Stocks Using Clique Partitioning A clique in the market graph represents a dense cluster of stocks whose prices exhibit a similar behavior over time Therefore, dividing the market graph into a set of distinct cliques (clique partitioning) is a natural approach to classifying stocks (dividing the set of stocks into clusters of similar objects – an approach to solving the clustering problem) Independent sets in the Market graph Maximum independent set represents the largest “perfectly diversified” portfolio Solving the maximum clique problem in the complementary graph The preprocessing procedure could not reduce the size of the initial graph, the exact solution could not be found Large diversified portfolios are hard to find Independent set sizes for different correlation thresholds Relatively small independent sets found by the heuristic algorithm Independent Sets in the Market Graph Finding a perfectly diversified portfolio containing any given stock For every vertex in the market graph, an independent set that contains this vertex was detected, and the sizes of these independent sets were almost the same, which means that it is possible to find a diversified portfolio containing any given stock using the market graph methodology Maximum Clique size for different correlation thresholds Maximum clique size for various thresholds in Food Market Graph Independent Sets in the Market Graph Maximum independent set size for various thresholds in Food Market Graph Connected Components in Market Graph Intuition Two nodes are correlated if their correspondent nodes are connected by edge (correlated) Power-law graphs generally have very high clustering coefficient i.e., the tendency for association of two nodes which are associated with a common node is high Connected Components in Market Graph Largest Group size by Time Period Group Size by Time period - (0.6) 500 200 400 Largest group size 250 150 100 50 300 200 100 0 0 1 2 3 4 5 6 7 8 9 10 1 11 2 3 4 5 6 Tim e Period Tim e Period Group Size by Time Period - (0.5) 1,400 1,200 Largest group size Largest Group Size Group Size by Time Period - (0.7) 1,000 800 600 400 200 0 1 2 3 4 5 6 Tim e Period 7 8 9 10 11 7 8 9 10 11 Connected Components in Market Graph Observations The increase in the giant component size from oldest to newest time period indicates the globalization tendency, just as in maximum clique size and edge density The giant components includes semiconductor industries and the increase in the size of the giant components corroborates the observation that the number of these industries has been increasing with time Additional Applications Social Networks Biological Networks Transportation Networks (place of living and place of work) References J. Abello, P.M. Pardalos, and M.G.C. Resende (eds.), 2002. Handbook of Massive Data Sets, Kluwer Academic Publishers. V. Boginski, S. Butenko, and P.M. Pardalos, 2003. Modeling and Optimization in Massive Graphs. In: P. M. Pardalos and H. Wolkowicz, eds. Novel Approaches to Hard Discrete Optimization, American Mathematical Society, 17-39. V. Boginski, S. Butenko, and P.M. Pardalos, 2003. On Structural Properties of the Market Graph. In: A. Nagurney (editor), Innovations in Financial and Economic Networks, Edward Elgar Publishers, 28-45. References American Scientist Online, (Jan-Feb 2000), Computing Science Graph Theory in Practice: Part I by Brian Hayes, Volume 88, No. 1 American Scientist Online, (Sep-Oct 2006), Connecting the Dots: Can the tools of graph theory and social-network studies unravel the next big plot? , Volume 94, No. 5 Modeling Epileptic Brain EEG recordings received from the electrodes located in different functional units of the brain (time series) The values of T-index between all pairs of electrodes are calculated Two electrodes are considered to be entrained in the seizure if the corresponding value of T-index is less than Tcritical. Modeling Epileptic Brain One can represent all the electrode locations (functional units of the brain) as the vertices of the graph. An edge connects two vertices if the corresponding value of T-index is less than Tcritical, i.e. these electrode sites are entrained at a certain time moment. The evolution of the properties of this graph is investigated Modeling Epileptic Brain Edge density of the considered graph (dashed lines represent the moments of epileptic seizures) Modeling Epileptic Brain Size of the largest connected component (dashed lines represent the moments of epileptic seizures) Modeling Epileptic Brain: Related Technique Let A be the matrix containing the values of T-index Tij for all pairs of electrodes Solve the quadratic 0-1 problem to find k electrode sites producing the minimal sum of T-indices (so-called critical sites), which means that these sites are entrained during the seizure Summary There are many mathematical programming techniques for addressing data mining problems in dynamic networks Graph-based techniques for this type of problems is a promising research area Performance of any approach depends on a specific dataset – there is no “universal” technique References Data Mining in Biomedicine, P.M. Pardalos, V. Boginski, and A. Vazacopoulos (eds.), Springer, forthcoming. P.M. Pardalos, W. Chaovalitwongse, L.D. Iasemidis, J.C. Sackellares, D.-S. Shiau, P.R. Carney, O.A. Prokopyev, V.A. Yatsenko, 2004. Seizure Warning Algorithm Based on Optimization and Nonlinear Dynamics, Mathematical Programming, 101(2): 365-385. O.A. Prokopyev, V. Boginski, W. Chaovalitwongse, P. M. Pardalos, J. C. Sackellares, and P. R. Carney, 2004. Network-Based Techniques in EEG Data Analysis and Epileptic Brain Modeling. To appear in: Data mining in Biomedicine, P.M. Pardalos, V. Boginski and A. Vazacopoulos (eds.), Springer. This cosmos was not made by Gods or men, but always was, and is, and ever shall be ever-living fire. Heraclitus - The Fire Priest (540 BC 480 BC)

























































![[20]). [15), [2), [9], [6], [7], [17], [22], [11], and [19](http://s1.studyres.com/store/data/015168138_1-1cf55c354606a20fb5bb2deafae2d3c8-150x150.png)






