Survey
* Your assessment is very important for improving the workof artificial intelligence, which forms the content of this project
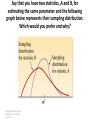
Sta220 - Statistics Mr. Smith Room 310 Class #14 Section 4.6 and 4.8 Section 4.6 We learn how to make inferences about the population on the basis of information contained in the sample. Several of these techniques are based on the assumption that the population is approximately normally distributed. It will be important to determine whether the sample of data come from a normal population before we can apply these techniques properly. Procedure Copyright © 2013 Pearson Education, Inc.. All rights reserved. Definition Copyright © 2013 Pearson Education, Inc.. All rights reserved. Example 4.24 The EPA mileage ratings on 100 cars are reproduced in the following table. Numerical and graphical descriptive measures for the data are shown on the StatCrunch and SPSS printouts presented in Figure 4.26. Determine whether the EPA mileage ratings are from an approximate normal distribution. Table 4.6 Copyright © 2013 Pearson Education, Inc.. All rights reserved. Summary statistics: Column MPG n Mean 100 Variance Std. dev. Std. err. Median 36.994 5.84622 2.41789 0.24178 63 71 971 37 Range 14.9 Min 30 Max 44.9 Q1 Q3 35.65 38.35 #1: Histogram or Stem-and-leaf Display • Clearly, the mileages fall into an approximately mound shaped, symmetric distribution centered around the mean of about 37 mpg. • Therefore, check #1 in the box indicates that the data are approximately normal. #2: Compute the Intervals • We obtain 𝑥= 37 and s = 2.4 from the summary from StatCrunch. The intervals are shown in Table 5.3 as is the percentage of mileage ratings that fall into each interval. • These percentages agree almost exactly with those from a normal distribution. #3: Ratio IQR/s • From the Summary Statistics, the 25th percentile (labeled Q1) is 𝑄𝐿 = 35.65 and 75th percentile (labeled Q3)is 𝑄𝑈 = 38.35. • Then IQR = 2.7 and the ratio is 𝐼𝑄𝑅 2.7 = = 1.13 𝑠 2.4 • Since the value is approximately equal to 1.3, we have further confirmation that the data are approximately normal. SPSS normal probability plot for gas mileage data Copyright © 2013 Pearson Education, Inc.. All rights reserved. • An SPSS normal probability plot of the mileage data is shown in Figure 4.26. • Notice that the ordered mileage values fall reasonably close to a straight line when plotted against the expected values from a normal distribution. • These suggest that EPA mileage data are approximately normally distributed. Conclusion The checks for normality are simple, yet powerful, techniques to apply, but they are only descriptive in nature. Thus, we should be careful not to claim that the 100 EPA mileage ratings are, in fact, normally distributed. We can only stat that it is reasonable to believe that the data are from a normal distribution. Section 4.8 In previous sections, we assumed that we knew the probability distribution of a random variable, and using this knowledge, we were able to compute the mean, variance, and probabilities associated with the random variable. However, in most practical applications, the true mean and standard deviation are unknown quantities that have to be estimated. Definition Copyright © 2013 Pearson Education, Inc.. All rights reserved. We will often use the information contained in these sample statistics to make inferences about the parameters of a population. Table 4.8 • Note that the term statistic refers to sample quantity and the term parameter refers to a population quantity. Copyright © 2013 Pearson Education, Inc.. All rights reserved. Before being able to use the sample statistics to make inferences about population parameters, we need to be able to evaluate their properties. Does one sample statistic contain more information than another about a population parameter? On what basis should we choose the ‘best’ statistic for making inferences about a parameter? For example, if we wanted to estimate a parameter of a population– say, the population mean 𝜇 – we can use a number of sample statistics for our estimate. Two possibilities are the sample mean 𝑥 and the sample Median M. Which of these do you think will provide a better estimate of 𝜇? Lets consider the following example: Toss a fair die and let x equal the number of dots showing on the up face. Suppose the die is tossed three times, producing the sample measurements 2, 2, 6. The sample mean is 𝑥 = 3.33, and the sample median is M = 2. Since the population mean is 𝜇 = 3.5, you can see that, for this sample of three measurements, the sample mean 𝑥 provides an estimate that falls closer to 𝜇 than does the sample median M. Now suppose we toss the die three more times and obtain the sample measurements 3, 4, 6. Then the mean and median of this ample are 𝑥 = 4.33 and M = 4, respectively. This time M is closer to 𝜇. This illustrates an important point: Neither the sample mean or the sample median will always fall closer to the population mean. We cannot compare these two sample statistics or , in general, any two sample statistics on the basis of their performance with a single sample. We recognize that sample statistics are themselves random variables, because different samples can lead to different values for a sample statistics. Last, as random variables, sample statistics must be judged and compared on the basis of their probability distribution. This means the collection of values and associated probabilities of each statistics that would be obtained if the sampling experiment were repeated a VERY LARGE NUMBER OF TIME. Definition Copyright © 2013 Pearson Education, Inc.. All rights reserved. In actual practice, the sampling distribution of statistic is obtained mathematically or (at least approximately) by simulating the sample on a computer, using a procedure similar to that just described. Say that you have two statistics, A and B, for estimating the same parameter and the following graph below represents their sampling distribution. Which would you prefer and why? Copyright © 2013 Pearson Education, Inc.. All rights reserved. Remember that, in practice, we will not know the numerical value of the unknown parameter 𝜎 2 , so we will not know whether statistic A or statistic B is closer to 𝜎 2 for a particular sample. Example 4.26 Consider the popular casino game of craps, in which a player throws two dice and bets on the outcome (the sum total of the dots showing on the upper faces of the two dice). Let’s say that if the sum total of the die is 7 or 11, the roller wins $5; if the total is 2, 3, or 12, the roller loses $5; and for any other total (4, 5, 6, 8, 8, 9, or 10) no money is lost or won on the roll. Let x represent the result of the come-out roll wager (-$5, $0, or +$5). The following table is the actual probability distribution of x is: Outcome of Wager, x -5 0 5 p(x) 1/9 6/9 2/9 Now, consider a random sample of n = 3 comeout rolls. a. Find the sampling distribution of the same mean, 𝑥 b. Find the sampling distribution of the same median, M. c. Then use the sampling distribution for 𝑥 to find the expected value of 𝑥. Table 6.2 Copyright © 2013 Pearson Education, Inc.. All rights reserved. a. From the table, you can see that 𝑥 can assume the values -5, -3.33, -1.67, 0, 1.67, 3.33 and 5. Because 𝑥 = -5 occurs in one sample, P(𝑥 = -5) = 1/729 ≈ .0014. Calculating the probabilities of the remaining values of 𝑥 and arranging them in a table, we obtain the following probability distribution. 𝑥 p(𝑥) -5 -3.33 1/729 ≈ 18/729 .0014 ≈.0247 -1.67 0 1.67 3.33 114/729 288/729 228/729 72/729 ≈.1564 ≈.3951 ≈.3127 ≈.0988 5 8/729 ≈.0110 This is the sampling distribution for 𝑥 because it specifies the probability associated with each possible value of 𝑥. You can see that the mostly likely mean outcome after 3 randomly s3lected come-out rolls is 𝑥 = $0; this result occurs with probability .3951 b. From the table, you can see that 𝑀 can assume the values -5, -0, and 5. Because 𝑀 = -5 occurs in seven samples, P(M= -5) = 25/729 ≈ .0343. Calculating the probabilities of the remaining values of 𝑀 and arranging them in a table, we obtain the following probability distribution. 𝑥 p(𝑥) -5 0 5 25/729 ≈ .0343 612/729≈ 92/729 .8395 ≈.1262 Once again, the most likely median outcome after 3 randomly selected come-out rolls M = $0, a result that occurs with probability .8395. c. The expected value E(𝑥) = . 5558 Though the following example demonstrates the procedure for finding the exact sampling distribution of a statistic when the number of different samples that could be selected from the population is relative small. In the real world, populations often consist of large number of different values, making samples difficult to count. When this occurs, we choose to obtain the approximate sampling distribution for a statistic by simulating the sampling over and over again and recording the proportion of times different values of the statistic occur. 4.8 Homework due Wednesday 4.9 Notes on Monday Chapter 4 Test Next Thursday